Recurrent Neural Networks (RNNs) sind neben den Feedforward Netzwerken und den Convolutional Neural Networks die dritte große Art von Neuronalen Netzwerken. Sie werden bei Zeitreihendaten und sequenziellen Informationen eingesetzt, also Daten bei denen der vorangegangene Datenpunkt einen Einfluss auf den aktuellen hat. Diese Netzwerke enthalten mindestens eine Schicht, die rückgekoppelt ist. Was das bedeutet, schauen wir uns in diesem Beitrag genauer an.
Was sind Recurrent Neural Networks?
Um verstehen zu können, wie Recurrent Neural Networks funktionieren, müssen wir uns nochmal vor Augen führen, wie normale Feedforward Neuronale Netze aufgebaut sind. In diesen ist ein Neuron der Hidden Layer jeweils mit den Neuronen aus der vorherigen Schicht und den Neuronen aus der folgenden Schicht verbunden. Der Output eines Neurons kann in einem solchen Netzwerk immer nur nach vorne weitergereicht werden, jedoch niemals an ein Neuron auf derselben Schicht oder sogar der vorherigen Schicht, daher auch der Name “Feedforward”.
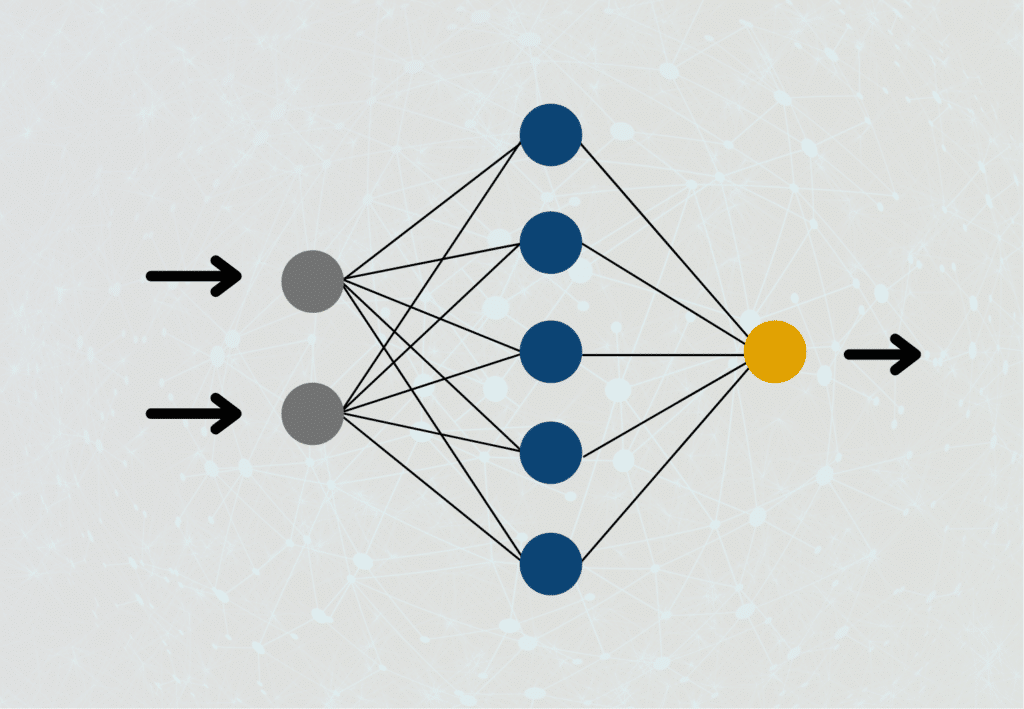
Bei Rekurrenten Neuronalen Netzwerken ist das anders. Der Output eines Neurons kann dort sehr wohl als Input einer vorherigen Schicht oder der aktuellen Schicht genutzt werden. Das kommt tatsächlich auch der Funktionsweise unseres Gehirns nochmal deutlich näher, als die Art und Weise, wie Feedforward Neuronale Netze aufgebaut sind. In vielen Anwendungen benötigen wir auch ein Verständnis für unmittelbar davor berechnete Schritte, um das Gesamtergebnis zu verbessern.
Welche Anwendungen haben RNNs?
Recurrent Neural Networks kommen vor allem bei der maschinellen Sprachverarbeitung oder bei Zeitreihendaten zum Einsatz, also dann wenn die Informationen aus der unmittelbaren Vergangenheit eine große Rolle spielen. Bei dem Übersetzen von Texten sollten wir auch die davor verarbeitete Sequenz von Worten im “Gedächtnis” des Neuronalen Netzes behalten, anstatt nur Wort für Wort unabhängig voneinander zu übersetzen.
Sobald wir ein Sprichwort oder eine Redewendung in dem zu übersetzenden Text haben, müssen wir auch die vorangegangen Worte mit bei der Übersetzung beachten, da wir nur so erkennen können, dass es sich um ein Sprichwort handelt. Werden die Anwendungen in der Sprachverarbeitung komplexer, ist der Kontext von noch größerer Bedeutung. Beispielsweise dann, wenn wir über einen Text hinweg Informationen über eine bestimmte Person sammeln wollen.
Welche Arten von RNNs gibt es?
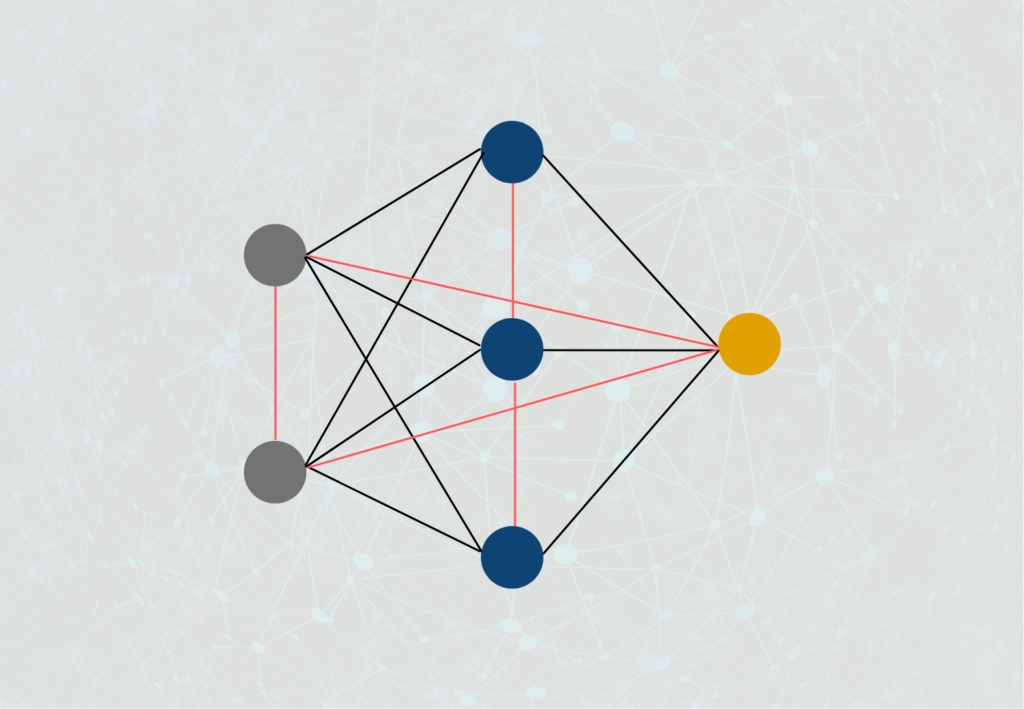
Je nachdem wie weit der Output eines Neurons innerhalb des Netzwerkes zurückgereicht wird, unterscheiden wir insgesamt vier verschiedene Typen von Rekurrenten Neuronalen Netzwerken:
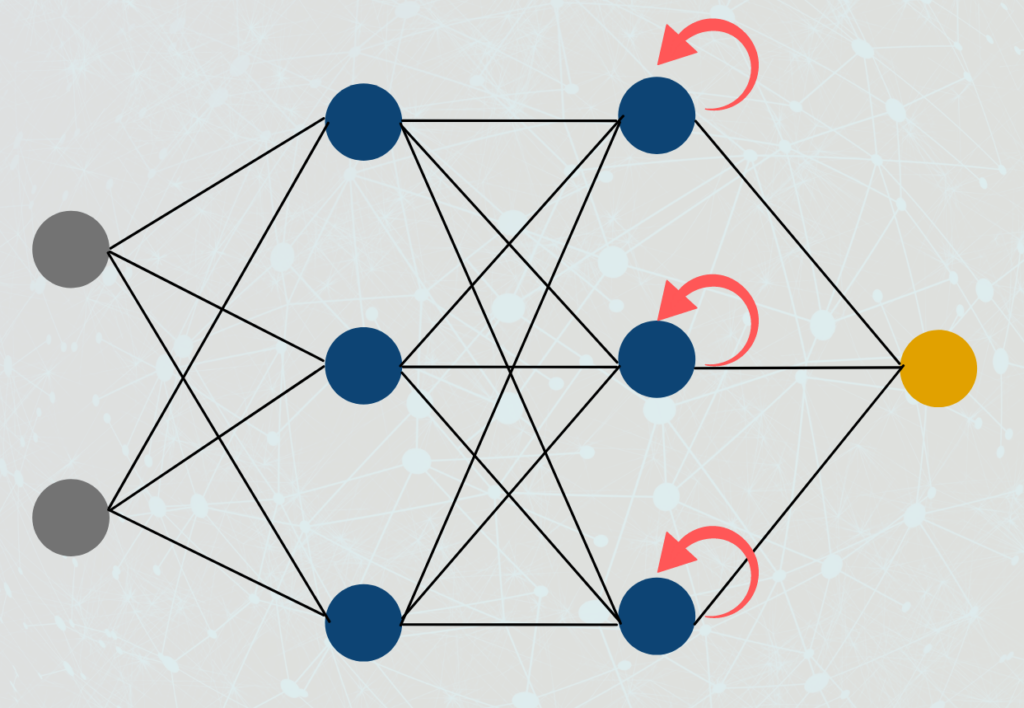
- Direkte Rückkopplung (Direct-Feedback-Network): Der Ausgang eines Neurons wird als Eingang desselben Neurons verwendet.
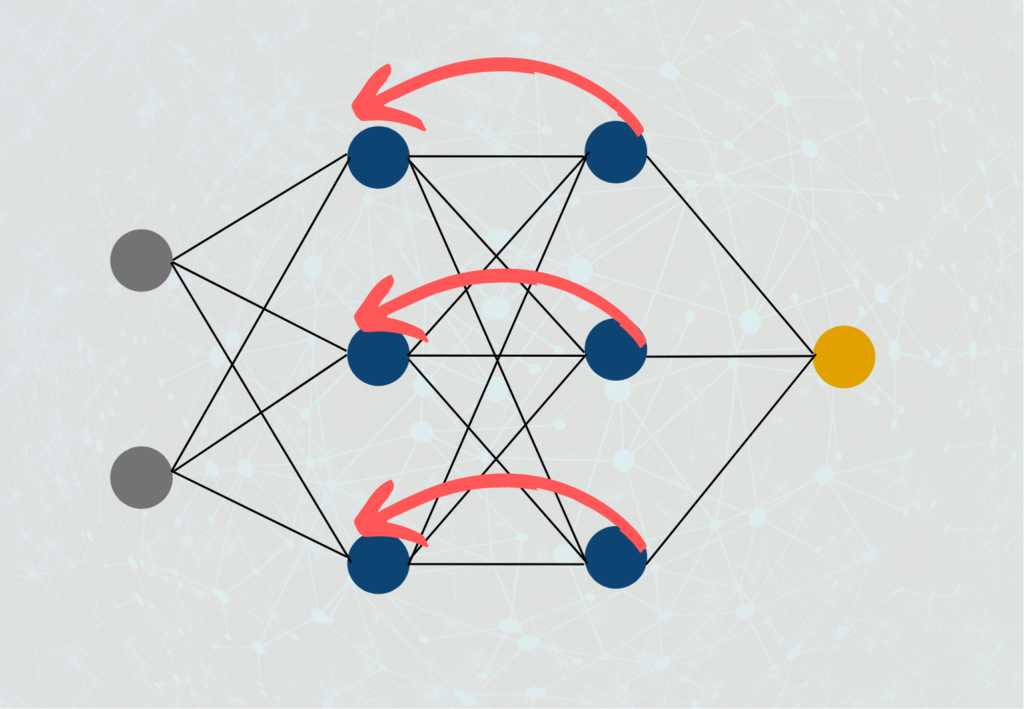
2. Indirekte Rückkopplung (Indirect-Feedback-Network): Der Output eines Neurons wird als Input in einer der vorangegangenen Schichten genutzt.
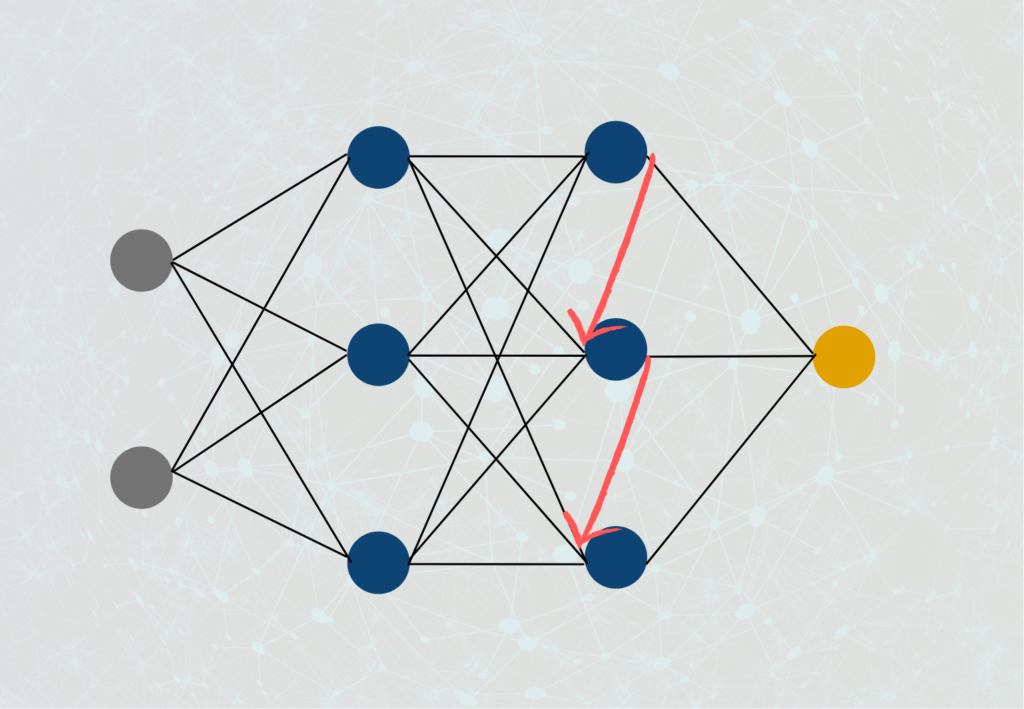
3. Seitliche Rückkopplung (Lateral-Feedback-Network): Hier wird der Ausgang eines Neurons mit dem Eingang eines Neurons derselben Schicht verbunden.
4. Vollständige Rückkopplung (Complete-Feedback-Network): Der Ausgang eines Neurons hat Verbindungen zu den Eingängen aller (!) Neuronen im Netzwerk, egal ob in derselben Schicht, einer vorangegangenen oder einer nachfolgenden Schicht.
Wie trainiert man Recurrent Neural Networks?
Das Training von Recurren Neural Networks ist vergleichbar mit dem Training anderer neuronaler Netze. Neben der Datenvorverarbeitung spielt dabei auch die Initialisierung des Netzes eine wichtige Rolle bei der die Anzahl under Aufbau der Schichten gewählt wird. Im Vergleich zu herkömmlichen Feedforward Netzen spielt dabei noch die Art der RNN – Zellen eine entscheidende Rolle, die weiter oben in diesem Artikel beschrieben wurden.
Während dem Trainingsprozess findet eine normale Backpropagation statt, bei dem zuerst der Verlust des Netzwerkes bei einem Vorwärtsdurchlauf des Modells berechnet werden und anschließend rückwärts durch das Netz propagiert werden. Die Ausgabe wird dabei in jedem Zeitschritt berechnet. Anschließend wird die partielle Ableitung des Verlusts nach den Gewichten berechnet, damit diese entsprechend angepasst werden können, um die Genauigkeit des Modells weiter zu erhöhen. In einem RNN wird meist der stochastische Gradientenabstieg als Optimierungsalgorithmus genutzt, um die Rechenkomplexität des Modells zu verringern und dadurch ein schnelleres Training zu ermöglichen.
Jedoch können die Gradienten während dem Training verschwindend gering werden, wodurch sich die Neuronengewichte nur sehr wenig oder gar nicht anpassen und das Modell nicht weiter lernt. Um diesem Problem zu entkommen kann entweder das sogenannte Gradient Clipping genutzt werden, bei dem die Werte des Gradienten begrenzt werden, sodass er nicht zu groß oder zu klein wird. Außerdem können auf andere RNN-Zellen zurückgegriffen werden, wie beispielsweise LSTM, die Informationen über längere Zeiträume speichern können.
Das Training des Modells kann weiter verbessert werden, indem wichtige Hyperparameter, wie beispielsweise die Lernrate, die Batch Size oder die Anzahl der Trainingsepochen richtig eingestellt werden. Um die optimalen Werte zu finden, werden, wie bei anderen neuronalen Netzen, die Random oder die Grid Search genutzt.
Abschließend sollte geprüft werden, dass das Modell nicht overfitted und somit nur schlechte Vorhersagen auf neue, ungesehene Daten liefert. Dafür sollten ausreichend Daten für eine Validierungsmenge vorgehalten werden, um die Leistung des Modells unabhängig bewerten zu können und beispielsweise eine Early Stopping Rule einzuführen, die das Overfitting frühzeitig verhindert, indem das Training abgebrochen wird.
Welche Probleme haben Recurrent Neural Networks?
Recurrent Neural Networks waren ein echter Durchbruch im Bereich des Deep Learning, da zum ersten Mal auch die Berechnungen aus der jüngeren Vergangenheit mit in die aktuelle Berechnung mit einbezogen wurden und dadurch die Ergebnisse in der Sprachverarbeitung deutlich verbesserten. Trotzdem bringen sie während des Trainings auch einige Probleme mit sich, die es zu beachten gilt.
Wie wir in unserem Beitrag zum Gradientenverfahren bereits erläutert haben, kann es beim Training von Neuronalen Netzwerken mit dem Gradientenverfahren dazu kommen, dass der Gradient entweder sehr kleine Werte nahe 0 oder sehr große Werte in der Nähe von Unendlich annimmt. In beiden Fällen können wir die Gewichtungen der Neuronen während der Backpropagation nicht mehr abändern, da sich die Gewichtung entweder so gut wie gar nicht ändert oder wir aber die Zahl mit so einem großen Wert überhaupt nicht multiplizieren können. Aufgrund der vielen Vernetzungen im Rekurrenten Neuronalen Netzwerk und der leicht abgeänderten Form des Backpropagation Algorithmus, die dafür genutzt wird, ist die Wahrscheinlichkeit, dass es zu diesen Problemen kommen wird, deutlich höher als in normalen Feedforward Netzen.
Normale RNNs sind sehr gut dafür geeignet, sich Kontexte zu merken und in die Vorhersage mit einzubeziehen. Das ermöglicht es dem RNN beispielsweise zu erkennen, dass in dem Satz “Die Wolken sind am ___” das Wort “Himmel” benötigt wird, um in diesem Kontext den Satz richtig zu vervollständigen. In einem längeren Satz wird es hingegen deutlich schwieriger den Kontext aufrechtzuerhalten. Beim dem leicht veränderten Satz “Die Wolken, die teilweise fließend ineinander übergehen und tief hängen, sind am ___” wird es für ein Recurrent Neural Network schon deutlich schwieriger auf das Wort “Himmel” zu schließen.
Was sind Long Short-Term Memory (LSTM) Modelle?
Das Problem von Recurrent Neural Networks ist, dass sie zwar ein Kurzzeitgedächtnis besitzen, um vorherige Informationen im aktuellen Neuron noch vorzuhalten. Diese Fähigkeit nimmt jedoch bei längeren Sequenzen sehr schnell ab. Als Abhilfe dafür wurden die LSTM Modelle eingeführt, um vergangene Informationen noch länger vorhalten zu können.
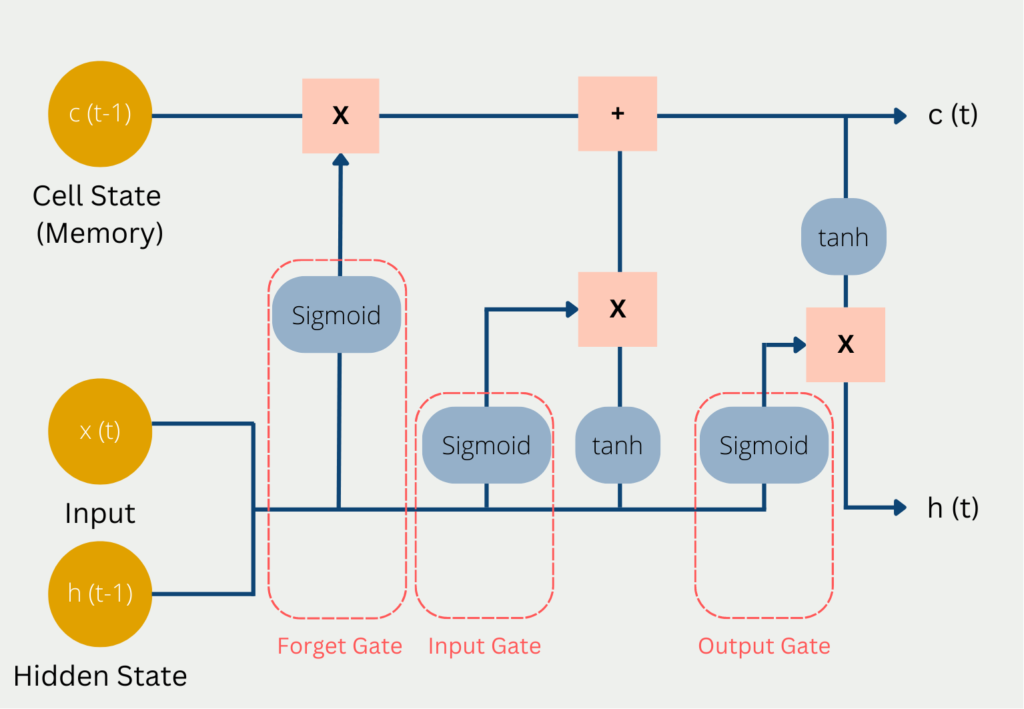
Das Problem von Recurrent Neural Networks ist, dass sie die vorherigen Daten einfach in ihrem “Kurzzeitgedächtnis” abspeichern. Sobald der Speicher darin ausgeht, wird einfach die am längsten erhaltene Informationen gelöscht und durch die neuen Daten ersetzt. Das LSTM Modell versucht diesem Problem zu entkommen, indem es ausgewählte Informationen im Langzeitgedächtnis behält. Dieses Langzeitgedächtnis wird im sogennanten Cell State abgelegt. Zusätzlich dazu gibt es auch den Hidden State, den wir bereits von normalen Neuronalen Netzwerken kennen und in dem kurzzeitige Informationen, aus den vorherigen Berechnungsschritten abliegen. Der Hidden State ist das Kurzzeitgedächtnis des Modells. Somit erklärt sich auch der Name Long Short-Term Networks.
In jedem Berechnungsschritt wird der aktuelle Input x(t) genutzt, der vorherige Stand des Kurzzeitgedächtnis c(t-1) und der vorherige Stand des Hidden States h(t-1).
LSTM und RNN vs. Transformer
Recurrent Neural Networks sind für Machine Learning Verhältnisse schon sehr alt und wurden bereits im Jahr 1986 zum ersten Mal vorgestellt. Für eine lange Zeit waren sie und insbesondere die LSTM Architektur das Non plus ultra im Bereich der Sprachverarbeitung, um den Kontext zu erhalten. Jedoch hat sich diese Stellung seit dem Jahr 2017 und der Einführung von Transformer Modellen und Attention Masks grundlegend geändert.
Die Transformer unterscheiden sich grundsätzlich darin zu bisheringen Modellen, dass sie Texte nicht Wort für prozessieren, sondern ganze Abschnitte als ganzes betrachten. Dadurch haben sie deutliche Vorteile Kontexte besser zu verstehen. Dadurch sind auch die Probleme des Kurz- und Langzeitgedächtnises, die mithilfe von LSTMs teilweise gelöst wurden, nicht mehr vorhanden, denn wenn man den Satz sowieso als Ganzes betrachtet, gibt es keinerlei Probleme, dass Abhängigkeiten vergessen werden könnten.
Darüber hinaus sind Transformer in der Berechnung bidirektional, was bedeutet, dass sie bei der Verarbeitung von Worten auch die unmittelbar folgenden und vorherigen Wörter in die Berechnung mit einbeziehen können. Klassische RNN oder LSTM Modelle können dies nicht, da sie sequenziell arbeiten und somit nur vorangegangene Wörter Teil der Berechnung sind. Dieser Nachteil wurde zwar versucht mit sogenannten bidirektionalen RNNs zu vermeiden, jedoch sind diese deutlich rechenaufwändiger als Transformer.
Die bidirektionalen Recurrent Neural Networks haben jedoch noch kleine Vorteile gegenüber den Transformern, da die Informationen in sogenannten Self-Attention Schichten gespeichert werden. Mit jedem Token mehr, das aufgenommen werden soll, wird diese Schicht schwerer zu berechnen und erhöht somit die benötigte Rechenleistung. Diese Erhöhung des Aufwands gibt es hingegen bei bidirektionalen RNNs nicht in diesem Ausmaß.
Das solltest Du mitnehmen
- Recurrent Neural Networks unterscheiden sich von Feedforward Neural Networks, indem der Output von Neuronen auch in derselben oder vorherigen Schichten als Input genutzt wird.
- Sie bieten sich vor allem in der Sprachverarbeitung und bei Zeitreihendaten an, wenn der vergangene Kontext mit berücksichtigt werden soll.
- Wir unterscheiden verschiedene Arten von RNNs, nämlich die direkte Rückkopplung, die indirekte Rückkopplung, die seitliche Rückkopplung oder die vollständige Rückkopplung.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.

Was ist der Conjugate Gradient?
Erforschen Sie den Conjugate Gradient: Algorithmusbeschreibung, Varianten, Anwendungen und Grenzen.

Was ist ein Elastic Net?
Entdecken Sie Elastic Net: Die vielseitige Regularisierungstechnik beim Machine Learning für bessere Modellbalance und Vorhersagen.
Andere Beiträge zum Thema Recurrent Neural Networks
- Mehr Informationen zu RNNs findest Du unter anderem auf de Tensorflow Seite.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.