In der heutigen Machine Learning Literatur führt kein Weg mehr an Transformer Modellen aus dem Paper „Attention is all you need“ (Vaswani et al. (2017)) vorbei. Speziell im Bereich des Natural Language Processing sind die darin erstmals beschriebenen Transformer Modelle (bspw. GPT-2 oder BERT) nicht mehr wegzudenken. In diesem Beitrag wollen wir die Kernpunkte dieses vielzitierten Papers erklären und die daraus resultierenden Neuerungen aufzeigen.
Was sind Transformer?
Soweit wir wissen, ist der Transformer jedoch das erste Transduktionsmodell, das sich ausschließlich auf die Selbstaufmerksamkeit (im Englischen: Self-Attention) stützt, um Repräsentationen seiner Eingabe und Ausgabe zu berechnen, ohne sequenzorientierte RNNs oder Faltung (im Englischen Convolution) zu verwenden.
Übersetzt aus dem englischen Originaltext: Attention is all you need (Vaswani et al. (2017)).
In verständlichem Deutsch bedeutet dies, dass das Transformer Modell die sogenannte Self-Attention nutzt, um für jedes Wort innerhalb eines Satzes die Beziehung zu den anderen Wörtern im gleichen Satz herauszufinden. Dafür müssen nicht, wie bisher, Recurrent Neural Networks oder Convolutional Neural Networks zum Einsatz kommen. Um zu verstehen, warum das so außergewöhnlich ist, sollten wir uns erstmal genauer anschauen, in welchen Bereichen Transformer zum Einsatz kommen.
Wo kommen Transformer zum Einsatz?
Transformer werden aktuell vor allem für Übersetzungsaufgaben genutzt, wie beispielsweise auch bei www.deepl.com. Darüber hinaus sind diese Modelle auch für weitere Anwendungsfälle innerhalb des Natural Language Processings (NLP) geeignet, wie bspw. das Beantworten von Fragen, Textzusammenfassung oder das Klassifizieren von Texten. Das GPT-2 Modell ist eine Implementierung von Transformern, dessen Anwendungen und die Ergebnisse man hier ausprobieren kann.
Self-Attention am Beispiel einer Übersetzung
Wie wir bereits festgestellt haben, war die große Neuheit des Papers von Vaswani et al. (2017) die Nutzung des sogenannten Self-Attention Mechanismus für textuelle Aufgabenstellungen. Dass dies ein Hauptbestandteil der Modelle ist, sieht man auch bei einem Blick auf die allgemeine Architektur der Transformer.
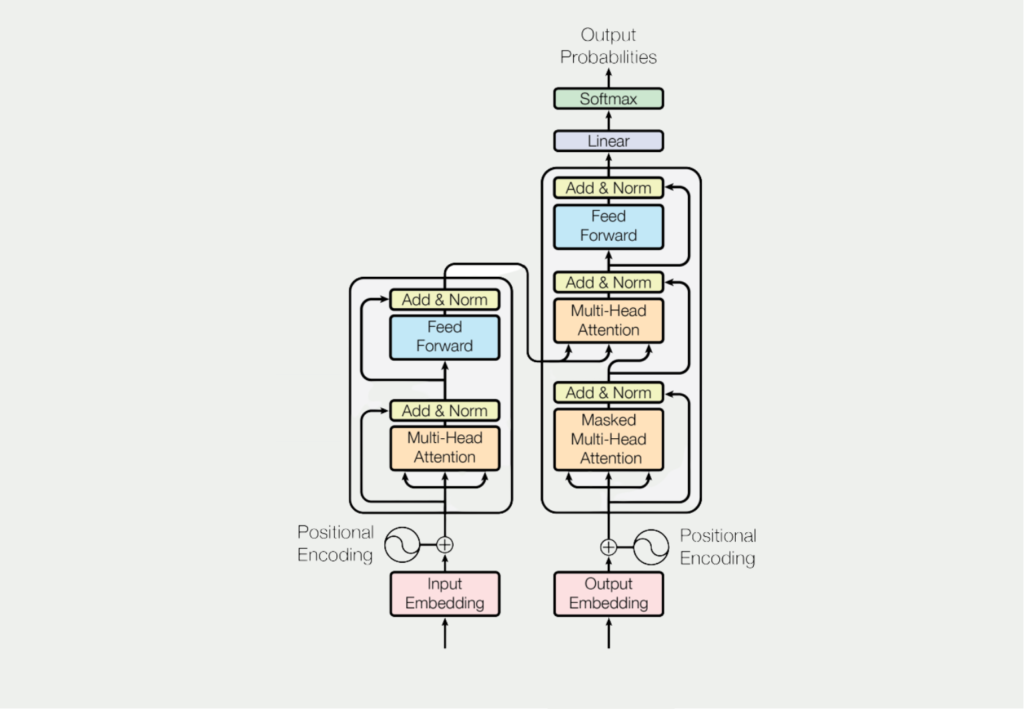
Was dieser Mechanismus konkret bewirkt und warum er so viel besser ist, als die vorherigen Ansätze wird im folgenden Beispiel deutlich. Dazu soll der folgende deutsche Satz mithilfe von Machine Learning ins Englische übersetzt werden:
„Das Mädchen hat das Auto nicht gesehen, weil es zu müde war.“
Für einen Computer ist diese Aufgabe leider nicht so einfach, wie für uns Menschen. Die Schwierigkeit an diesem Satz ist das kleine Wort „es“, das theoretisch für das Mädchen oder das Auto stehen könnte, obwohl aus dem Kontext deutlich wird, dass das Mädchen gemeint ist. Und hier ist der Knackpunkt: der Kontext. Wie programmieren wir einen Algorithmus, der den Kontext einer Sequenz versteht?
Vor Veröffentlichung des Papers „Attention is all you need“ waren sogenannte Recurrent Neural Networks die state-of-the-art Technologie für solche Fragestellungen. Diese Netzwerke verarbeiten Wort für Wort eines Satzes. Bis man also bei dem Wort „es“ angekommen ist, müssen erst alle vorherigen Wörter verarbeitet worden sein. Dies führt dazu, dass nur noch wenig Information des Wortes „Mädchen“ im Netzwerk vorhanden sind bis der Algorithmus überhaupt bei dem Wort „es“ angekommen ist. Die vorhergegangenen Worte „weil“ und „gesehen“ sind zu diesem Zeitpunkt noch deutlich stärker im Bewusstsein des Algorithmus. Es besteht also das Problem, dass Abhängigkeiten innerhalb eines Satzes verloren gehen, wenn sie sehr weit auseinander liegen.
Was machen Transformer Modelle anders? Diese Algorithmen prozessieren den kompletten Satz gleichzeitig und gehen nicht Wort für Wort vor. Sobald der Algorithmus das Wort „es“ in unserem Beispiel übersetzen will, wird zuerst die sogenannte Self-Attention Layer durchlaufen. Diese hilft dem Programm andere Wörter innerhalb des Satzes zu erkennen, die helfen könnten das Wort „es“ zu übersetzen. In unserem Beispiel werden die meisten Wörter innerhalb des Satzes einen niedrigen Wert für die Attention haben und das Wort Mädchen einen hohen Wert. Dadurch ist der Kontext des Satzes bei der Übersetzung erhalten geblieben.
Welche Arten von Transformern gibt es?
Zu der Popularität der Transformer Modelle haben in den letzten Jahren viele Beispiele beigetragen, in denen die Algorithmen in textuellen Anwendungen hervorragende Ergebnisse geliert haben. Zu den bekanntesten Arten von Transformern zählen diese Modelle:
- Transformer-Encoder: Diese Art des Transformers wurde in dem Paper “Attention is All You Need” von Vaswani et al. (2017) eingeführt. Das Ziel ist es, sequentielle Daten, wie sie in Texten oder Zeitreihendaten vorkommen, zu verarbeiten, indem der Mechanismus der sogenannten Self-Attention genutzt wird. Dieser ermöglicht es, sich auf verschiedene Teile der Sequenz zu konzentrieren auf diese “Aufmerksamkeit” zu legen. Vor allem bei der maschinellen Übersetzung und der Stimmungsanalyse konnte dieses Modell sehr gute Ergebnisse erzielen.
- BERT: BERT ist die Abkürzung für Bidirectional Encoder Representations from Transformers und wurde in der Arbeit von Devlin et al. (2018) unter dem Namen “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” zum ersten Mal vorgestellt. Das Modell wird auf einer großen Datenmenge vortrainiert und lernt dabei, sogenannte Maskierungen oder Lücken im Text möglichst richtig auszufüllen. Dadurch kann es konzeptuelle Repräsentation von Wörtern und Sätzen lernen. Durch diesen Aufbau ist es sehr gut geeignet für das Weiterführen von Text oder Question-Answering Systeme.
- GPT: Der Generative Pre-Trained Transformer, oder GPT, ist ein weiterer Typ der Transformer Modelle, der erstmals 2018 im Paper “Improving Language Understanding by Generative Pre-Training” von Radford et al. (2018) vorgestellt wurde. Dieses Modell wird ebenfalls auf großen Datenmengen trainiert, jedoch mit dem Unterschied, dass es ein generatives Sprachmodellierungsziel verfolgt, um zu lernen, neuen Text zu erzeugen, der möglichst gut zur Eingabe passt.
- XLNet: Auch das XLNet Modell basiert auf der Transformerarchitektur und wurde im Artikel “Generalized Autoregressive Pretraining for Language Understanding” von Yang et al. (2018) vorgestellt. Es basiert auf einer permutationsbasierten Vortrainigsmethode, die es ermöglicht, alle Anordnungen der Eingabesequenz zu modellieren. Durch diese Anordnung konnte es das BERT Modell in einigen Anwendungen schlagen.
- T5: Das T5-Modell (Text-to-Text Transfer Transformer) ist ein Sprachmodell, das 2019 von Rafael et al. im Paper “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” vorgestellt wurde. Es kann für eine Reihe von Aufgaben genutzt werden, indem einfach nur die Anwendung in der Inputsequenz genannt wird. Dadurch kann ein einziges Modell genutzt werden, das nicht noch zusätzlich auf eine spezielle Anwendung hin fein trainiert werden muss.
Diese Modelle sind die bekanntesten Arten von Transformern, die auch in der Praxis beeindruckende Ergebnisse liefern konnten. Weiterhin werden neue Architekturen gesucht, um bestehende Modelle weiter zu verbessern, sowie eine höhere Effizienz der Modell zu erreichen.
LSTM und RNN vs. Transformer
Die Künstliche Intelligenz ist aktuell sehr kurzlebig, was bedeutet, dass neue Erkenntnisse teilweise schon sehr schnell wieder überholt und verbessert wurden. Genaus so wie LSTM die Schwachstellen von Recurrent Neural Networks beseitigt hat, können sogenannte Transformer Modelle noch bessere Ergebnisse liefern als LSTM.
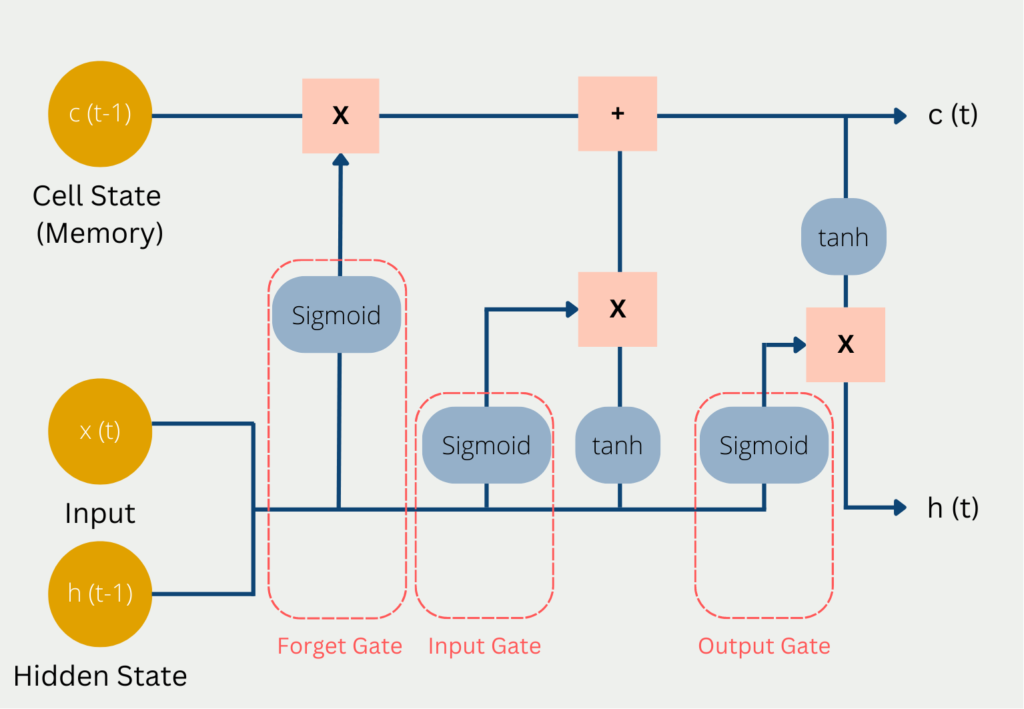
Die Transformer unterscheiden sich grundsätzlich darin zu bisheringen Modellen, dass sie Texte nicht Wort für prozessieren, sondern ganze Abschnitte als ganzes betrachten. Dadurch haben sie deutliche Vorteile Kontexte besser zu verstehen. Dadurch sind auch die Probleme des Kurz- und Langzeitgedächtnises, die mithilfe von LSTMs teilweise gelöst wurden, nicht mehr vorhanden, denn wenn man den Satz sowieso als Ganzes betrachtet, gibt es keinerlei Probleme, dass Abhängigkeiten vergessen werden könnten.
Darüber hinaus sind Transformer in der Berechnung bidirektional, was bedeutet, dass sie bei der Verarbeitung von Worten auch die unmittelbar folgenden und vorherigen Wörter in die Berechnung mit einbeziehen können. Klassische RNN oder LSTM Modelle können dies nicht, da sie sequenziell arbeiten und somit nur vorangegangene Wörter Teil der Berechnung sind. Dieser Nachteil wurde zwar versucht mit sogenannten bidirektionalen RNNs zu vermeiden, jedoch sind diese deutlich rechenaufwändiger als Transformer.
Die bidirektionalen Recurrent Neural Networks haben jedoch noch kleine Vorteile gegenüber den Transformern, da die Informationen in sogenannten Self-Attention Schichten gespeichert werden. Mit jedem Token mehr, das aufgenommen werden soll, wird diese Schicht schwerer zu berechnen und erhöht somit die benötigte Rechenleistung. Diese Erhöhung des Aufwands gibt es hingegen bei bidirektionalen RNNs nicht in diesem Ausmaß.
Was sind die Grenzen von Transformer-Modellen?
Obwohl sich die Transformer Modelle in einer Vielzahl von Anwendungen innerhalb der natürlichen Sprachverarbeitung durchgesetzt haben, gibt es auch Grenzen und Nachteile, die diese Modelle aufweisen. Zum einen wird eine große Datenmenge benötigt, um ein möglichst robustes Modell zu trainieren. Vor allem in Nischen mit sehr spezialisiertem Vokabular kann dies schwierig sein. Jedoch kann man sich in diesen Fällen das Transfer Learning zunutze machen und ein allgemeines Modell auf spezielle Anwendungen noch feinabstimmen.
Der größte Nachteil von Transformer Modellen ist der hohe Rechenaufwand für die Berechnung des Standardmodells aber auch für die Feinabstimmung. Eine normale Standardhardware reicht hierfür meist nicht aus und werden spezielle Server benötigt, die für Machine Learning Anwendungen gebaut wurden und deshalb beispielsweise mehrere Grafikkarten enthalten.
Bei Transformer Modellen handelt es sich um Deep Learning Ansätze, die zumeist nur schwierig oder gar nicht interpretiert werden können. Dadurch ähneln die Vorhersagen einer Blackbox und der Output kann nicht rational erklärt werden. Somit gibt es kein Verständnis dafür, wie und warum Fehler entstehen. Dies kann zum Beispiel bei dem öffentlich zugänglichen ChatGPT zu Problemen führen, da es schwer ist herauszufinden, worin die Ursache für mögliche Falschaussagen liegt.
Trotz der immensen Leistungen von Transformer-Modellen besteht weiterhin Bedarf dafür, diese weiterzuentwickeln und auszubauen. Somit stellt es aktuell noch ein Problem dar, robuste Modelle zu trainieren, wenn es für die gewünschte Sprache oder den gewünschten Sprachbereich nur wenige Daten gibt.
Schließlich ergibt sich bei Transformern, wie auch allgemein bei Machine Learning Modellen, die Frage der Fairness und Gerechtigkeit, da die Modelle sehr stark von den Trainingsdaten und deren Qualität abhängen. Wenn in diesen Daten bewusste oder unbewusste Verzerrungen vorhanden sind, ist die Wahrscheinlichkeit sehr hoch, dass sie vom Modell übernommen werden. Im Fall von Sprachmodellen kann dies dann zum Beispiel rassistische oder beleidigende Aussagen bedeuten. Da auf der anderen Seite jedoch große Datenmengen benötigt werden, lassen sich solche Trainingsdaten nur schwer vermeiden.
Abschließend lässt sich sagen, dass Transformer-Modelle zwar einen großen Sprung im Bereich des NLP gebracht haben, jedoch noch einige Grenzen haben. Deshalb ist die Forschung in diesem Bereich auch weiterhin darum bemüht bessere und effizientere Architekturen zu finden.
Das solltest Du mitnehmen
- Transformer ermöglichen neue Fortschritte im Bereich des Natural Language Processings.
- Transformer nutzen sogenannte Attention Layer. Dadurch werden alle Wörter in einer Sequenz für die Aufgabe genutzt, egal wie weit die Worte in der Anordnung voneinander entfernt sind.
- Transformer lösen Recurrent Neural Networks für solche Aufgaben ab.

Was ist Collaborative Filtering?
Erschließen Sie Empfehlungen mit Collaborative Filtering. Entdecken Sie, wie diese leistungsstarke Technik das Nutzererlebnis verbessert.

Was ist Quantencomputing?
Tauchen Sie ein in das Quantencomputing. Entdecken Sie die Zukunft des Rechnens und sein transformatives Potenzial.

Was ist die Anomalieerkennung?
Entdecken Sie effektive Techniken zur Anomalieerkennung. Erkennen Sie Ausreißer und ungewöhnliche Muster, um bessere Einblicke zu erhalten.

Was ist das T5-Model?
Entdecken Sie die Leistungsfähigkeit des T5-Modells für NLP-Aufgaben - lernen Sie die Implementierung in Python und Architektur kennen.


Was ist MLOps?
Entdecken Sie MLOps und erfahren Sie, wie es den Einsatz von maschinellem Lernen revolutioniert. Erkunden Sie die wichtigsten Konzepte.
Andere Beiträge zum Thema Transformer Modelle
- Das ursprüngliche Paper findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.