Pandas und Numpy sind die grundlegendsten Bibliotheken, wenn es um die Datenbearbeitung in Python geht. Dieser Beitrag gibt Einblick in die wichtigsten Grundlagen in dieser Bibliothek und kann auch als Spickzettel für die häufigsten Befehle genutzt werden.
Pandas bringt alle Werkzeuge mit, die man für jegliche Form der Datenmanipulation und -analyse benötigt. Mit Hilfe von speziellen Datenstrukturen können tabellenähnliche Objekte und Time-Series Daten gespeichert und verarbeitet werden. Pandas baut in vielen Fällen auf Numpy auf und steht also nicht in Konkurrenz zu dieser Bibliothek, wie manchmal behauptet wird.
Was ist Pandas?
Pandas ist eine leistungsstarke Open-Source-Bibliothek zur Datenmanipulation und -analyse für Python. Es wurde entwickelt, um Datenverarbeitung und -analyse nahtlos zu gestalten, und bietet eine Reihe leistungsstarker Tools, die auf der Programmiersprache Python aufbauen. Ganz gleich, ob Du mit kleinen Datensätzen oder riesigen Datenmengen arbeitest, Pandas ermöglicht Dir die effiziente Bearbeitung, Bereinigung und Analyse strukturierter Daten und ist damit ein unverzichtbares Toolkit für Datenwissenschaftler, Analysten und Enthusiasten.
Warum Pandas?
- Benutzerfreundliche Syntax: Pandas verfügt über eine intuitive und ausdrucksstarke Syntax, die es sowohl für Anfänger als auch für erfahrene Programmierer zugänglich macht.
- Unterstützung durch die Gemeinschaft: Mit einer großen und aktiven Community profitiert das Modul von kontinuierlichen Verbesserungen, Updates und einer Fülle von Online-Ressourcen, Tutorials und Foren zur Fehlerbehebung.
- Vielseitigkeit: Von der explorativen Datenanalyse bis hin zur komplexen statistischen Modellierung ist Pandas ein vielseitiges Werkzeug, das sich an verschiedene Phasen des Data Science Workflows anpasst.
Pandas ist Dein zuverlässiger Begleiter, um die Komplexität von Daten in den Griff zu bekommen. Ganz gleich, ob Du Daten für Machine-Learning-Modelle vorbereitest, statistische Analysen durchführst oder Datensätze nach Erkenntnissen durchsuchst, es gibt Dir die Werkzeuge an die Hand, mit denen Du die Herausforderungen der Datenmanipulation in Python effizient bewältigen kannst.
Wie kannst Du Pandas installieren und aufsetzen?
Um deine Reise mit Pandas zu beginnen, sorge dafür, dass die Installation und Einrichtung reibungslos verläuft. Falls du Python noch nicht auf deinem System installiert hast, besuche die offizielle Python-Website unter python.org/downloads. Während der Installation solltest du die Option “Python zum PATH hinzufügen” aktivieren.
Nachdem Python installiert ist, öffne ein Terminal oder die Eingabeaufforderung und führe den Befehl pip install pandas aus, um die neueste Version von Pandas aus dem Python Package Index (PyPI) zu installieren.
Um die erfolgreiche Installation von Pandas zu überprüfen, öffne einen Python-Interpreter oder ein Jupyter Notebook und gib folgendes ein:

Dies sollte die installierte Version von Pandas anzeigen und bestätigen, dass es einsatzbereit ist.
Für Benutzer von Jupyter Notebooks kannst du Pandas direkt im Notebook installieren, indem du den Befehl !pip install pandas ausführst. Für Benutzer von Anaconda ist Pandas oft vorinstalliert, du kannst es jedoch mit conda install -c anaconda pandas aktualisieren.
Mit der erfolgreichen Installation erstelle nun ein neues Python-Skript oder ein Notebook in deiner bevorzugten Umgebung, sei es ein Code-Editor wie VSCode oder eine integrierte Umgebung wie Jupyter Notebooks. Füge am Anfang deines Skripts die Importanweisung import pandas as pd hinzu, um es in deinen Projekten zu verwenden.
Erwäge die Verwendung einer integrierten Entwicklungsumgebung (IDE) wie VSCode oder PyCharm für ein verbessertes Codierungserlebnis mit Funktionen wie Codevervollständigung, Debugging und interaktiver Datenexploration.
Mit diesem Modul nun als Teil deines Python-Werkzeugsatzes und deiner einsatzbereiten Umgebung kannst du die vielfältigen Möglichkeiten von Pandas für effiziente Datenmanipulation und -analyse erkunden.
Welche Datenstrukturen gibt es in dem Modul?
Pandas zeichnet sich durch zwei zentrale Datenstrukturen aus, die es zu einem leistungsstarken Werkzeug für Datenmanipulation und -analyse machen: die Series und der DataFrame.
Series:
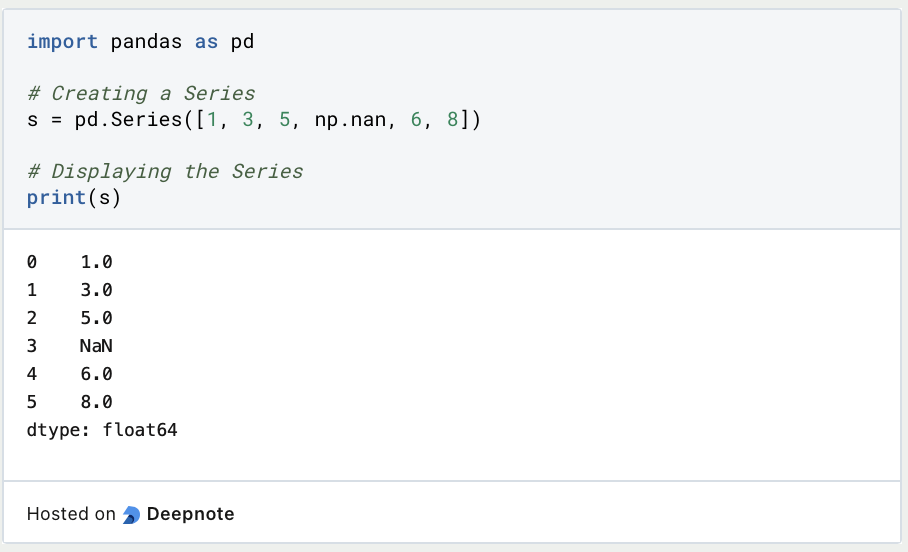
Die Series ist eine eindimensionale, beschriftete Datenstruktur. Ähnlich zu einer Spalte in einer Tabelle oder einer einzelnen Variable in der Statistik, bietet die Series eine flexible Handhabung von Daten. Jeder Eintrag in der Series ist durch einen Index eindeutig identifiziert, was eine effiziente Auswahl und Manipulation ermöglicht.
Beispiel einer Series:
DataFrame:
Der DataFrame ist eine zweidimensionale, tabellenähnliche Datenstruktur. Sie besteht aus mehreren Spalten, wobei jede Spalte eine Series ist. Der DataFrame erlaubt die effiziente Organisation und Manipulation von strukturierten Daten. Wie bei der Series ist auch der DataFrame durch einen Index gekennzeichnet, der die eindeutige Identifikation von Zeilen ermöglicht.
Beispiel eines DataFrame:

Schlüsselmerkmale:
- Flexibilität: Sowohl die
Seriesals auch derDataFramekönnen Daten unterschiedlicher Typen aufnehmen, einschließlich numerischer, textueller oder zeitbasierter Daten. - Effiziente Indizierung: Der Index ermöglicht eine schnelle Auswahl, Filterung und Manipulation von Daten in Pandas-DataFrames.
- Vielfältige Operationen: Mit diesen Datenstrukturen kannst Du eine Vielzahl von Operationen durchführen, darunter Filtern, Sortieren, Gruppieren, Aggregieren und mehr.
- Integration mit Numpy und Matplotlib: Pandas harmoniert nahtlos mit NumPy für numerische Operationen und Matplotlib für die Datenvisualisierung.
Durch die Beherrschung dieser Datenstrukturen kannst Du die volle Bandbreite von Pandas nutzen, um komplexe Datenanalysen und -manipulationen durchzuführen. Sei es das Filtern von Datensätzen, das Zusammenführen von Tabellen oder das Erstellen aussagekräftiger Visualisierungen – Pandas’ Datenstrukturen sind das Herzstück Ihrer Datenexploration.
Was ist der Unterschied zwischen einer Python Liste und einem NumPy Array?
Zu diesem Zeitpunkt im Artikel könnte man meinen, dass NumPy Arrays einfach eine alternative zu den Python Lists darstellen, die sogar noch den Nachteil besitzen, dass sie lediglich Daten eines einzelnen Datentyps speichern können, wohingegen Listen auch eine Mischung aus Strings und Zahlen speichern. Jedoch muss es auch Gründe geben, warum sich die Entwickler von NumPy dazu entschieden haben mit dem Array ein neues Datenelement einzuführen.
Der Hauptvorteil von NumPy Arrays gegenüber Python Lists ist die Speichereffizienz und damit verbunden die Schnelligkeit bei Lese- und Schreibvorgängen. In vielen Anwendungen mag dies nicht wirklich von Bedeutung sein, jedoch kann es bei Millionen oder sogar Milliarden Elementen eine deutliche Zeitersparnis bieten. Somit wird in komplexen Anwendungen häufig auf Arrays zurückgegriffen, um performante Systeme zu entwickeln.
Welche grundlegenden Befehle sollte man kennen?
Wenn Du mit strukturierten Daten in Pandas arbeitest, ist es entscheidend, die grundlegenden Operationen zu beherrschen. Diese Operationen, die sowohl für Series als auch für DataFrame gelten, bilden das Fundament für eine effiziente Datenmanipulation und -analyse.
1. Daten laden:
Das Importieren von Daten in Pandas ist nahtlos. Nutze Methoden wie read_csv(), read_excel() oder andere Methoden zur Datenbereitstellung, um Daten aus verschiedenen Quellen wie CSV-Dateien oder Excel-Tabellen zu laden.

2. Dateninspektion:
Das Verständnis Deines Datensatzes ist entscheidend. Nutze Methoden wie head(), tail(), info() und describe(), um schnelle Einblicke in die Struktur, Typen und Zusammenfassung deiner Daten zu erhalten.

3. Auswahl und Indexierung:
Wähle Daten effizient basierend auf Bedingungen oder spezifischen Kriterien aus. Nutze die boolesche Indexierung für präzise Datenextraktion.

4. Sortieren von Daten:
Ordne Deine Daten basierend auf bestimmten Spalten oder Indizes mit sort_values().

5. Umgang mit fehlenden Werten:
Identifiziere und behandele fehlende Werte mit Methoden wie isnull(), dropna() oder fülle fehlende Einträge mit fillna() auf.

6. Gruppierung und Aggregation:
Gruppiere Deine Daten basierend auf bestimmten Kriterien mit groupby(). Wende Aggregatfunktionen wie sum(), mean() oder benutzerdefinierte Funktionen auf gruppierte Daten an.

7. Datenvisualisierung:
Integriere Pandas nahtlos mit Visualisierungsbibliotheken wie Matplotlib und Seaborn. Erstelle aussagekräftige Diagramme direkt aus Deinen Daten.

Das Beherrschen dieser grundlegenden Operationen stellt Dir das Werkzeug bereit, um effizient Datensätze zu erkunden, zu bereinigen und zu analysieren. Während Du tiefer in Deine Datenexploration eintauchst, dienen diese Operationen als Bausteine für fortgeschrittenere Analysen und Erkenntnisse.
Pandas Objekterstellung
Pandas nutzt verschiedene Datenstrukturen, um Informationen speichern und verarbeiten zu können. In diesem Beitrag können wir leider nicht im Detail auf die verschiedenen Strukturen eingehen und verweisen deshalb auf unsere anderen Artikel, z.B. zu Pandas DataFrames.
Series
Das Pandas Series Objekt ist dem eindimensionalen Numpy Array ähnlich und kann verschiedene Datenstrukturen, wie Integers, Floats oder Strings aufnehmen.

Im Output sehen wir zwei Spalten, obwohl wir nur Werte für die Series definiert haben. Die linke Spalte ist der Index, welcher per Default die Werte durchnummeriert. Wir können auf den Index und die Werte mit folgenden Befehlen zugreifen.

Natürlich können wir den Index auch frei definieren und dadurch einfacher und verständlicher auf die Elemente per Index zugreifen. Dadurch wird der Code auch einfacher zu lesen, wenn man statt Zahlen sprechenden Text für den Zugriff verwendet.

DataFrame
Für eine ausführliche Erklärung zu DataFrames und vielen Code-Beispielen, kannst Du gerne auch unseren separaten Beitrag zu Pandas DataFrames lesen. Hier werden wir der Vollständigkeit halber nur die grundlegendsten Befehle zeigen.
Wir können einen DataFrame erstellen, indem wir ein Numpy Array weitergeben und die Spaltennamen definieren. Die einzelnen Zeilen der Tabelle können wir ähnlich zur Series über den Index aufrufen.

Wie kann man Daten ausgeben?
Die ersten und letzten Zeilen eines DataFrames können wir mit den folgenden Befehlen einsehen. In Klammern geben wir die Anzahl an Reihe an, die wir ausgegeben haben wollen. Der Default Wert ist fünf.

Wenn wir eine kurze statistische Übersicht über die Daten in den einzelnen Spalten erhalten wollen, können wir das mit df.describe() tun:

Zusätzlich können wir uns die Daten auch direkt sortiert anschauen, indem wir den Spaltennamen angeben, nach dessen Werten wir sortieren wollen.

Wie kann man Daten selektieren?
Unsere Ausführung in diesem Kapitel gelten bis auf wenige Ausnahmen auch genauso für Pandas Series Objekte, deshalb ersparen wir uns die Beispiele für Series Objekte. Eine Spalte des DataFrames können wir auswählen, indem wir den Namen direkt aufrufen.

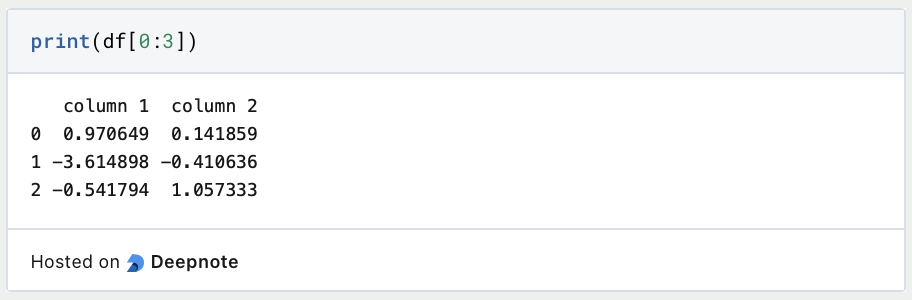
Einzelne Zeilen des DataFrames rufen wir entweder über die gewünschten Nummerierung auf oder über die Indexe/Namen, die wir dafür vergeben haben.
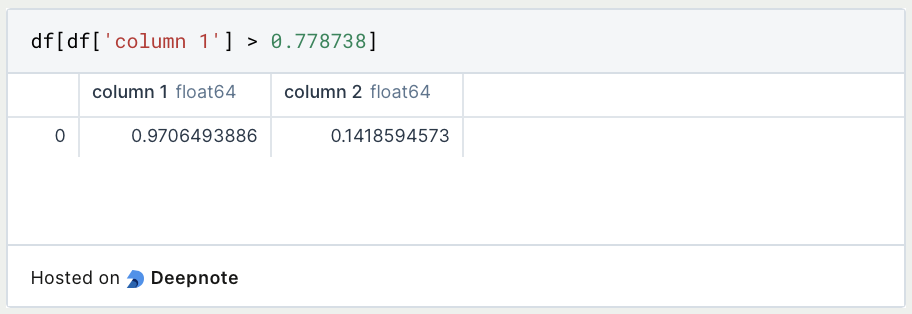
Wenn wir nur die Werte filtern wollen, die eine bestimmte Bedingung erfüllen, definieren wir die Spalte und den Wert der erfüllt sein muss. Dabei müssen wir beachten, dass in Python Bedingungen mit dem Gleichzeichen, immer ein doppeltes Gleichzeichen benötigen.
Das soll es mit einer kurzen Einführung in die grundlegendsten Befehle in Pandas gewesen sein. Weiter geht es mit einem zweiten Teil, der in wenigen Tagen folgt.
Wie kann man Pandas für die Datenvisualisierung nutzen?
Datenvisualisierung ist ein kraftvolles Element von Pandas und integriert sich nahtlos mit beliebten Bibliotheken wie Matplotlib und Seaborn. Diese Integration ermöglicht es dir, mühelos aussagekräftige Visualisierungen direkt aus deinem Datensatz zu erstellen. Hier ist eine Anleitung, die dir hilft, das Potenzial der Datenvisualisierung mit Pandas zu entfesseln:
1. Linienplots:
Die Visualisierung von Trends über die Zeit oder kontinuierliche Daten wird mit Linienplots einfach. Pandas’ plot() Methode erleichtert diesen Prozess und bietet eine schnelle Möglichkeit, solche Visualisierungen zu generieren.
Zum Beispiel kannst du einen Linienplot für eine numerische Spalte erstellen:

2. Histogramme:
Untersuche die Verteilung numerischer Daten mit Histogrammen. Diese Visualisierungsmethode bietet einen schnellen Überblick über Datenmuster und das Vorhandensein von Ausreißern.
Du kannst beispielsweise ein Histogramm für eine numerische Spalte erstellen:
3. Scatter Plots:
Erkunde Beziehungen zwischen zwei numerischen Variablen mit Scatter Plots. Diese Art der Visualisierung ist nützlich, um Korrelationen zwischen Variablen zu identifizieren.
Hier ist ein Beispiel für die Erstellung eines Scatter Plots:

4. Box Plots:
Entdecke statistische Ausreißer und verstehe die Datenverteilung mit Box Plots. Diese Visualisierungsmethode bietet wertvolle Einblicke in die Streuung deiner Daten.
Du kannst beispielsweise einen Box Plot für ausgewählte numerische Spalten erstellen:

5. Balkendiagramme:
Visualisiere kategoriale Daten oder vergleiche Mengen in verschiedenen Kategorien mit Balkendiagrammen. Diese Art der Visualisierung ist effektiv, um Zählungen oder Anteile darzustellen.
Zum Beispiel kannst du ein Balkendiagramm für eine kategoriale Spalte erstellen:

6. Kuchendiagramme:
Repräsentiere den Anteil verschiedener Kategorien in deinem Datensatz mit Kuchendiagrammen. Diese Art der Visualisierung eignet sich gut, um die Verteilung kategorialer Daten anzuzeigen.
Zum Beispiel kannst du ein Kuchendiagramm für eine kategoriale Spalte erstellen:

7. Anpassen von Plots:
Passe deine Visualisierungen an, indem du Plot-Parameter wie Farben, Beschriftungen und Titel anpasst. Dies ermöglicht es dir, Visualisierungen zu erstellen, die deine Erkenntnisse effektiv vermitteln.
Als Beispiel kannst du einen Linienplot mit bestimmten Farben und Beschriftungen anpassen:

Pandas vereinfacht den Prozess der Erstellung aussagekräftiger Visualisierungen, die es dir ermöglichen, deine Dateninsights effektiv zu kommunizieren. Durch die Kombination von Pandas mit Matplotlib und Seaborn kannst du eine Vielzahl von Visualisierungen erstellen, die auf deine spezifischen Anforderungen bei der Datenexploration zugeschnitten sind. Egal, ob du Trends, Verteilungen oder Beziehungen erkundest, Pandas gibt dir die Werkzeuge an die Hand, um deine Daten in überzeugende visuelle Erzählungen zu verwandeln.
Das solltest Du mitnehmen
- Pandas ermöglicht eine effiziente Datenmanipulation und -analyse mit einer ausdrucksstarken Syntax.
- Series und DataFrame sind für verschiedene Datentypen geeignet und bieten Flexibilität und Effizienz.
- Pandas lässt sich nahtlos mit Matplotlib und Seaborn integrieren, um aufschlussreiche Visualisierungen zu erstellen.
- Grundlegende Operationen wie Laden, Prüfen und Sortieren sind die Basis für die Erkundung.
- Pandas vereinfacht die Identifizierung und Behandlung fehlender Daten mit Methoden wie dropna().
- Gruppierungs- und Aggregationsoperationen extrahieren statistische Erkenntnisse aus Daten.
- Pandas erleichtert die effektive Kommunikation von Erkenntnissen durch verschiedene Diagrammtypen.
- Es bietet eine breite Palette von Funktionalitäten, die zum kontinuierlichen Lernen anregen.
- Die Beherrschung von Pandas öffnet das Tor zu fortgeschrittener Datenanalyse und -manipulation.
- Die Community und die Dokumentation tragen zu einer unterstützenden Lernumgebung bei.

Python Tutorial für Anfänger
Beherrschen Sie die Grundlagen mit diesem Python Tutorial. Erfahren Sie mehr über Syntax, Datentypen, Kontrollstrukturen und mehr.

Was sind Python Variablen?
Eintauchen in Python Variablen: Erforschen Sie Datenspeicherung, dynamische Typisierung, Scoping und Tipps für effizienten Code.

Was ist Jenkins?
Jenkins beherrschen: Rationalisieren Sie DevOps mit leistungsstarker Automatisierung. Lernen Sie CI/CD-Konzepte und deren Umsetzung.

Python-Tutorial: Bedingte Anweisungen und If/Else Blöcke
Lernen Sie, wie man bedingte Anweisungen in Python verwendet. Verstehen Sie if-else und verschachtelte if- und elif-Anweisungen.

Was ist XOR?
Entdecken Sie XOR: Die Rolle des Exklusiv-Oder-Operators in Logik, Verschlüsselung, Mathematik, KI und Technologie.

Wie kannst Du die Ausnahmebehandlung in Python umsetzen?
Die Kunst der Ausnahmebehandlung in Python: Best Practices, Tipps und die wichtigsten Unterschiede zwischen Python 2 und Python 3.
Andere Beiträge zum Thema Pandas
- Die offizielle Dokumentation von Pandas findest Du hier.
- Dieser Beitrag baut hauptsächlich auf dem Tutorial von Pandas selbst auf. Dieses findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.