Den DataFrame (kurz: DF) aus der Python Bibliothek Pandas kann man sich am einfachsten als tabellenähnliches Objekt vorstellen bestehend aus Daten, die in Zeilen und Spalten gespeichert sind. Pandas bietet, einfach gesprochen, dieselben Möglichkeiten wie strukturierte Arrays in NumPy mit dem Unterschied, dass die Zeilen und Spalten mit Namen angesprochen werden können, statt sie mit Zahlenindex aufrufen zu müssen. Dadurch wird die Arbeit mit großen Datensätzen und vielen Spalten erleichtert und der Code verständlicher.
Was ist Pandas?
Pandas ist eine leistungsstarke Open-Source-Bibliothek zur Datenmanipulation für Python. Sie bietet eine leistungsstarke, einfach zu verwendende Datenstruktur namens DataFrame, die besonders nützlich für Datenanalyseaufgaben ist. Am einfachsten lässt sich Pandas als das “Excel von Python” verstehen, denn viele Funktionalitäten aus Microsoft Excel lassen sich auch mit Pandas durchführen. Darüber hinaus besitzt Pandas jedoch noch viel mehr Funktionalitäten und ist auch deutlich performanter.
Was ist ein Pandas DataFrame?
Ein Pandas DataFrame ist eine zweidimensionale, beschriftete Datenstruktur, die einer Tabellenkalkulation oder SQL-Tabelle ähnelt. Sie besteht aus Zeilen und Spalten, wobei jede Spalte einen anderen Datentyp haben kann. Die Zeilen und Spalten sind mit einem eindeutigen Index bzw. Spaltennamen versehen, was das Auswählen, Filtern und Manipulieren von Daten erleichtert.

Wie können DataFrames verstanden werden?
Bevor wir uns dem Erstellen von DFs widmen können, müssen wir verstehen aus welchen Objekten sich dieser zusammensetzen kann. Dieses Wissen ist nötig, da es verschiedene Wege gibt, DFs zu erstellen und diese davon abhängen, welches Datenobjekt man als Grundlage nutzt. Nur so lässt sich auch die Möglichkeiten verstehen, die man mit DFs hat und die diese auch deutlich abheben von den reinen Tabellen, mit denen sie oft verglichen werden.
Um die nachfolgenden Abschnitte zu verstehen, ist ein grundlegendes Wissen zu Datenstrukturen in Python und Pandas die Grundvoraussetzung. Falls Du dieses nicht hast oder Deine Kenntnisse auffrischen willst, nutze gerne unsere Beiträge zum Thema Pandas Series und Python Dictionary.
DataFrame als Sammlung von Series Objekten
Das Series Objekt in Pandas ist ein ein-dimensionales Array mit einem veränderbaren Index für das Aufrufen von einzelnen Einträgen. In Python kann man ein solches Objekt mit folgendem Befehl erstellen:
import pandas as pd
area_dict = {‘California’: 423967, ‘Texas’: 695662, ‘New York’: 141297, ‘Florida’: 170312, ‘Illinois’: 149995}
area = pd.Series(area_dict)Die Series hat als Index verschiedene amerikanische Bundesstaaten und die zugehörige Fläche des Staates in km². Eine zweite Series mit demselben Index, also den gleichen fünf amerikanischen Staaten, enthält die Einwohnerzahl pro Staat.
population_dict = {‘California’: 38332521, ‘Texas’: 26448193, ‘New York’: 19651127, ‘Florida’: 19552860, ‘Illinois’: 12882135}
population = pd.Series(population_dict)
Da beide Series Objekte den gleichen Index besitzen, können wir sie zu einem DataFrame Objekt zusammenfassen, mit den Indexwerten (die fünf Staaten) als Zeilen und die Kategorien (Fläche und Einwohnerzahl) als Spalten:
states_df = pd.DataFrame({‘population’: population, ‘area’: area})Genau wie die Series Objekte davor, hat auch der DF weiterhin ein Index, über den die Zeilen gezielt angesprochen werden können:
states.indexZusätzlich haben können auch die Spalten des tabellenähnlichen DFs über ihre Namen aufgerufen werden:
states.columnsDataFrame als spezialisiertes Dictionary
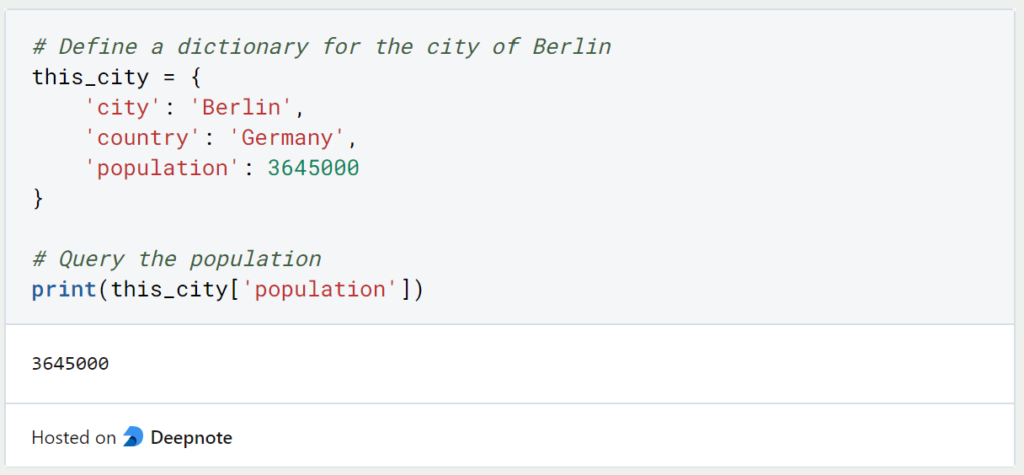
Ein anderer Ansatz zur Interpretation von DataFrame Objekten ist es als spezialisiertes Dictionary zu sehen, bei dem der DF eine Spalte auf ein Series Objekt innerhalb der Spalte verweist, genau wie ein Dictionary einen Key zu einem Wert zuordnet. Wir können es auch genauso abfragen wie ein Dictionary und erhalten dabei jedoch die ganze Spalte und nicht nur einen speziellen Wert:
states[‘area’]Wie erstellt man einen Pandas DataFrame?
Im Allgemeinen gibt es vier verschiedene Wege einen DF zu erstellen, die abhängig vom Use Case alle nützlich sein können:
- Aus einem einzelnen Series Objekt. Der DF ist eine Sammlung aus mehreren Series Objekten. Er kann jedoch auch aus einer einzelnen Series erstellt werden und weist dann nur eine Spalte auf:
pd.DataFrame(population, columns=[‘Population’]- Aus einer Liste von Dictionaries. Selbst wenn nicht alle Dictionaries dieselben Keys besitzen, werden die fehlenden Werte mit NaN (‘not a number’) aufgefüllt. Die Anzahl der Spalten ergibt sich somit aus der Anzahl an eindeutigen Keys und die Zahl der Zeilen aus der Zahl an Dictionaries:
pd.DataFrame([{'a': 1, 'b': 2}, {'b': 3, 'c': 4}])- Aus einem Dictionary von Series Objekten. Dieser Weg wurde bereits in den Abschnitten zuvor ausführlich beschrieben:
pd.DataFrame({‘population’: population, ‘area’: area})- Aus einem zweidimensionale Numpy Array. Mehrere zweidimensionale Numpy Arrays können in einem DF zusammengefasst werden. Wenn keine Bezeichnungen als Spaltennamen gepflegt sind, werden Zahlen als Spaltenindex genutzt:
pd.DataFrame(np.array([[1, 2], [3, 4]]), columns=[col1, col2'], index=['row1', row2’])Wie kann eine Excel- oder CSV-Datei eingelesen werden?
Wenn man nicht ein neues Objekt erstellen will und stattdessen auf eine bereits vorhandene Datei zurückgreifen will, lässt sich dies auch mit Pandas umsetzen. Mithilfe der Funktionen “read_csv()” oder “read_excel()” lassen sich die entsprechenden Dateien auslesen und werden direkt in einen DataFrame umgewandelt.
import pandas as pd
df = pd.read_csv("name_of_csv.csv")
df2 = pd.read_excel("name_of_excel.xlsx")Wichtig ist hierbei, dass man auch die richtige Endung der Datei im Namen mit beachtet. Ansonsten kann es zu Fehlern kommen.
Kann man einen DataFrame in einer for-Schleife erstellen?
In anderen Programmiersprachen, wie R, ist es normal ein leeres Objekt zu erstellen und es dann mit einer for-Schleife schrittweise zu füllen, so wie man es in Python beispielsweise mit Listen tun kann. Diese Vorgehensweise ist bei Pandas DF zwar möglich, sollte aber, wenn möglich, nicht genutzt werden. Die Daten sollten erst in Listen oder Dictionaries gespeichert werden und dann in einem Schritt als DataFrame zusammengefasst werden. Diese Vorgehensweise spart massiv Zeit und Speicherkapazitäten (vgl. auch Stack Overflow).
Welche Best Practices gilt es bei der Arbeit mit Pandas DataFrames zu beachten?
Der Pandas DataFrame ist eine vielseitige und leistungsstarke Datenstruktur, die in vielen Anwendungen genutzt werden kann. Um das Meiste aus diesen Allroundern herauszuholen, sollten ein paar Best Practices beachtet werden, die sicherstellen, dass gut mit den DataFrames gearbeitet wird und Fehler möglichst vermieden werden.
1. Pandas richtig importieren
Bei dem Import des Moduls in ein Python-Skript oder ein Jupyter Notebook sollte Pandas meist komplett importiert werden. Außerdem sollte die allgemeine Abkürzung “pd” verwendet werden, da sie verständlich ist und den folgenden Code verkürzt.
import pandas as pd
2. Verwende read_csv und read_excel für die Dateneingabe
Bei der Arbeit mit Excel und CSV-Dateien sollte auf die dafür vorgesehenen Funktionen von Pandas zurückgegriffen werden, also pd.read_csv() und pd.read_excel(). Dadurch werden die Dateien effizient eingelesen und Datentypen werden automatisch erkannt.
df = pd.read_csv('daten.csv')3. Setze den Index klug
Der Index eines DataFrames ist ein mächtiges Tool, das es von anderen Datenstrukturen, wie beispielsweise dem NumPy Array unterscheidet. Nutze eine geeignete Spalte, um den Index zu setzen und dadurch die Datenabfrage und Datenmanipulation erheblich zu erleichtern.
df.set_index('datum', inplace=True)4. Vermeide das Iterieren über Zeilen
Pandas bietet zwar ein leistungsstarkes Teil für das Iterieren über Zeilen hinweg, jedoch sollte dieser Schritt, wenn möglich, vermieden werden. Arbeite vielmehr mit Funktionen, die Operationen auf kompletten Spalten durchführen können oder wandle die Spalten vorher in eine andere Datenstruktur um, um die optimale Performance zu erreichen.
# Schlechte Praxis (langsam):
for index, row in df.iterrows():
df.at[index, 'neue_spalte'] = row['alte_spalte'] * 2
# Bessere Praxis (schneller):
df['neue_spalte'] = df['alte_spalte'] * 25. Verwende .loc und .iloc für die Auswahl
Mithilfe dieser Funktionen können einfach einzelne Zeilen ausgewählt oder abgefragt werden. .loc wird dabei für die indexbasierte Abfrage genutzt und .iloc lassen sich die Zeilen durch Angabe der Ganzzahl abfragen. Diese Möglichkeiten sind deutlich effizienter als die Nutzung der Klammerschreibweise.
# Indexbasierte Auswahl
df.loc[df['spalte'] > 5]
# Integerbasierte Auswahl
df.iloc[2:5, 1:3]6. Vermeide verschachtelte Indizierungen
Die Nutzung von verschachtelten Indizierungen, wie sie beispielsweise aus verschachtelten Listen bekannt sind, sollten möglichst vermieden werden, um Fehler zu umgehen und unvorhersehbares Verhalten zu vermeiden. Für eine solche Abfrage können vielmehr die Indexierungsfunktionen genutzt werden.
# Schlechte Praxis (verschachtelte Indizierung)
df['spalte']['zeile']
# Bessere Praxis (explizite Indexierung)
df.loc['zeile', 'spalte']7. Behandle fehlende Daten angemessen
Pandas ist ein unglaublich starkes Tool für die Datenmanipulation. Es werden verschiedene Möglichkeiten geboten, wie mit leeren Feldern umgegangen werden soll. Diese können entweder mit einem neuen Wert gefüllt oder die komplette Zeile oder Spalte gelöscht werden.
# Ersetze fehlende Werte durch den Mittelwert
df['spalte'].fillna(df['spalte'].mean(), inplace=True)8. Vermeide In-Place-Änderungen
Wenn Änderungen an einem DataFrame vorgenommen werden, wie zum Beispiel das Entfernen von Spalten oder die Änderung von Werten, sollte möglichst eine Veränderung des ursprünglichen Objekts vermieden werden, falls es zu unvorhergesehenen Problemen kommt. Stattdessen sollte auf ein neues Datenobjekt zurückgegriffen werden.
# In-Place-Änderung (mit Vorsicht verwenden)
df.drop('spalte', axis=1, inplace=True)
# Sicherer Ansatz (erstellt einen neuen DataFrame)
neuer_df = df.drop('spalte', axis=1)9. Optimiere den Speicherverbrauch
Bei großen Datensätzen können DataFrames viel Speicherplatz im Arbeitsspeicher blockieren. Um das zu verhindern, sollte auf optimierte Datentypen, wenn möglich, zurückgegriffen werden. Beispielsweise können Zahlenwerte mit anderen Genauigkeiten abgespeichert werden. Als Default nutzt Pandas meist den Datentyp mit der höchsten Genauigkeit, aber auch dem höchsten Speicherbedarf.
df['kategorie_spalte'] = df['kategorie_spalte'].astype('category')Diese Methoden und Best-Practices stellt sicher, dass eine effiziente und einfache Arbeit mit DataFrame Objekten möglich ist und der Code wartbar und fehlerunanfällig bleibt. Darüber hinaus gibt es jedoch noch viele weitere Funktionen und Möglichkeiten um mit diesen tabellarischen Datenstrukturen zu arbeiten. Diese findest Du entweder auf unserer Website oder in der offiziellen Dokumentation.
Das solltest Du mitnehmen
- Der Pandas DataFrame ist ein sehr wichtiges Element bei der Datenaufbereitung für Künstliche Intelligenz.
- Er kann am ehesten als SQL-Tabelle verstanden werden mit Zeilen und Spalten, bietet darüber hinaus jedoch noch mehr Funktionalitäten.
- Der DataFrame kann sowohl als Sammlung von Series Objekten verstanden werden oder als spezialisiertes Dictionary.
- Er kann entweder aus einem einzelnen Series-Objekt, aus einer Liste von Dictionaries, aus einem zweidimensionalen NumPy Array oder aus einem Dictionary von Series Objekten erstellt werden.
- Darüber hinaus gibt es die Möglichkeit den DataFrame direkt aus einer Datei, wie beispielsweise aus einer CSV- oder Excel-Datei einzulesen.

Was ist Jenkins?
Jenkins beherrschen: Rationalisieren Sie DevOps mit leistungsstarker Automatisierung. Lernen Sie CI/CD-Konzepte und deren Umsetzung.

Python-Tutorial: Bedingte Anweisungen und If/Else Blöcke
Lernen Sie, wie man bedingte Anweisungen in Python verwendet. Verstehen Sie if-else und verschachtelte if- und elif-Anweisungen.

Was ist XOR?
Entdecken Sie XOR: Die Rolle des Exklusiv-Oder-Operators in Logik, Verschlüsselung, Mathematik, KI und Technologie.

Wie kannst Du die Ausnahmebehandlung in Python umsetzen?
Die Kunst der Ausnahmebehandlung in Python: Best Practices, Tipps und die wichtigsten Unterschiede zwischen Python 2 und Python 3.

Was sind Python Module?
Erforschen Sie Python Module: Verstehen Sie ihre Rolle, verbessern Sie die Funktionalität und rationalisieren Sie die Programmierung.

Was sind Python Vergleichsoperatoren?
Beherrschen Sie die Python Vergleichsoperatoren für präzise Logik und Entscheidungsfindung beim Programmieren in Python.
Andere Beiträge zum Thema Pandas DataFrame
- Die offizielle Dokumentation von Pandas findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.