![]()
Bei der Arbeit mit strukturierten Daten in Python kommt man um Excel- und CSV-Dateien kaum herum. Viele externe Quellen stellen ihre Informationen in diesem Format bereit, da es einen einfachen Aufbau besitzt und von vielen Personen verstanden wird. Außerdem besitzen die meisten Anwender auch ohne Programmiersprache eine Möglichkeit die Dateien beispielsweise mit Microsoft Office zu öffnen.
In diesem Artikel werden Möglichkeiten aufgezeigt, um mit Python Excel- und CSV-Dateien bearbeiten zu können. Dazu zählt nicht nur, wie sich die Dateien öffnen lassen, sondern auch wie bestehende Dateien verändert oder neue Dateien erstellt werden können.
Warum sind CSV- und Excel – Dateien wichtig in Python?
In Python lassen sich viele Anwendungen mithilfe von CSV- und Excel-Dateien umsetzen, weshalb sie ein zentraler Bestandteil in der Programmierung sind. Aus den folgenden Gründen ist die Arbeit mit diesen Dateitypen in Python vorteilhaft:
- Datenanalyse und -verarbeitung: Viele Quellen stellen ihre Informationen in Excel- oder CSV–Dateien bereit. Python bietet vielfältige Werkzeuge, um diese Daten zu verarbeiten und zu analysieren. Beispielsweise kann Python dafür verwendet die Daten anschließend in einer Datenbank zu speichern oder zu bereinigen. Viele dieser Analysen sind entweder in Excel nicht möglich oder benötigen deutlich mehr Zeit.
- Automatisierung: In vielen Anwendungen stellt die Verarbeitung der Dateien eine wiederkehrende Aufgabe dar. Diese lässt sich mit der Programmiersprache Python einfach automatisieren, wodurch sich Zeit und Ressourcen sparen lässt, da die repetitiven Aufgaben wegfallen.
- Interoperabilität: Durch die Möglichkeit mit Python Excel- und CSV-Dateien zu bearbeiten, kann die Programmiersprache in verschiedenen Workflows integriert werden, in denen diese Dateitypen ein vorgegebenes Format zur Datenübergabe sind. Dadurch lässt sich ein nahtloser Übergang zu anderen Programmen herstellen.
- Skalierbarkeit: Im Vergleich zur manuellen Arbeit mit Excel- und CSV-Dateien kann der Programmiercode einfach skaliert werden. Der Aufwand bleibt dadurch bei größeren Datensätzen ähnlich groß und es können auch mehrere Dateien gleichzeitig verarbeitet werden. Bei der manuellen Arbeit hingegen müsste dafür länger gearbeitet werden oder mehr Personen in die Arbeit mit einbezogen werden.
Es ergeben sich also viele Vorteile bei der Nutzung von Python. Deshalb wird in den nächsten Abschnitten möglichst einfach beschrieben, wie die Arbeit mit Excel- und CSV-Dateien in Python gelingen kann.
Welche Bibliotheken werden benötigt und wie kann man sie installieren?
In Python werden verschiedene Module und Bibliotheken genutzt. Diese ermöglichen, dass wiederkehrende und standardisierte Funktionalitäten einfach verwendet werden können und nicht jedes Mal neu von Grund auf geschrieben werden müssen. Für die Arbeit mit Excel- und CSV-Dateien in Python bedeutet dies, dass es verschiedene Bibliotheken gibt, die beispielsweise schon vordefinierte Funktionalitäten zum Öffnen von diesen Dateitypen besitzen. Diese können dann mit wenig Programmieraufwand schnell verwendet werden.
Die folgenden Bibliotheken bieten bereits eine sehr breite Palette an Funktionalitäten und decken einen Großteil der häufigsten Anwendungsfälle ab. Sie sind nicht in der grundlegenden Python Installation enthalten, deshalb zeigen wir auch auf, wie sie installiert und genutzt werden können.
- Pandas: Eine der leistungsfähigsten Bibliotheken im Umgang mit Excel- und CSV-Dateien in Python ist Pandas. Es bietet nicht nur die Möglichkeit die Informationen aus den Dateien zu lesen, sondern kann auch für detaillierte Datenauswertungen genutzt werden. Pandas lässt sich ganz einfach mithilfe von „pip3“ installieren. Das Ausrufezeichnen muss vorangestellt werden, wenn der Befehl innerhalb eines Jupyter Notebooks ausgeführt wird:
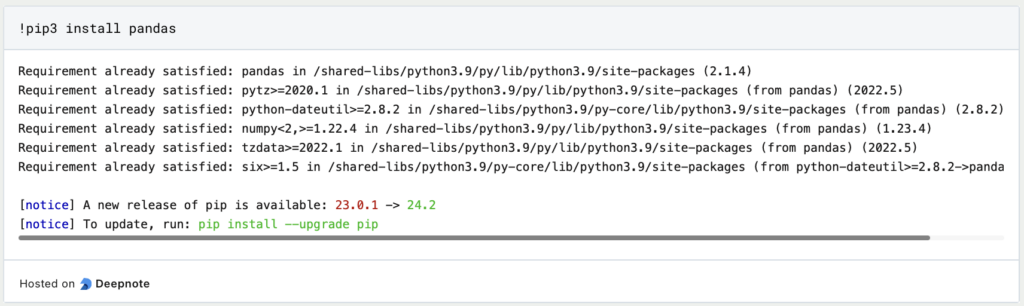
- Openpyxl: Mithilfe von openpyxl können Excel-Dateien im „.xlsx“ Format gelesen und auch geschrieben werden. Zusätzlich enthält es viele verschiedene Möglichkeiten zur Erstellung und Bearbeitung von Tabellen.
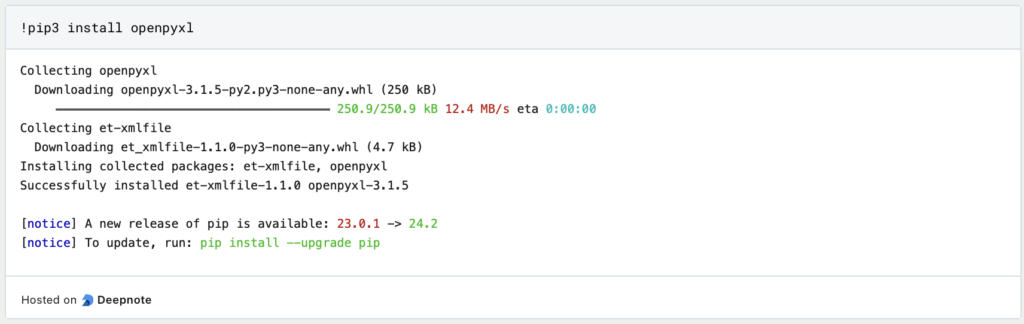
- Xlrd und xlwt: Für das Lesen und Schreiben von älteren Excel-Dateien im „.xls“ Format können die Bibliotheken xlrd und xlwt verwendet werden. Xlrd wird dabei zum Lesen und xlwt zum Schreiben von diesen Dateien genutzt.
- csv: Zusätzlich gibt es auch eine reine Bibliothek für die Arbeit mit CSV-Dateien in Python. Ein Großteil der Funktionalitäten kann zwar auch mit Pandas umgesetzt werden, jedoch kann es in Einzelfällen auch sinnvoll sein mit csv zu arbeiten. Zusätzlich ist csv auch bereits im Standardumfang von Python enthalten und muss nicht erst extra installiert werden, wie die anderen vorgestellten Bibliotheken.
Mithilfe dieser Bibliotheken lässt sich bereits ein Großteil der Anwendungen bei der Arbeit mit CSV- oder Excel-Dateien in Python umsetzen.
Wie kann mit CSV-Dateien in Python gearbeitet werden?
Mit CSV-Dateien in Python zu arbeiten ist sehr einfach und kann sowohl mit der Bibliothek Pandas als auch CSV umgesetzt werden. In diesem Abschnitt werden dazu die grundlegenden Schritte gezeigt, die zum Öffnen, Schreiben und Bearbeiten einer CSV-Datei benötigt werden.
Um dies zu veranschaulichen, wird der sogenannte Auto-MPG Datensatz verwendet, welcher innerhalb des Machine Learnings weit verbreitet ist und für verschiedene Automodelle unter anderem den Durchschnittsverbrauch in der amerikanischen Einheit „Miles per Gallon“ angibt. Dieser Datensatz wurde erstmal 1993 von J. Ross Quinlan in seinem Paper „Combining instance-based and model-based learning“ verwendet und kann auf verschiedenen Plattformen, wie zum Beispiel Kaggle heruntergeladen werden.
Lesen von CSV-Dateien in Python
In Pandas ist das Lesen von CSV-Dateien besonders einfach, da es nur eine Zeile Programmiercode benötigt. Mithilfe von „read_csv“ kann die Datei eingelesen werden und wird automatisch in einem DataFrame, also einer tabellarischen Datenstruktur, abgelegt.

Diese Funktion bietet unter anderem die Möglichkeit das Trennungszeichen festzulegen, welches standardmäßig ein Komma ist. Vor allem im deutschsprachigen Raum, kann es jedoch aufgrund der Zahlenformatierung auch passieren, dass ein Semikolon („;“) als Trennungszeichen verwendet wird, welches sich dann in Python einfach definieren lässt.
In der Bibliothek CSV hingegen erfordert das Öffnen einer CSV-Datei deutlich mehr Befehle. Wie jede andere Datei wird sie mit „open“ geöffnet und dann an den speziellen CSV-Reader übergeben. Diese wandelt dann jede Zeile der Datei in eine Liste mit Werten um.

Bei der Bibliothek CSV lässt sich das Trennungszeichen über den Parameter „delimiter“ definieren, sodass auch Dateien eingelesen werden können, die nicht der ursprünglichen Formatierung entsprechen.
Erstellen von CSV-Dateien in Python
Die Erstellung von CSV-Dateien ist in Pandas ähnlich einfach wie das Einlesen der Dateien, vorausgesetzt, dass die Informationen bereits in Form eines DataFrames vorliegen. Wenn dies nicht der Fall ist, müssen sie erst umgewandelt werden, damit daraus eine CSV – Datei erstellt werden kann.

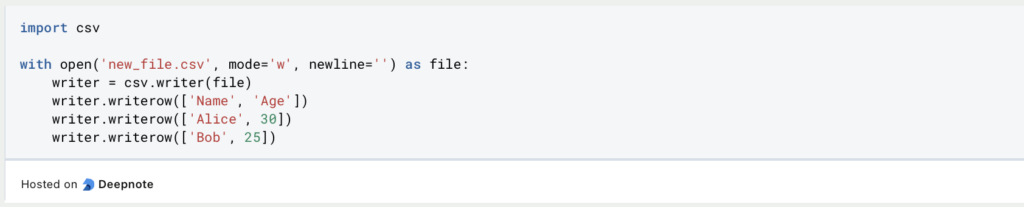
Bei der CSV hingegen ist das ganze etwas komplexer, da jede Zeile einzeln definiert und in ein File geschrieben werden muss. Wenn man dafür bereits eine Datenstruktur besitzt, kann zwar eine einfache Schleife benutzen, jedoch kann es auch passieren, dass jede Zeile einzeln geschrieben werden muss, wie in diesem Beispiel:
Bearbeiten von CSV-Dateien in Python
In Pandas ist die Verarbeitung von Informationen aus den CSV – Dateien verhältnismäßig einfach, da die zugrundeliegende Datenstruktur eine Vielzahl von Änderungen ermöglicht und für die Datenanalyse und -verarbeitung vorgesehen ist.
Dabei lassen sich die Zeilen beispielsweise ohne weiteres Filtern oder Sortieren:

In diesem Artikel findest Du die wichtigsten Befehle, die sich mit DataFrames umsetzen lassen und deshalb auch für die Arbeit mit CSV – Dateien von großer Bedeutung sind.
Dadurch, dass die CSV – Bibliothek keine eigene Datenstruktur besitzt, ist auch die Arbeit mit den eingelesenen Dateien etwas komplexer. In den meisten Fällen kann man dafür mit diversen Schleifen arbeiten und die Ergebnisse in eine neue Datei schreiben.
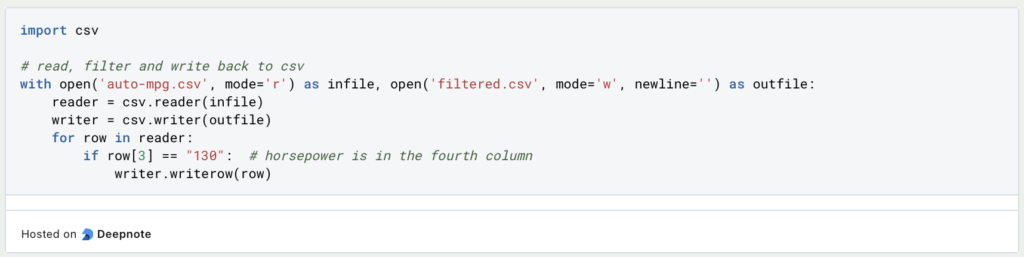
Zusätzlich wird es auch deshalb komplexer, weil die Bibliothek die Überschriften zwar erkennt, aber dem Objekt nicht richtig zuordnen kann. Deshalb müssen Objekte über numerische Indexe referenziert werden und können nicht mithilfe deren Überschriften angesprochen werden.
Wie kann mit Excel-Dateien in Python gearbeitet werden?
Python bietet eine Vielzahl von Bibliotheken, die zur Arbeit mit Excel – Dateien verwendet werden können. In diesem Abschnitt beschränken wir uns jedoch auf Pandas und Openpyxl, die für die neueren Dateien im „.xlsx“ Format verwendet werden können.
Die Nutzung der Bibliothek hängt dabei vor allem vom Anwendungsfall ab. Allgemein gesprochen, ist Pandas die bessere Alternative, wenn es um die Daten geht, die in der Datei enthalten sind und weiter ausgewertet werden sollen. Mit Openpyxl hingegen kann vor allem gearbeitet werden, wenn die Datei an sich von Interesse ist und Änderungen innerhalb der Datei vorgenommen werden sollen, wie beispielsweise die Änderung von Schriftfarben oder ähnliches.
Lesen von Excel-Dateien in Python
In Pandas können Excel – Dateien ganz einfach mithilfe einer einzelnen Zeile eingelesen werden. Mithilfe von „read_excel“ kann einfach die Datei definiert werden und anschließend werden die Daten in einem DataFrame abgelegt. Da Excel – Dateien die Möglichkeiten besitzen, mehrere Tabellenblätter abzuspeichern, muss beim Laden der Name des Blattes explizit erwähnt werden. Wenn kein Name hinterlegt ist, werden alle Tabellenblätter als Dictionary eingelesen und die Blattnamen sind dann jeweils die Schlüssel des Dictionaries.

In Openpyxl werden mehr Schritte benötigt, um eine Datei einzulesen. Dabei kommt die Funktion “load_workbook” zum Einsatz, in der die Datei definiert und eingelesen wird. Anschließend kann auch über den Blattnamen als Schlüssel referenziert werden. Die Daten liegen dann in keinem besonderen Format vor, können jedoch mithilfe der Funktion „iter_rows“ durchlaufen und ausgegeben werden.
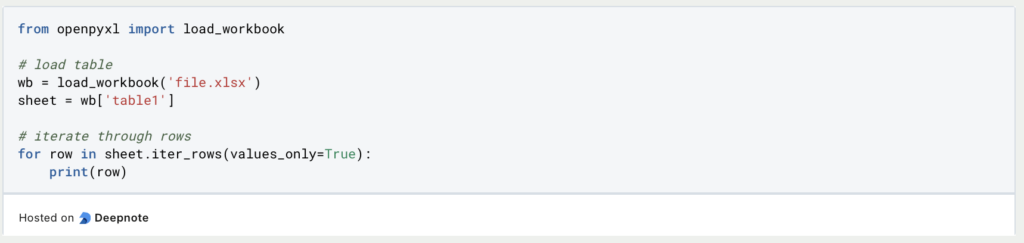
Im Unterschied zu Pandas, liest Openpyxl jedoch nicht nur die reinen Werte ein, sondern auch weitere Metainformationen, die in den folgenden Abschnitten noch von Bedeutung sein werden.
Erstellen von Excel-Dateien in Python
Das Speichern eines DataFrames in eine Excel – Datei ist in Pandas auch mit nur einer Codezeile möglich. Dabei muss neben dem Dateinamen auch ein Blattname definiert werden. Außerdem ist es sinnvoll den Parameter „index“ auf „false“ zu setzen, um zu verhindern, dass der Index des DataFrames auch zusätzlich in der Datei hinterlegt wird.

Natürlich müssen die Daten zuallererst in ein DataFrame Format gebracht werden, bevor sie in Pandas verarbeitet werden können. Ansonsten ist die Speicherung der Excel – Datei deutlich aufwendiger.
In Openpyxl ist die Vorgehensweise bei der Erstellung einer Excel – Datei deutlich anders. Hierbei wird sich zellenweise vorgearbeitet und es muss jeder Wert an die Datei oder das Tabellenblatt übergeben werden. Hierzu wird erst ein Tabellenblatt – Objekt erstellt und die Überschriften definiert. Anschließend können die Zeilen und deren Werte in einer Liste angehängt werden.
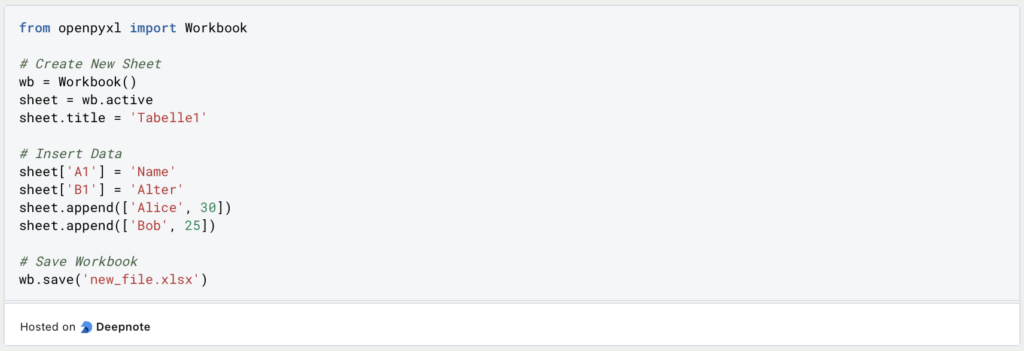
Im Unterschied zu Pandas ist dies zwar deutlich aufwendiger, jedoch stehen dem Nutzer dadurch auch deutlich mehr Funktionalitäten zur Auswahl, da beispielsweise auch über die Werte hinaus, Formatierungen, wie die Schriftart oder die Schriftfarbe, definiert werden können.
Bearbeiten von Excel-Dateien in Python
Die Bearbeitung von Excel-Dateien in Pandas gleicht den Möglichkeiten, die aus dem Abschnitt über CSV – Dateien bereits bekannt sind. Hierbei können im Allgemeinen verschiedenste Anpassungen am DataFrame vorgenommen werden und dieser anschließend wieder als Excel – Datei abgelegt werden.
In Openpyxl ist die Bearbeitung der Dateien schon deutlich interessanter, da eine Vielzahl an Möglichkeiten bestehen. Dabei können nämlich nicht nur beispielsweise einzelne Zellen oder Überschriften geändert werden, sondern mithilfe des Moduls „styles“ auch die Formatierung der Datei verändert werden. Neben der Schriftart können hierüber auch Farben gesteuert werden.
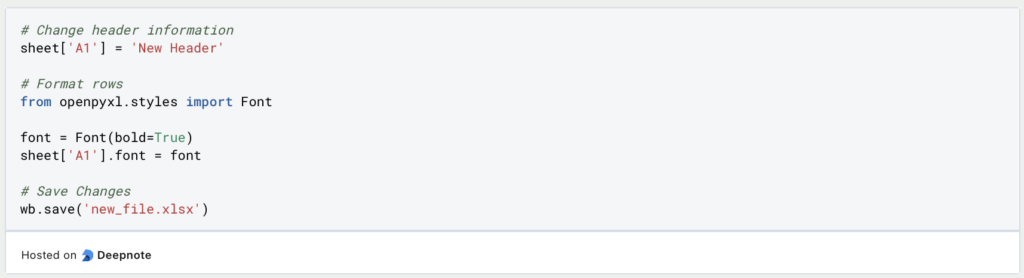
Bei der Bearbeitung von Excel – Dateien sollte man sich die Frage stellen, ob lediglich die Daten ausgelesen und bearbeitet werden sollen oder die komplette Datei verändert werden soll. Abhängig davon kann dann die passende Bibliothek gewählt werden.
Das solltest Du mitnehmen
- Der Umgang mit Excel- und CSV-Dateien in Python ist immens wichtig für verschiedenste Anwendungen, wie zum Beispiel bei der Datenanalyse oder dem Automatisieren von Prozessen.
- Mithilfe von Pandas lassen sich viele Aufgaben einfach und schnell umsetzen, vor allem dann, wenn die Informationen innerhalb der Dateien im Vordergrund stehen.
- Openpyxl ist eine leistungsstarke Bibliothek für die Arbeit mit Excel-Dateien in Python. Es bietet zudem auch die Möglichkeit die Schriftarten und andere Formatierungseinstellungen zu verändern.

Python-Tutorial: Bedingte Anweisungen und If/Else Blöcke
Lernen Sie, wie man bedingte Anweisungen in Python verwendet. Verstehen Sie if-else und verschachtelte if- und elif-Anweisungen.

Was ist XOR?
Entdecken Sie XOR: Die Rolle des Exklusiv-Oder-Operators in Logik, Verschlüsselung, Mathematik, KI und Technologie.

Wie kannst Du die Ausnahmebehandlung in Python umsetzen?
Die Kunst der Ausnahmebehandlung in Python: Best Practices, Tipps und die wichtigsten Unterschiede zwischen Python 2 und Python 3.

Was sind Python Module?
Erforschen Sie Python Module: Verstehen Sie ihre Rolle, verbessern Sie die Funktionalität und rationalisieren Sie die Programmierung.

Was sind Python Vergleichsoperatoren?
Beherrschen Sie die Python Vergleichsoperatoren für präzise Logik und Entscheidungsfindung beim Programmieren in Python.

Was sind Python Inputs und Outputs?
Python Inputs und Outputs beherrschen: Erforschen Sie Eingaben, Ausgaben und den Umgang mit Dateien in der Python-Programmierung.
Andere Beiträge zum Thema Excel- und CSV-Dateien in Python
Tatsächlich kann man mittlerweile auch Python innerhalb von Excel verwenden. Ausführliche Informationen dazu findet man dazu auf der Seite von Microsoft.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.