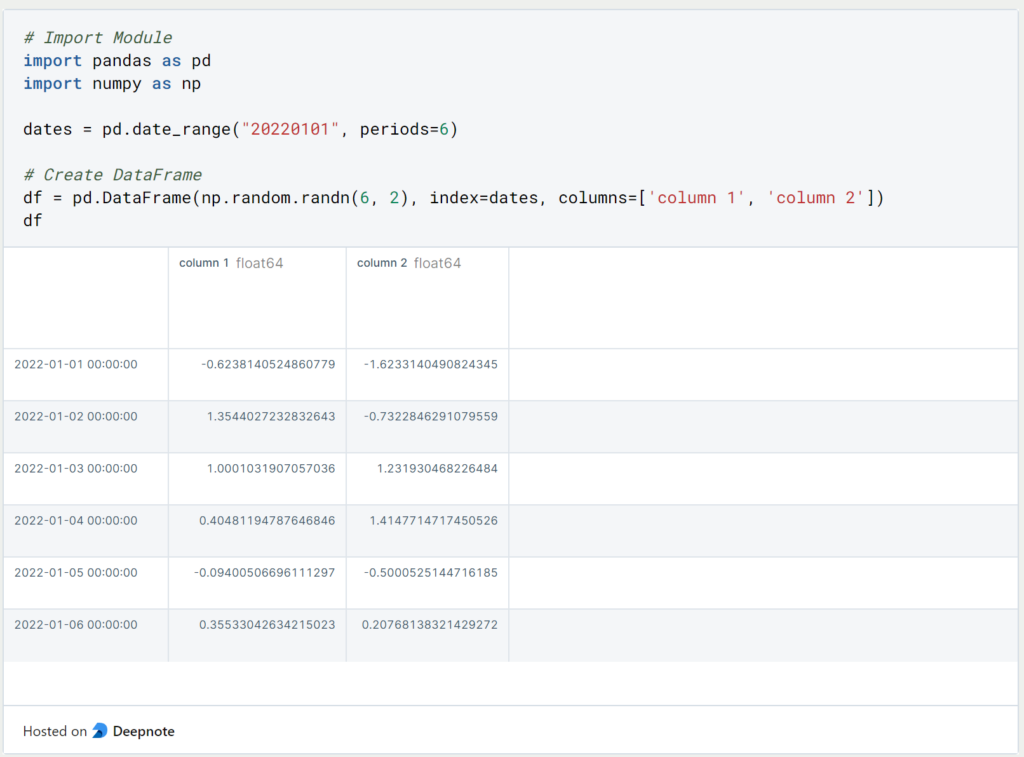
Im ersten Teil dieser Serie haben wir uns bereits grundlegenden Pandas Objekten und deren Abfrage gewidmet. In diesem Kapitel beschäftigen wir uns darüber hinaus mit dem Umgang mit Pandas DataFrames. Als Ausgangsbeispiel nutzen wir den folgenden DataFrame.
1. Wie bekommt man die Anzahl der Zeilen und Spalten zurückgegeben?
Wenn man eine Excel-Datei einliest, möchte man sich wahrscheinlich erstmal einen Überblick über den Pandas DataFrame verschaffen und sich dafür die Zahl der Zeilen und Spalten ausgeben lassen. Dafür kann man den Befehl “.shape” nutzen, der an der ersten Stelle des Tupels die Anzahl der Zeilen und an der zweiten Stelle des Tupels die Anzahl der Spalten zurückgibt:

2. Wie findet man die Anzahl von leeren Feldern heraus?
Damit der DataFrame weiter analysiert und möglicherweise auch für das Training eines Machine Learning Modells genutzt werden kann, sind auch die leeren Felder von besonderem Interesse. Um einen Überblick über die Anzahl der leeren Felder zu bekommen, kann man zwei Befehle nutzen.
Die Funktion “.count()” gibt spaltenweise die Anzahl von nicht-leeren Feldern zurück. Mit der Anzahl der Zeilen im Hinterkopf kann man dann die Anzahl der leeren Felder einfach errechnen:

Wenn man stattdessen direkt die Anzahl der leeren Felder herausfinden möchte, kann man das mithilfe von einem etwas verschachtelten Befehl auch tun. Mithilfe der ersten Komponenten “.isna()” wird in jedem Feld mit “True” oder “False” hinterlegt, ob es sich um ein leeres Feld handelt. Die Funktion “.sum()” summiert dann anschließend alle “False”-Felder. Damit ergeben sich mit dem kombinierten Befehl die Anzahl der leeren Felder pro Spalte.

3. Wie löscht man leere Felder aus einem Pandas DataFrame?
Nachdem wir nun herausgefunden haben, ob und wie viele leere Felder sich in einer Spalte bzw. in dem Pandas DataFrame befinden, können wir nun beginnen, die leeren Felder auszubessern. Eine Möglichkeit besteht darin, die entsprechenden Felder oder sogar die ganze Zeile zu löschen.
Wenn wir einem DataFrame oder anderem Pandas Objekte leere Werte übergeben, werden diese automatisch durch Numpy NaNs (Not a Number) ersetzt. Für Kalkulationen, wie beispielsweise Mittelwertberechnungen, werden diese Felder nicht mit einbezogen und ignoriert. Den bestehenden DataFrame können wir einfach durch eine leere, dritte Spalte erweitern, die nur für den Index 01.01.2022 einen Wert enthält. Die restlichen Werte werden dann automatisch als NaN gesetzt.
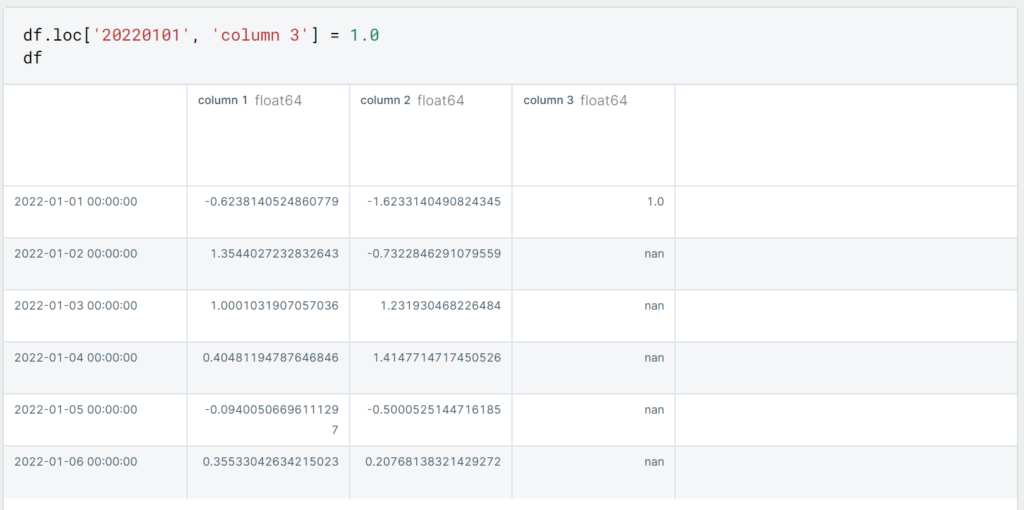
Wenn wir alle Zeilen löschen wollen, die mindestens in einer der Spalten einen leeren Wert haben, können wir das mit dem folgenden Befehl tun.
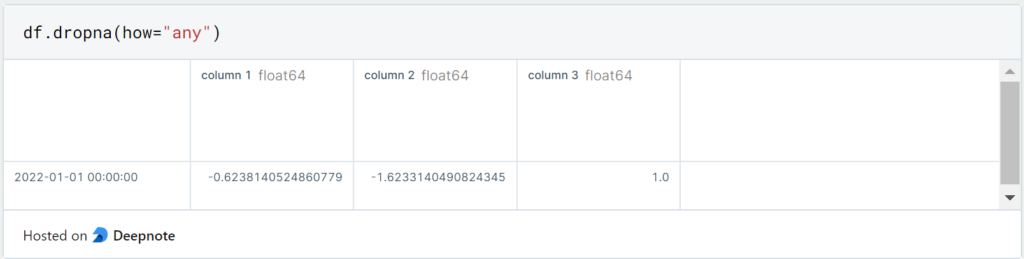
Wenn wir stattdessen Spalten mit Missing Values löschen wollen, nutzen wir dasselbe Kommando und setzen zusätzlich ‘axis = 1’.
4. Wie können leere Felder in einem DataFrame ersetzt werden?
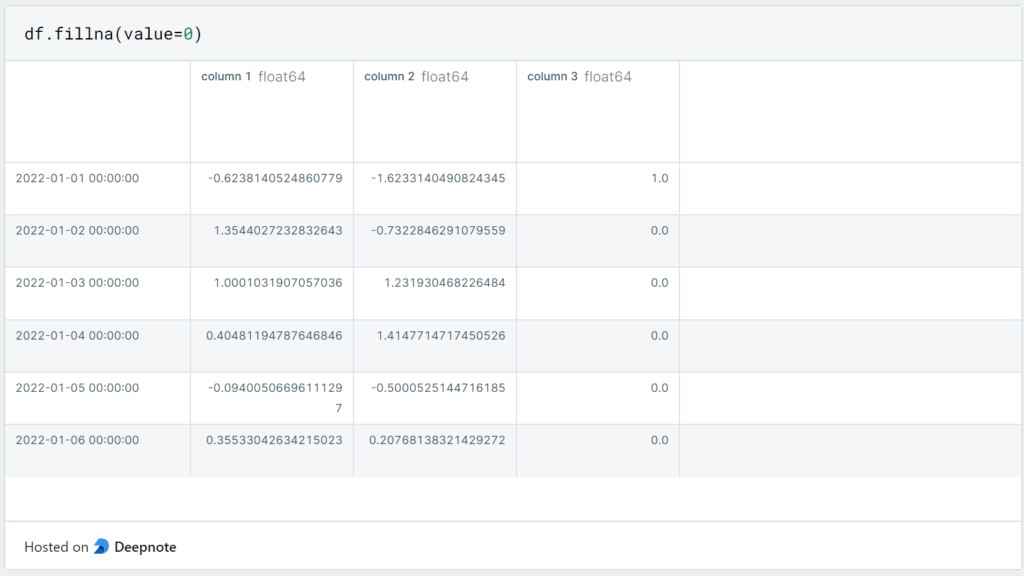
Falls wir nicht die Zeilen oder Spalten mit den leeren Feldern löschen wollen, können wir auch die nicht-gefüllten Felder mit einem Standardwert ersetzen. Dazu nutzt man den Befehl “.fillna()” mit dem Parameter “value”. Dieser Parameter definiert, welcher Wert stattdessen eingefügt werden soll:
In manchen Fällen kann es auch sinnvoll sein, sich in den booleschen Werte (True/False) ausgeben zu lassen, an welcher Stelle Werte fehlen. In den meisten Fällen sind die DataFrame Objekte jedoch zu groß und dies ist keine übersichtliche Darstellung.

5. Wie kann ich bestimmte Zeilen aus einem DataFrame löschen?
Wenn wir nicht nur leere Werte aus unserem DataFrame löschen wollen, gibt es zwei Möglichkeiten, wie wir das tun können. Zum einen können wir die Zeilen aus dem DataFrame löschen, indem wir den Index der Zeile nutzen, die gelöscht werden soll. In unserem Fall ist das ein konkretes Datum, wie beispielsweise der 01.01.2022:
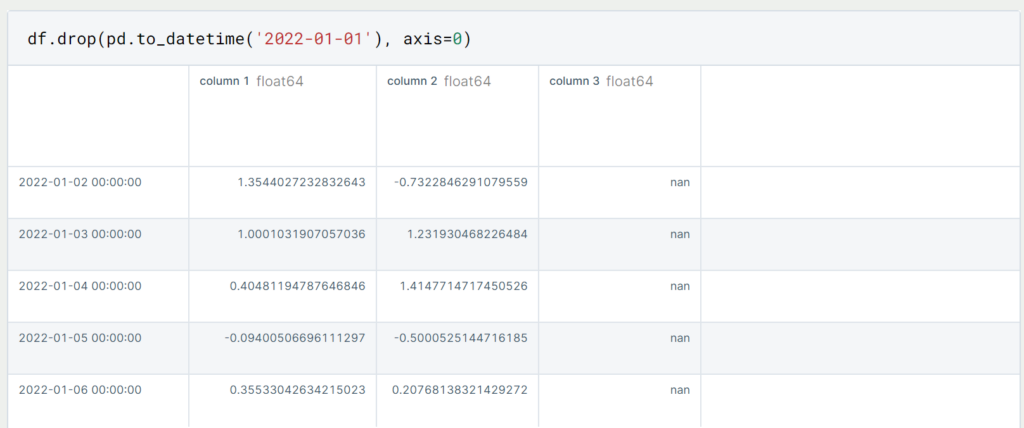
Dadurch haben wir die erste Zeile in diesem Objekt gelöscht. In den meisten Fällen werden wir jedoch die konkrete Zeile noch nicht kennen, die wir löschen wollen. Dann können wir auch den DataFrame auf die Zeilen filtern, die wir löschen wollen und uns dann die Indexe der entsprechenden Rows ausgeben lassen.
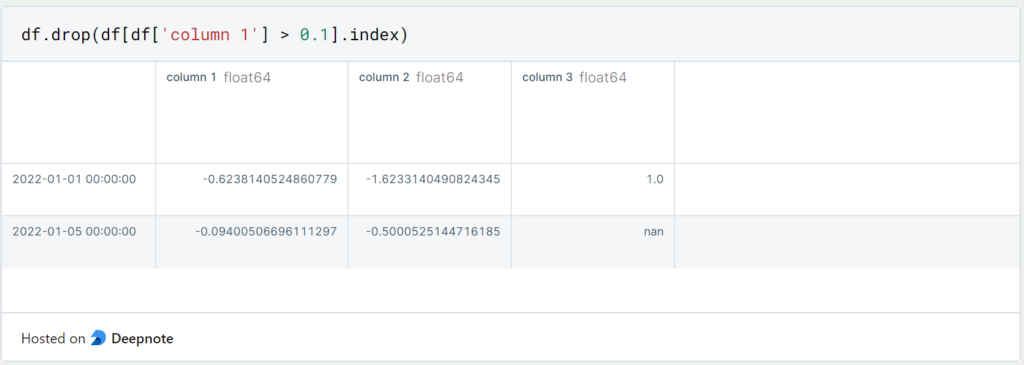
In diesem Fall löschen wir alle Zeilen für die gilt, dass in “column 1” ein Wert größer als 0.1 erkannt wird. Dadurch bleiben insgesamt vier Zeilen im Objekt “df” übrig.
6. Wie fügt man eine Spalte hinzu?
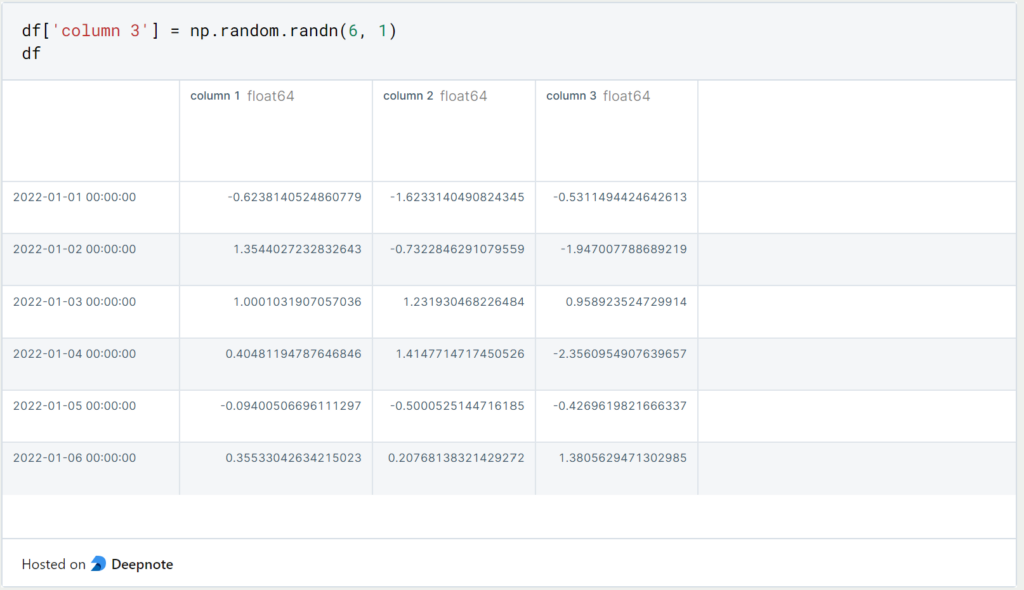
Auch hier gibt es mehrere Möglichkeiten den bestehenden DataFrame um neue Spalten zu erweitern. Indem wir die neue Spalte einfach mit eckigen Klammern definieren wird sie als neue Spalte an den DataFrame von rechts hinzugefügt.
Wenn wir stattdessen die neue Spalte an einem bestimmten Index einfügen wollen, können wir dafür “df.insert()” nutzen:
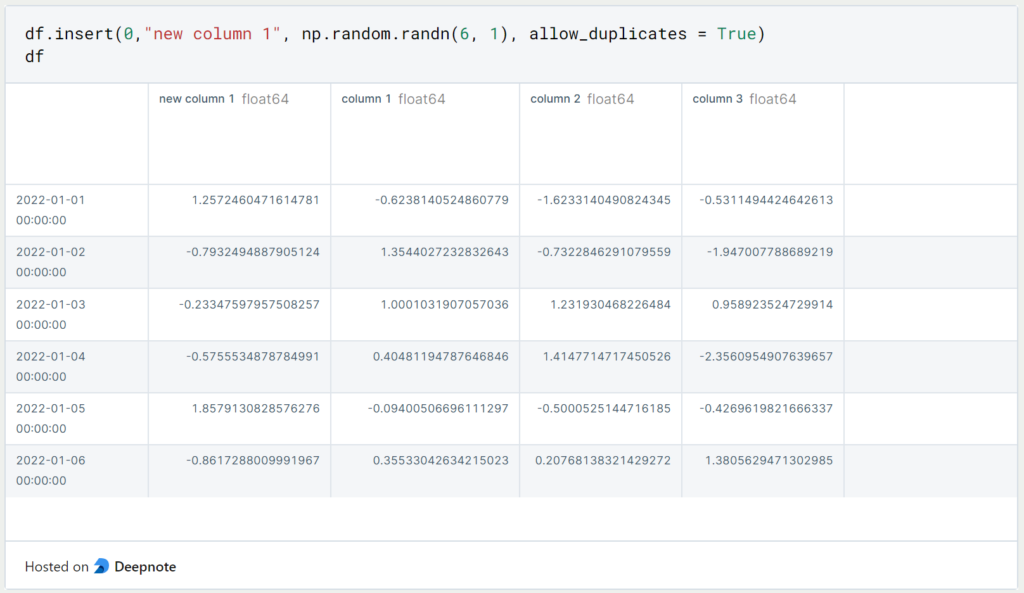
Dieser Funktion übergibt man als ersten Wert den Index der neu einzufügenden Spalte, dann den Namen der Spalte und als drittes das Objekt, das als Spalte eingefügt werden soll. Der letzte Parameter gibt an, ob Duplikate dieser Spalte zugelassen werden. Wenn also die Spalte mit dem Namen und denselben Werten bereits existiert und “allow_duplicates” auf “False” gestellt wurde, dann erhält man eine Fehlernachricht.
7. Wie löscht man eine Spalte?
Wie bei jedem gutem Pandas Befehl, gibt es auch für das Löschen der Spalten verschiedene Möglichkeiten. Die beiden einfachsten sind entweder mithilfe der Funktion “df.drop()” und dem Namen der Spalte, sowie “axis=1” für eine Spaltenauswahl. Oder man nutzt die Python Standardfunktion “del” und definiert die entsprechende Spalte:

8. Wie führt man Pandas Objekte zusammen?
Pandas bietet verschiedene Möglichkeiten, um Series oder DataFrame Objekte zusammenzuführen. Der concat-Befehl erweitert das erstgenannte Objekt um das zweitgenannte Objekt, wenn sie vom selben Typ sind. Der Befehl kann natürlich auch mit mehr als zwei Datenstrukturen ausgeführt werden.
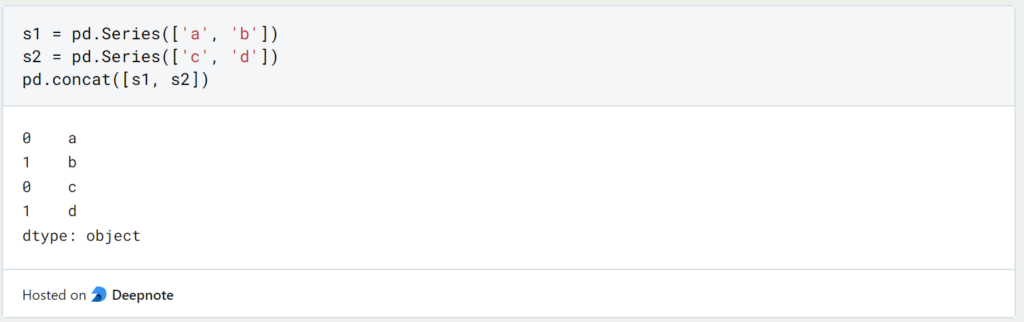
Mit DataFrames sieht die Codezeile genauso aus. Über den Zusatz ‘ignore_index’ wird ein neuer durchgängiger Index vergeben und nicht der Index aus dem ursprünglichen Objekt übernommen.
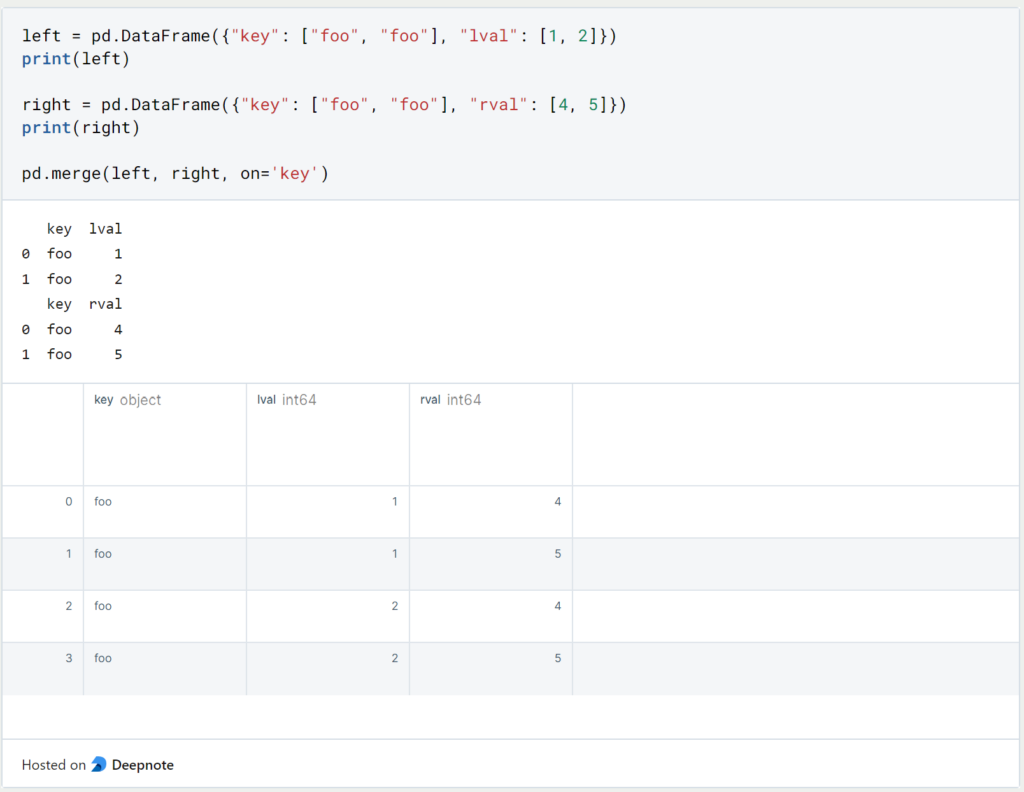
Pandas ermöglicht mit ‘Merge’ zusätzlich auch Join-Möglichkeiten, wie sie den meisten wahrscheinlich aus SQL geläufig sind.
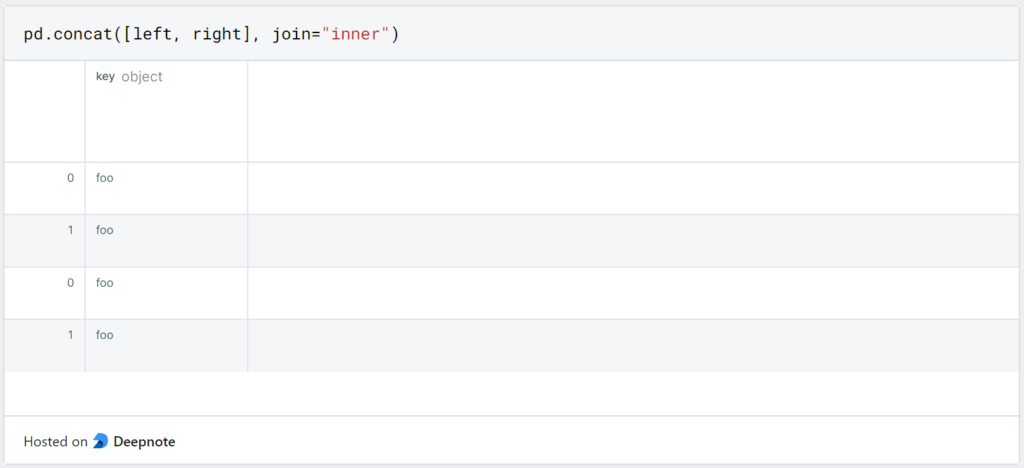
Wenn wir statt Left- bzw. Right Joins einen Inner Join durchführen wollen, nutzen wir wieder den Concat Befehl mit dem Zusatz ‘join = “inner”‘.
Warum sollte man einen Pandas DataFrame benutzen?
Die Verwendung von Pandas Dataframes hat mehrere Vorteile:
- Einfache Datenmanipulation: Pandas-Dataframes bieten eine einfache Möglichkeit, Daten zu manipulieren. Sie können mit Pandas-Dataframes leicht Operationen wie Zusammenführen, Gruppieren und Filtern von Daten durchführen.
- Datenbereinigung: Die Datenbereinigung ist ein wichtiger Schritt in der Datenanalyse. Pandas Dataframes erleichtern die Datenbereinigung, indem sie Funktionen zur Behandlung fehlender Werte, doppelter Datensätze und inkonsistenter Daten bereitstellen.
- Datenvisualisierung: Pandas Dataframes können mit Bibliotheken wie Matplotlib und Seaborn leicht visualisiert werden. Sie können schnell Plots, Diagramme und Graphen erstellen, um Daten zu analysieren und Erkenntnisse zu vermitteln.
- Interoperabilität: Pandas Dataframes lassen sich leicht mit anderen Datenanalysetools und -bibliotheken integrieren, darunter NumPy, Scikit-Learn und TensorFlow.
- Effiziente Speicherverwaltung: Pandas Dataframes sind so konzipiert, dass sie die Speichernutzung effizient verwalten, selbst bei großen Datensätzen. Die Bibliothek ermöglicht das Laden und Verarbeiten von Daten in Chunks, um den Speicherbedarf zu reduzieren.
- Schnelligkeit: Pandas wurde entwickelt, um effizient mit numerischen Operationen auf großen Datensätzen zu arbeiten. Es baut auf NumPy auf, das für numerische Operationen und Vektorisierung optimiert ist, was Pandas Dataframes zu einem schnellen und effizienten Werkzeug für die Datenanalyse macht.
Insgesamt sind Pandas Dataframes ein leistungsfähiges Werkzeug für die Datenanalyse und -manipulation und bieten eine breite Palette von Funktionen und Möglichkeiten, die die Arbeit mit und die Analyse von Daten erleichtern.
Was sind Best Practices bei der Arbeit mit Pandas DataFrames?
Hier sind einige Best Practices und Tipps für die Arbeit mit einem Pandas DataFrame:
- Lese die Dokumentation: Bevor Du mit einem Pandas DataFrame arbeitest, ist es wichtig, die Dokumentation und die Struktur des DataFrames zu verstehen.
- Datenbereinigung und -vorbereitung: Die Datenbereinigung ist einer der wichtigsten Aspekte bei der Arbeit mit einem Pandas DataFrame. Du solltest die Daten immer bereinigen und vorbereiten, bevor Du eine Analyse durchführst. Dies beinhaltet das Entfernen von Duplikaten, den Umgang mit fehlenden Werten und die Konvertierung von Datentypen.
- Indizierung: Die Indizierung ist ein wichtiger Aspekt der Arbeit mit einem Pandas DataFrame. Du kannst Zeilen und Spalten mit Hilfe der Funktionen loc und iloc auswählen. Die loc-Funktion wird für die label-basierte Indizierung verwendet, während die iloc-Funktion für die positionale Indizierung verwendet wird.
- Vermeide die Iteration über Zeilen: Das Iterieren über Zeilen in einem Pandas DataFrame kann langsam und ineffizient sein. Stattdessen sollest Du versuchen, Deine Operationen zu vektorisieren und integrierte Funktionen zu verwenden, die für die Leistung optimiert sind.
- Verwende groupby: Die groupby-Funktion in Pandas ist ein mächtiges Werkzeug für die Datenanalyse. Sie ermöglicht es Dir, Daten nach einer oder mehreren Spalten zu gruppieren und Aggregatfunktionen auf die Gruppen anzuwenden.
- Verwende merge und join: Die Merge- und Join-Funktionen in Pandas werden verwendet, um Datenrahmen zu kombinieren. Mit diesen Funktionen kannst Du Datenrahmen auf der Grundlage einer gemeinsamen Spalte oder eines Indexes kombinieren.
- Verwende die apply-Funktion: Die apply-Funktion in Pandas ermöglicht es Dir, eine Funktion auf jede Zeile oder Spalte eines Datenrahmens anzuwenden. Dies kann nützlich sein, um benutzerdefinierte Berechnungen oder Transformationen auf Ihren Daten durchzuführen.
- Verwende die eingebauten Funktionen: Pandas verfügt über eine breite Palette an eingebauten Funktionen, die auf Leistung optimiert sind. Du solltest immer versuchen, diese Funktionen zu verwenden, anstatt Deine eigenen benutzerdefinierten Funktionen zu schreiben.
- Halte Deine Datentypen konsistent: Es ist wichtig, dass Du Deine Datentypen in einem Pandas DataFrame konsistent hälst. Dadurch wird sichergestellt, dass Deine Daten richtig formatiert sind und keine Fehler auftreten.
- Verwende die richtigen Datenstrukturen: Pandas bietet mehrere Datenstrukturen, darunter Series, DataFrame und Panel. Du solltest die richtige Datenstruktur auf der Grundlage Deiner Daten und der Analyse, die Du durchführst, auswählen.
Das solltest Du mitnehmen
- Pandas bietet viele Möglichkeiten mit Missing Values umzugehen. Man kann die betreffenden Spalten/Zeilen entweder streichen oder die Felder mit einem Wert ersetzen.
- Mit Pandas haben wir dieselben Join Möglichkeiten wie mit SQL.
Vielen Dank an Deepnote für das Sponsoring dieses Artikels! Deepnote bietet mir die Möglichkeit, Python-Code einfach und schnell auf dieser Website einzubetten und auch die zugehörigen Notebooks in der Cloud zu hosten.
Wie Ingenieurteams Build-Fehler durch cloudbasierte Repositories reduzieren
Cloudbasierte Repositories senken die Zahl der Build-Fehler, weil sie eine einheitliche, zentrale und stark automatisierte Umgebung für die Softwareentwicklung bereitstellen. Wenn der Build-Prozess von lokalen Entwicklerrechnern in die Cloud verlegt wird, verschwinden Inkonsistenzen – das bekannte „Auf meinem Rechner funktioniert es“-Problem. Diese Systeme erzwingen standardisierte Build-Konfigurationen, verwalten Abhängigkeiten genau und nutzen strenge Zugriffskontrollen (IAM). So… Weiterlesen »Wie Ingenieurteams Build-Fehler durch cloudbasierte Repositories reduzieren

Python Tutorial für Anfänger
Beherrschen Sie die Grundlagen mit diesem Python Tutorial. Erfahren Sie mehr über Syntax, Datentypen, Kontrollstrukturen und mehr.

Was sind Python Variablen?
Eintauchen in Python Variablen: Erforschen Sie Datenspeicherung, dynamische Typisierung, Scoping und Tipps für effizienten Code.

Was ist Jenkins?
Jenkins beherrschen: Rationalisieren Sie DevOps mit leistungsstarker Automatisierung. Lernen Sie CI/CD-Konzepte und deren Umsetzung.

Python-Tutorial: Bedingte Anweisungen und If/Else Blöcke
Lernen Sie, wie man bedingte Anweisungen in Python verwendet. Verstehen Sie if-else und verschachtelte if- und elif-Anweisungen.

Was ist XOR?
Entdecken Sie XOR: Die Rolle des Exklusiv-Oder-Operators in Logik, Verschlüsselung, Mathematik, KI und Technologie.
Andere Beiträge zum Thema Pandas
- Die offizielle Dokumentation von Pandas findest Du hier.
- Dieser Beitrag baut hauptsächlich auf dem Tutorial von Pandas selbst auf. Dieses findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.