Willkommen zu unserem umfassenden Leitfaden zu Regular Expressions in Python. Reguläre Ausdrücke sind ein leistungsfähiges Werkzeug für den Musterabgleich und die Textmanipulation, mit dem Du Textstrings präzise suchen, extrahieren und manipulieren kannst. Egal, ob Du Anfänger oder erfahrener Python-Programmierer bist, das Verständnis von Regular Expressions kann Deine Textverarbeitungsfähigkeiten erheblich verbessern.
In diesem Artikel werden wir uns mit den Grundlagen regulärer Ausdrücke in Python befassen, lernen, wie man Muster konstruiert, verschiedene Metazeichen und Quantifizierer verwendet und das Modul re in praktischen Szenarien einsetzt.
Was sind Regular Expressions?
Reguläre Ausdrücke in Python sind leistungsstarke Werkzeuge für den Mustervergleich und die Textmanipulation. Sie bieten eine prägnante und flexible Möglichkeit zum Suchen, Extrahieren und Ersetzen von bestimmten Mustern in Zeichenketten von Text. Regular Expressions sind eine Folge von Zeichen, die ein Suchmuster definieren, das aus einer Kombination von Buchstaben, Ziffern, Sonderzeichen und Metazeichen bestehen kann.
In Python werden reguläre Ausdrücke durch das Modul re unterstützt, das eine Reihe von Funktionen und Methoden bereitstellt. Du kannst Aufgaben wie die Validierung von Eingaben, das Extrahieren bestimmter Informationen aus Text, die Durchführung erweiterter Textverarbeitung und vieles mehr durchführen. Reguläre Ausdrücke bieten eine vielseitige und effiziente Lösung für verschiedene textbezogene Herausforderungen in der Python-Programmierung.
Wie findet man grundlegende Muster in Regular Expressions?
Reguläre Ausdrücke bieten eine leistungsstarke und flexible Möglichkeit, Textmuster in Python zu suchen, abzugleichen und zu manipulieren. Im Folgenden werden einige gängige Syntax und grundlegende Muster anhand von Codebeispielen erläutert:
- Literal Matching: Verwende bestimmte Zeichenketten, um exakte Übereinstimmungen zu finden.
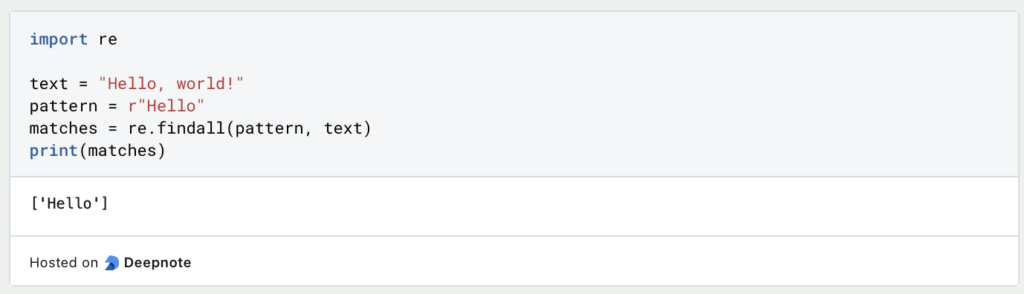
In diesem Beispiel passt der reguläre Ausdruck “Hello” genau auf die Zeichenfolge “Hello” im angegebenen Text.
- Zeichenklassen: Entspricht einem beliebigen Zeichen aus einer Gruppe mit eckigen Klammern.
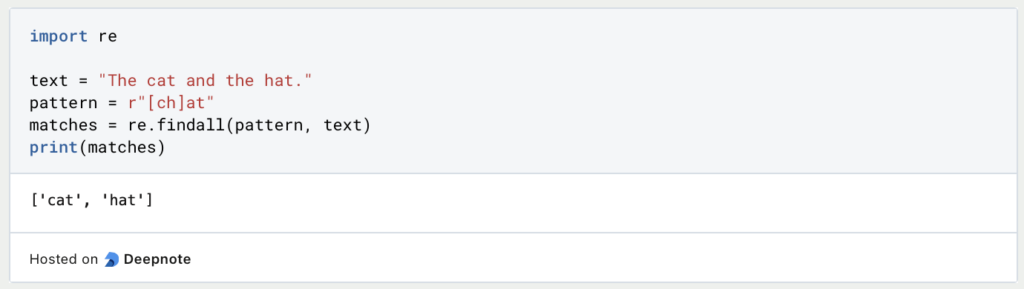
Hier entspricht das Muster [ch]at entweder “cat” oder “hat”, da die Zeichenklasse [ch] entweder “c” oder “h” zulässt.
- Platzhalter: Entspricht einem beliebigen Zeichen (außer einem Zeilenumbruch) unter Verwendung eines Punktes (.).
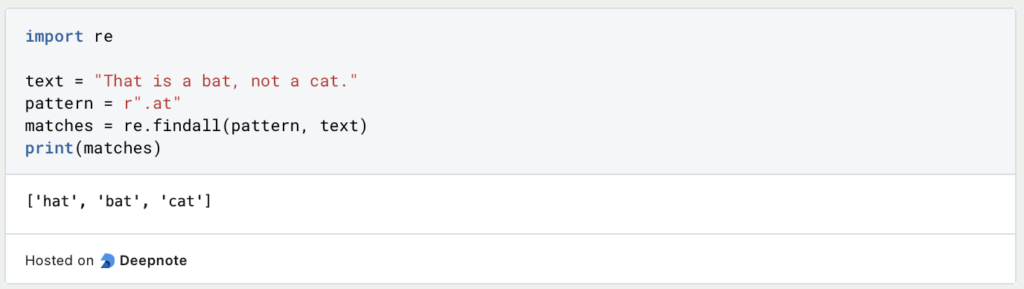
Das Muster . entspricht einem beliebigen Zeichen, und at entspricht einem “at” nach einem beliebigen Zeichen.
- Quantifizierer: Mehrere Vorkommen eines Musters abgleichen.
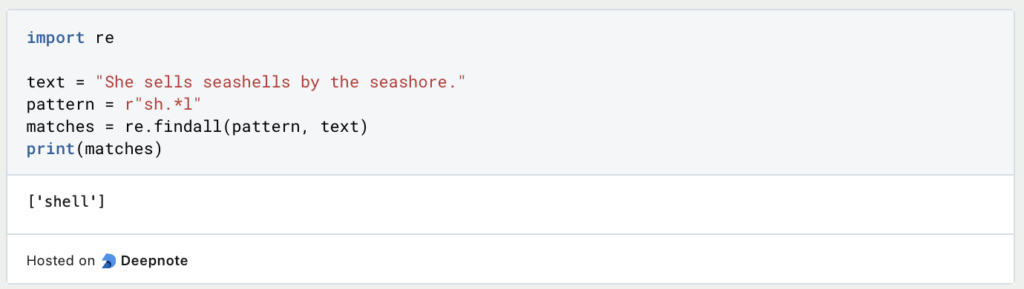
In diesem Beispiel stimmt sh mit “sh” überein und .* stimmt mit jedem Zeichen (.) null oder mehr Mal (*) überein, gefolgt von “l”.
- Verankerung: Übereinstimmungen am Anfang oder Ende einer Zeile.
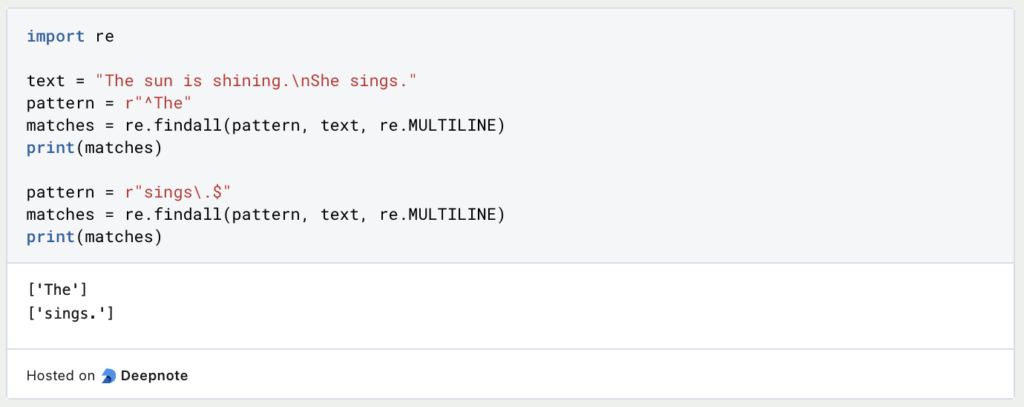
Das Muster ^The passt zu “The” am Anfang einer Zeile, während sings.$ zu “sings.” am Ende einer Zeile passt. Das Flag re.MULTILINE ermöglicht den mehrzeiligen Abgleich.
Diese Beispiele zeigen die grundlegende Syntax und die Muster der regulären Ausdrücke. Mit regulären Ausdrücken kannst Du fortgeschrittene Textmanipulationsaufgaben in Python effizient durchführen.
Wie verwendet man Übereinstimmungen und Suchvorgänge?
In Python bietet das Modul re Funktionen zum Abgleichen und Suchen nach Mustern mit regulären Ausdrücken. Im Folgenden wird anhand von Beispielen gezeigt, wie Du Such- und Abgleichsoperationen durchführen kannst:
- Übereinstimmen: Verwende die Funktion
match(), um zu prüfen, ob ein Muster am Anfang einer Zeichenkette übereinstimmt.
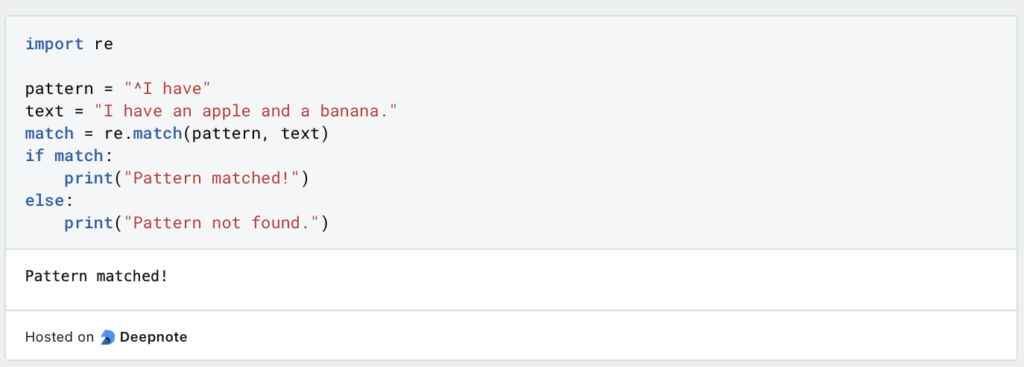
In diesem Beispiel wird das Muster am Anfang der Zeichenkette gefunden, so dass die Ausgabe “Muster gefunden!” lautet.
- Suchen: Verwende die Funktion
search(), um das erste Vorkommen eines Musters in einer Zeichenkette zu finden.
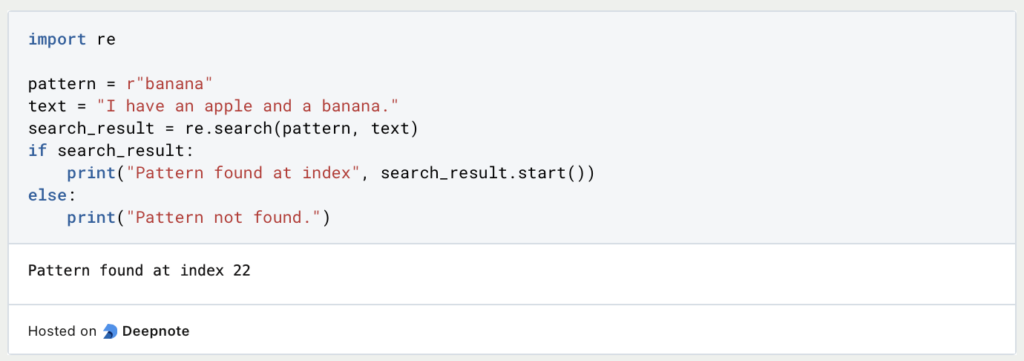
Hier wird das Muster Banane in der Zeichenkette gefunden, und die Ausgabe lautet “Muster gefunden bei Index 22”.
- findall: Verwende die Funktion
findall(), um alle Vorkommen eines Musters in einer Zeichenkette zu finden.
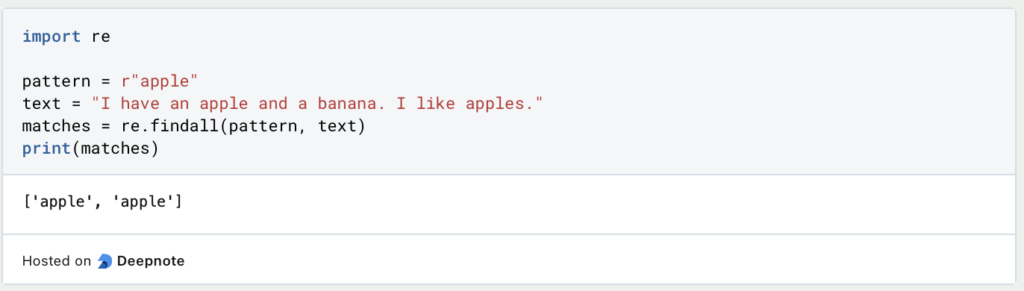
In diesem Beispiel wird das Muster apple zweimal in der Zeichenkette gefunden, und die Ausgabe lautet ['apple', 'apple'].
- Find Iter: Verwende die Funktion
finditer(), um alle Vorkommen eines Musters zu finden und über die entsprechenden Objekte zu iterieren.
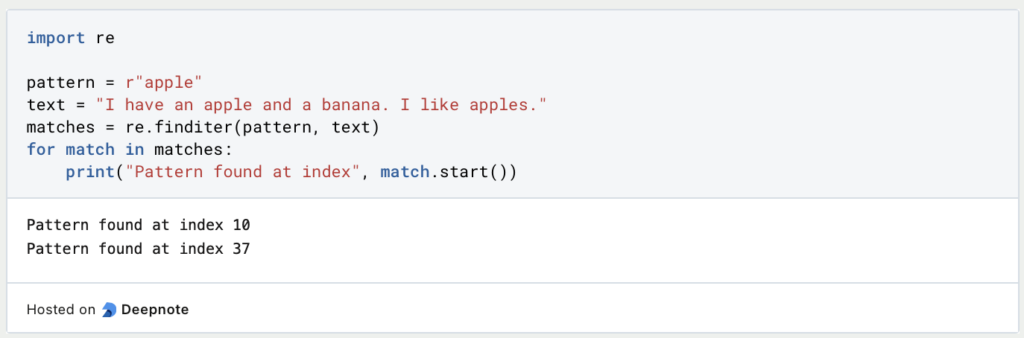
Here, the pattern apple is found twice, and the start index of each match is printed.
Diese Beispiele zeigen, wie man mit regulären Ausdrücken Übereinstimmungen und Suchvorgänge in Python durchführen kann. Das Modul re bietet leistungsstarke Funktionen, um mit Mustern zu arbeiten und Text effektiv zu manipulieren.
Was sind Metazeichen und spezielle Sequenzen?
In regulären Ausdrücken werden Metazeichen und spezielle Sequenzen verwendet, um Muster mit bestimmten Bedeutungen zu definieren. Diese Elemente erhöhen die Flexibilität und Leistungsfähigkeit der regulären Ausdrücke. Im Folgenden werden einige häufig verwendete Metazeichen und spezielle Sequenzen anhand von Beispielen erläutert:
- Meta-Zeichen:
.(Punkt): Passt auf jedes einzelne Zeichen außer einem Zeilenumbruch.
^(Caret): Passt auf den Anfang einer Zeichenfolge.
$(Dollarzeichen): Passt auf das Ende einer Zeichenfolge.
[](eckige Klammern): Passt auf jedes einzelne Zeichen innerhalb der Klammern.
|(Pipe): Wirkt wie ein ODER-Operator und erlaubt mehrere Alternativen in einem Muster.
()(Klammern): Gruppiert Muster und fängt den übereinstimmenden Inhalt ein.
Beispiel:
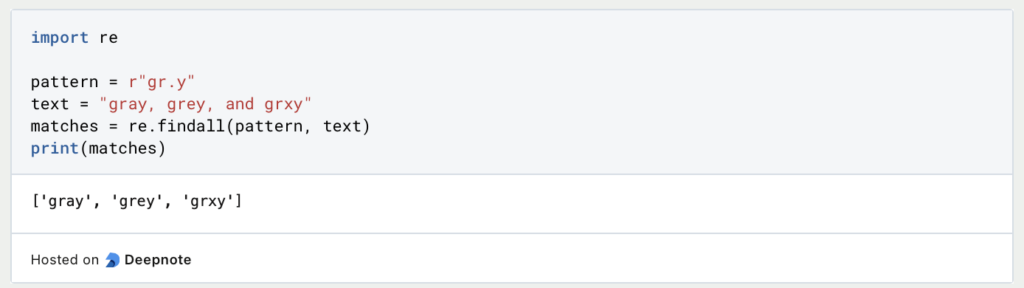
In diesem Beispiel stimmt das Muster gr.y mit Wörtern überein, die “gr” gefolgt von einem beliebigen Zeichen und dann “y” enthalten. Es passt zu “gray” und “grey”, und auch zu “grxy”.
- Spezielle Sequenzen:
d: Entspricht einer beliebigen Ziffer (entspricht [0-9]).w: Entspricht einem beliebigen alphanumerischen Zeichen (entspricht [a-zA-Z0-9_]).s: Entspricht einem beliebigen Leerzeichen (Leerzeichen, Tabulatoren, Zeilenumbrüche).b: Stimmt mit einer Wortgrenze überein.A: Passt nur am Anfang einer Zeichenkette.Z: Findet nur am Ende einer Zeichenfolge statt.
Beispiel:
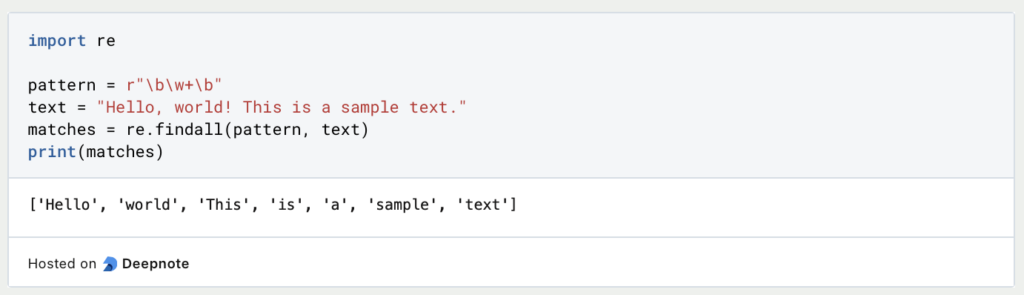
In diesem Beispiel passt das Muster bw+b auf ganze Wörter im Text. Es extrahiert “Hallo”, “Welt”, “Dies”, “ist”, “a”, “Probe” und “Text”.
Das Verständnis von Metazeichen und speziellen Sequenzen ermöglicht einen präziseren Musterabgleich und die Manipulation von Text mit regulären Ausdrücken in Python. Experimentiere mit verschiedenen Kombinationen, um leistungsfähige und vielseitige Muster für Deine speziellen Anforderungen zu erstellen.
Wie verwendet man Gruppieren und Erfassen?
Mit Regular Expressions kannst Du durch Gruppieren und Erfassen bestimmte Teile eines übereinstimmenden Musters angeben und extrahieren. Die Gruppierung erfolgt mit Klammern () und ist nützlich, um Quantifizierer und Modifizierer auf eine Gruppe von Zeichen anzuwenden. Mit Capturing kannst Du den übereinstimmenden Inhalt von bestimmten Gruppen extrahieren. Lasse uns die Funktionsweise von Gruppieren und Erfassen anhand einiger Beispiele untersuchen:
Beispiel 1: Gruppierung mit Quantifizierern
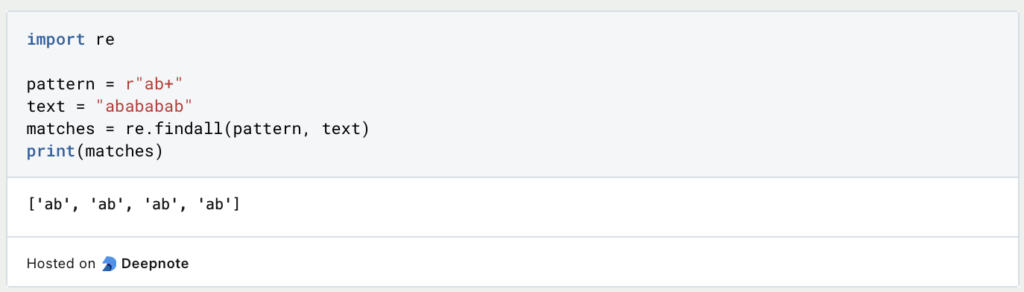
In diesem Beispiel passt das Muster (ab)+ auf ein oder mehrere Vorkommen der Gruppe ab. Es erfasst und gibt jede übereinstimmende Gruppe als separates Element im Ergebnis zurück.
Beispiel 2: Erfassen mit Klammern
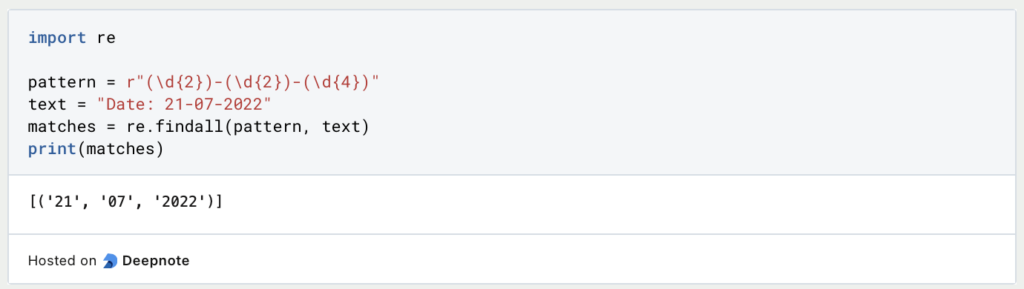
In diesem Beispiel werden mit dem Muster (d{2})-(d{2})-(d{4}) Gruppen von zwei durch Bindestriche getrennten Ziffern erfasst. Die übereinstimmenden Gruppen (’21’, ’07’, ‘2022’) werden als Tupel zurückgegeben.
Gruppierung und Erfassung ermöglichen es Dir, bestimmte Teile des übereinstimmenden Textes zu strukturieren und zu extrahieren. Sie sind für die Durchführung komplexerer Mustervergleiche und Datenextraktionsaufgaben unerlässlich. Durch die Verwendung von Klammern zur Definition von Gruppen und den Zugriff auf den erfassten Inhalt können Sie bei Ihren Operationen mit regulären Ausdrücken präzisere und gezieltere Ergebnisse erzielen.
Wie verwendet man Modifikatoren und Flaggen?
Modifikatoren und Flags in regulären Ausdrücken sind spezielle Optionen, die das Verhalten des Mustervergleichsprozesses verändern. Sie ermöglichen es Dir, Aspekte wie Groß- und Kleinschreibung, mehrzeiligen Abgleich und die Interpretation von Sonderzeichen zu steuern. Sehen wir uns nun einige häufig verwendete Modifikatoren und Flags in Python an:
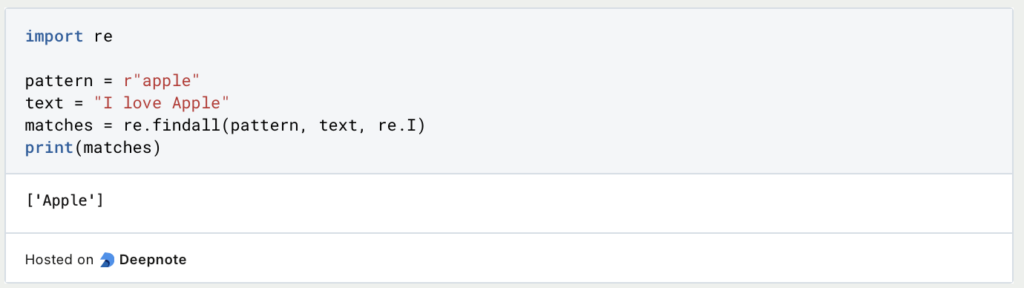
- Groß-/Kleinschreibungs-Unempfindlichkeit (re.I):
Dasre.I-Flag ermöglicht den Abgleich ohne Berücksichtigung der Groß- und Kleinschreibung. Damit wird das Muster unabhängig von der Groß- oder Kleinschreibung abgeglichen. Beispiel:
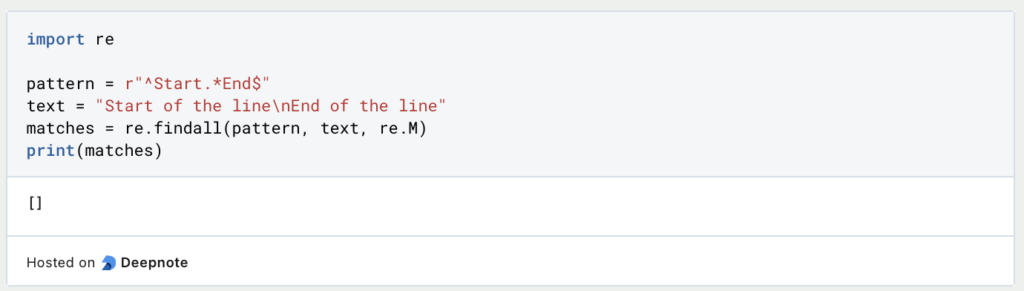
- Multiline Matching (re.M):
Das Flagre.Maktiviert den mehrzeiligen Abgleich. Damit kann das Muster über mehrere Zeilen hinweg abgeglichen werden, wobei die Start- (^) und Endanker ($) für jede Zeile berücksichtigt werden. Beispiel:
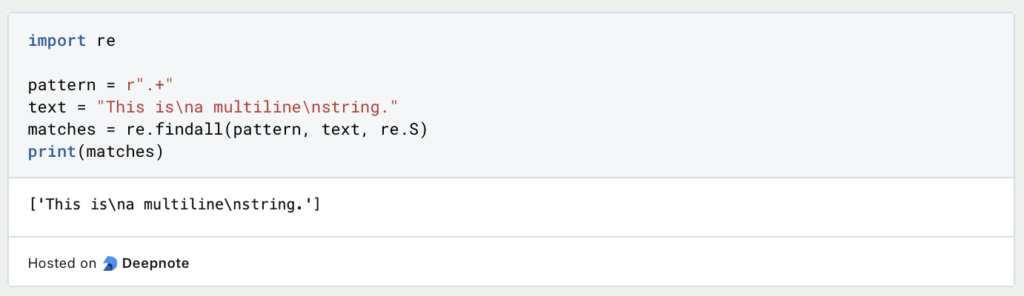
- Dot All Matching (re.S):
Das Flagre.Saktiviert die Punkt-Alles-Übereinstimmung. Es erlaubt, dass das Metacharakter Punkt (.) mit jedem Zeichen übereinstimmt, einschließlich Zeilenumbruch (n). Beispiel:
Modifikatoren und Flags bieten zusätzliche Flexibilität und Kontrolle über den Abgleich regulärer Ausdrücke. Durch die Anwendung der entsprechenden Modifikatoren können Sie das Verhalten des Mustervergleichs an Ihre spezifischen Anforderungen anpassen.
Was sind gängige Anwendungen für Regular Expressions?
Reguläre Ausdrücke sind in verschiedenen Bereichen weit verbreitet, um Mustervergleiche und Textmanipulationen durchzuführen. Hier sind einige häufige Anwendungen von regulären Ausdrücken:
- Datenüberprüfung: Reguläre Ausdrücke werden häufig verwendet, um Dateneingabeformate zu validieren und zu erzwingen. Sie können sicherstellen, dass die vom Benutzer bereitgestellten Daten, wie E-Mail-Adressen, Telefonnummern oder Kreditkartennummern, bestimmten Mustern und Kriterien entsprechen.
- Textsuche und -extraktion: Regular Expressions ermöglichen effiziente Textsuch- und Extraktionsvorgänge. Sie können verwendet werden, um bestimmte Muster oder Schlüsselwörter in einem Dokument zu finden, relevante Informationen aus unstrukturiertem Text zu extrahieren oder Protokolldateien nach bestimmten Datenpunkten zu durchsuchen.
- Datenbereinigung und -umwandlung: Reguläre Ausdrücke sind für Aufgaben der Datenbereinigung und -umwandlung von großem Nutzen. Sie können helfen, unerwünschte Zeichen zu entfernen, Formatierungsinkonsistenzen zu korrigieren und bestimmte Informationen aus Rohdaten zu extrahieren. Du kannst reguläre Ausdrücke zum Beispiel verwenden, um unübersichtliche Datensätze zu bereinigen oder Daten von einem Format in ein anderes zu konvertieren.
- Web Scraping: Regular Expressions spielen eine entscheidende Rolle beim Web Scraping, bei dem Daten aus Websites extrahiert werden. Sie können verwendet werden, um bestimmte HTML-Elemente oder Muster auf Webseiten zu finden und zu extrahieren, was eine automatische Datenextraktion und -analyse ermöglicht.
- Textverarbeitung und Verarbeitung natürlicher Sprache (NLP): Reguläre Ausdrücke sind für die Textverarbeitung und NLP-Aufgaben unerlässlich. Sie können bei der Tokenisierung, dem Stemming, der Entfernung von Stoppwörtern, der Identifizierung von Satzgrenzen und der Durchführung verschiedener linguistischer Analysen von Textdaten helfen.
- Code-Refactoring: Reguläre Ausdrücke sind wertvolle Werkzeuge für Code-Refactoring-Aufgaben. Sie können dazu beitragen, Such- und Ersetzungsvorgänge zu automatisieren, wodurch es einfacher wird, Codemuster zu ändern, Variablennamen zu aktualisieren oder große Codebasen effizient zu überarbeiten.
- Syntaxhervorhebung und lexikalische Analyse: Regular Expressions werden häufig in Texteditoren und Programmiertools zur Syntaxhervorhebung und lexikalischen Analyse verwendet. Sie können verschiedene Codeelemente wie Schlüsselwörter, Zeichenketten, Kommentare und Variablen auf der Grundlage vordefinierter Muster identifizieren und hervorheben.
Regular Expressions bieten eine leistungsstarke und flexible Möglichkeit, mit Textdaten zu arbeiten. Ihre Anwendungen erstrecken sich über mehrere Bereiche, von der Datenvalidierung und -manipulation bis hin zu Web Scraping, Textverarbeitung und Code-Refactoring. Wenn Du reguläre Ausdrücke beherrschst, kannst Du Deine Fähigkeit verbessern, komplexe textbezogene Aufgaben effektiv zu bewältigen.
Das solltest Du mitnehmen
- Regular Expressions sind leistungsstarke Werkzeuge für den Musterabgleich und die Textmanipulation.
- Sie finden Anwendung bei der Datenvalidierung, Textsuche, Datenbereinigung, Web Scraping und vielem mehr.
- Regular Expressions ermöglichen eine effiziente Textverarbeitung und Code-Refactoring.
- Sie sind in Bereichen wie der Datenanalyse, der Verarbeitung natürlicher Sprache und der Webentwicklung weit verbreitet.
- Wenn Du Regular Expressions beherrschst, kannst Du Deine Fähigkeit verbessern, komplexe textbezogene Aufgaben effektiv zu bewältigen.
- Regular Expressions sind eine wesentliche Fähigkeit für jeden, der mit Textdaten in Python oder anderen Programmiersprachen arbeitet.
Vielen Dank an Deepnote für das Sponsoring dieses Artikels! Deepnote bietet mir die Möglichkeit, Python-Code einfach und schnell auf dieser Website einzubetten und auch die zugehörigen Notebooks in der Cloud zu hosten.

Python Tutorial für Anfänger
Beherrschen Sie die Grundlagen mit diesem Python Tutorial. Erfahren Sie mehr über Syntax, Datentypen, Kontrollstrukturen und mehr.

Was sind Python Variablen?
Eintauchen in Python Variablen: Erforschen Sie Datenspeicherung, dynamische Typisierung, Scoping und Tipps für effizienten Code.

Was ist Jenkins?
Jenkins beherrschen: Rationalisieren Sie DevOps mit leistungsstarker Automatisierung. Lernen Sie CI/CD-Konzepte und deren Umsetzung.

Python-Tutorial: Bedingte Anweisungen und If/Else Blöcke
Lernen Sie, wie man bedingte Anweisungen in Python verwendet. Verstehen Sie if-else und verschachtelte if- und elif-Anweisungen.

Was ist XOR?
Entdecken Sie XOR: Die Rolle des Exklusiv-Oder-Operators in Logik, Verschlüsselung, Mathematik, KI und Technologie.

Wie kannst Du die Ausnahmebehandlung in Python umsetzen?
Die Kunst der Ausnahmebehandlung in Python: Best Practices, Tipps und die wichtigsten Unterschiede zwischen Python 2 und Python 3.
Andere Beiträge zum Thema Regular Expressions
Dieser Link führt Dich zu meiner Deepnote-App, in der Du den gesamten Code findest, den ich in diesem Artikel verwendet habe, und ihn selbst ausführen kannst.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.