Die Abkürzung ARIMA steht für den AutoRegressive Integrated Moving Average und bezeichnet eine Klasse von statistischen Modellen, die für die Analyse von Zeitreihendaten verwendet wird. Mithilfe dieses Modells können Vorhersagen über die zukünftige Entwicklung der Daten getroffen werden, die zum Beispiel im wissenschaftlichen oder technischen Bereich zum Einsatz kommen. Die ARIMA-Methode kommt vor allem dann zum Einsatz, wenn eine sogenannte zeitliche Autokorrelation vorhanden ist, also einfach gesagt, die Zeitreihe eine Tendenz aufweist.
In diesem Artikel erklären wir alle Aspekte im Zusammenhang mit ARIMA Modellen und beginnen dabei ganze einfach mit einer Einführung in Zeitreihendaten und deren Besonderheiten, bis wir zum Ende des Beitrags ein eigenes Modell in Python trainieren und ausführlich bewerten.
Was sind Zeitreihendaten?
Bei Zeitreihendaten handelt es sich um eine besondere Form von Datensatz, bei dem die Messung in regelmäßigen, zeitlichen Intervallen stattgefunden hat. Dadurch hat eine solche Datensammlung eine weitere Dimension, die bei anderen Datensätzen fehlt, nämlich die zeitliche Komponente. Zeitreihendaten kommen beispielsweise in der Finanz- und Wirtschaftsbranche vor oder in den Naturwissenschaften, wenn die zeitliche Veränderung eines Systems gemessen wird.
Bei der Visualisierung von Zeitreihendaten zeigen sich häufig eines oder mehrere Merkmale, die typisch für diese Art von Daten sind:
- Trends: Ein Trend beschreibt ein langfristiges Muster der Daten, sodass die Messpunkte in einem längeren Zeitraum entweder steigen oder sinken. Dies bedeutet, dass trotz kurzfristiger Schwankungen eine übergeordnete Marschrichtung erkennbar ist. Ein gesundes Unternehmen beispielsweise verzeichnet über mehrere Jahre hinweg einen Umsatzwachstum, obwohl es möglicherweise in einzelnen Monaten auch Umsatzrückgänge verzeichnen muss.
- Saisonalität: Als Saisonalität bezeichnet man wiederkehrende Muster, welche in festen Zeitabständen auftreten und sich somit wiederholen. Die Dauer und Häufigkeit der Saisonalität ist dabei abhängig vom Datensatz. Somit können sich bestimmte Muster beispielsweise täglich, stündlich oder jährlich wiederholen. Die Nachfrage nach Eis unterliegt zum Beispiel einer großen Saisonalität und nimmt im Sommer meist stark zu, während sie im Winter hingegen abnimmt. Dieses Verhalten wiederholt sich somit jedes Jahr. Die Saisonalität zeichnet sich dadurch aus, dass sie in festen Rahmen auftritt und deshalb einfach vorherzusagen ist.
- Zyklus: Zyklen sind zwar auch Schwankungen in den Daten, jedoch treten diese nicht so regelmäßig auf wie saisonale Änderungen und sind oft längerfristiger Natur. Bei wirtschaftlichen Zeitreihen hängen diese Schwankungen häufig mit wirtschaftlichen Zyklen zusammen. In der Phase eines wirtschaftlichen Aufschwungs beispielsweise wird ein Unternehmen ein deutlich stärkeres Wirtschaftswachstum verzeichnen als während einer Rezession. Jedoch ist das Ende eines solchen Zyklus nicht so einfach vorherzusagen, wie das Ende einer Saison.
- Ausreißer: Unregelmäßige Muster in Zeitreihendaten, die weder einer Saisonalität noch einem Trend folgen, werden als Ausreißer bezeichnet. In vielen Fällen hängen diese Schwankungen mit äußeren Umständen zusammen, die nicht oder nur sehr schwer kontrollierbar sind. Diese Änderungen erschweren eine akkurate Vorhersage von zukünftigen Entwicklungen. Eine plötzliche Naturkatastrophe kann zum Beispiel negative Auswirkungen auf die Umsatzzahlen des Unternehmens haben, da Lieferwege überflutet sind.
- Autokorrelation: Die Autokorrelation beschreibt das Phänomen, wenn vergangene Datenpunkte einer Messreihe mit zukünftigen Daten korreliert sind, also voneinander abhängen. Diese Abhängigkeit kann bei der Prognose von neuen Werten helfen. Eine Messreihe von Temperaturwerten besitzt eine Autokorrelation, da die aktuelle Temperatur von der Temperatur vor zwei Minuten abhängt.
Was ist ARIMA?
ARIMA-Modelle (AutoRegressive Integrated Moving Average) sind statistische Methoden zur Analyse von Zeitreihendaten und zur Vorhersage von zukünftigen Werten. Sie sind in der Lage die zeitlichen Strukturen, die sich ergeben haben, zu erkennen und in die Prognosen mit einzubeziehen.
Die Abkürzung beschreibt bereits die drei Hauptkomponenten, aus denen sich das Modell zusammensetzt. Diese Komponenten werden im Folgenden genauer erklärt und anhand des Beispiels einer Umsatzprognose veranschaulicht.
Autoregression (AR): Die Autoregressive Komponente (AR) des Modells nutzt die vergangenen Werte, um zukünftige Prognosen zu treffen. Dadurch wird das Ausmaß der zurückliegenden Datenpunkte direkt für die Schätzung berücksichtigt und dadurch die Autokorrelation berücksichtigt.
- Beispiel: Bei der Vorhersage der zukünftigen Umsatzentwicklung kann es wichtig sein die Muster und Trends aus den vorangegangenen Perioden zu berücksichtigen, um deren Informationen mit einzubeziehen. Wenn der Umsatz in den letzten drei Monaten gestiegen ist, könnte das AR-Element einen Hinweis darauf geben, dass die Umsätze in diesem Monat auch steigen, da aktuell ein Aufwärtstrend vorliegt.
- Modell: Im ARIMA-Modell wird die Autoregressive Komponente durch die Variable \( p \) gekennzeichnet, die auch Lag genannt wird. Dieser Parameter definiert, wie viele vorangegangene Perioden für die Vorhersage des nächsten Wertes benutzt werden. Ein Modell mit \( p = 2 \) nutzt also die beiden vorherigen Monate, um den Umsatz im kommenden Monat abzuschätzen.
Integriert (I): Die I-Komponente steht für „integriert“ und bezieht sich auf den Prozess der Differenzierung. In vielen Zeitreihendaten sorgen Trends und Muster dafür, dass die Werte nicht stationär sind, also ihre statistischen Eigenschaften, wie beispielsweise den Mittelwert oder die Varianz, über die Zeit verändern. Die Stationarität ist jedoch eine grundlegende Eigenschaft, um leistungsfähige, statistische Modelle zu trainieren. Deshalb kann die Differenzierung helfen, jegliche Trends und Muster aus den Daten zu entfernen, um den Datensatz stationär zu machen.
- Beispiel: Wenn sich im Umsatz ein steigendes Muster erkennen lässt, kann es hilfreich sein die Werte zu differenzieren und somit nur die Änderungen von Monat zu Monat zu betrachten, statt die absoluten Werte. Dadurch ist es einfacher das zugrundeliegende Muster zu erkennen und es zu quantifizieren.
- Modell: Im Model selbst wird der Parameter \( d \) verwendet und gibt an, wie oft die Differenzierung angewendet werden muss, um die Daten stationär zu machen. Ein Modell mit \(d = 1 \) muss entsprechend einmal differenziert werden. In vielen Fällen reicht eine einfache Differenzierung aus, um den Datensatz stationär zu machen.
Moving Average (MA): Der Moving Average, oder auf Deutsch „gleitender Durchschnitt“, bezieht sich auf die Abhängigkeit von Fehlern oder Residuen über den zeitlichen Verlauf hinweg. Diese Komponente berücksichtigt also, welche Fehler bei der Vorhersage von früheren Werten aufgetreten sind, und bezieht sie in die aktuelle Schätzung mit ein. Ansonsten könnte sich ein großer Fehler in einem Monat negativ auf die folgenden Monate auswirken und noch weiter ansteigen.
- Beispiel: Wenn der Umsatz im aktuellen Monat als zu hochgeschätzt wurde, sollte dieser Fehler für die weitere Vorhersage mit einbezogen werden, damit die aktuelle Vorhersage davon nicht betroffen ist und auch als zu hoch eingeschätzt wird.
- Modell: Mithilfe des Parameters \( q \) kann definiert werden, wie viele vorherige Fehler für die aktuelle Schätzung mitberücksichtigt werden.
Das ARIMA-Modell ist eine leistungsstarke Methode, welche sich aus drei Hauptkomponenten zusammensetzt und dabei die vergangenen Werte, die Stationarität der Daten, sowie die vorangegangenen Fehler in die Schätzung mit einbezieht.
Was bedeutet Stationarität von Daten?
In der Zeitreihenanalyse spielt die sogenannte Stationarität eine entscheidende Rolle, da sie von vielen Modellen, wie beispielsweise dem ARIMA-Modell vorausgesetzt wird. Viele Zeitreihen enthalten zugrundeliegende Muster und Trends, wie beispielsweise einen kontinuierlichen Anstieg, die dafür sorgen, dass sich die statistischen Eigenschaften, wie der Mittelwert oder die Varianz, über die Zeit hinweg verändern. Um belastungsfähige Vorhersagen zu erreichen, muss jedoch dafür gesorgt werden, dass der Datensatz stationäre Eigenschaften besitzt, weshalb wir uns in diesem Abschnitt genauer mit dem Konzept beschäftigen.
Eine Zeitreihe ist dann stationär, wenn die statistischen Eigenschaften über den zeitlichen Verlauf hinweg konstant bleiben. Dabei werden vor allem die folgenden Kennwerte betrachtet:
- Konstanter Mittelwert: Der arithmetische Mittelwert des Datensatzes muss über den zeitlichen Verlauf hinweg konstant bleiben und sollte entsprechend weder ansteigen noch abfallen.
- Konstante Varianz: Die Streuung um den Mittelwert ist im zeitlichen Verlauf immer gleich groß. Die Daten liegen also nicht mal näher und mal weiter entfernt vom Mittelwert.
- Konstante Autokorrelation: Die Korrelation zwischen zwei verschiedenen Datenpunkten hängt ausschließlich vom Abstand der beiden Punkte ab und nicht von der Zeit.
Nur wenn diese Eigenschaften erfüllt sind, kann davon ausgegangen werden, dass vorangegangene Muster auch zukünftige Muster zuverlässig vorhersagen, denn bei einer stationären Zeitreihe bleiben auch die Beziehungen zwischen den Datenpunkten über die Zeit hinweg stabil.
Für die Prüfung der Stationarität kann im ersten Schritt eine einfache visuelle Darstellung der Daten helfen, um Trends oder Muster zu erkennen, die eine Stationarität verhindern. Wenn man hingegen beispielsweise eine Saisonalität der Zeitreihe erkennt, dann sind die Daten eindeutig nicht stationär. Um jedoch sicher zu gehen, kann zusätzlich auch der sogenannte Augmented Dickey-Fuller Test (ADF-Test) verwendet werden.
Falls die Zeitreihe sich als nicht stationär entpuppt, muss sie erst stationär gemacht werden, um statistische Modelle, wie beispielsweise ARIMA, verwenden zu können. Eine der effektivsten Methoden dafür ist die Differenzierung. Bei diesem Prozess werden die Differenzen zwischen aufeinanderfolgenden Datenpunkten berechnet, um dadurch den zugrundeliegenden Trend aus den Daten zu entfernen. Dadurch werden nicht mehr die absoluten Werte der Zeitreihe betrachtet, sondern deren Veränderungen.
Die erste Differenzierung lässt sich mithilfe der folgenden Formel berechnen:
\(\)\[ y_t^\prime=y_t-y_{t-1} \]
In manchen Fällen kann eine einzige Differenzierung nicht ausreichen und es muss mehrfach differenziert werden. Dazu wird dasselbe Vorgehen mit den bereits differenzierten Werten wiederholt, bis die Stationarität der Daten gegeben ist.
Wie baut man ein ARIMA Modell?
Nachdem wir uns den Aufbau des ARIMA-Modells genauer angeschaut haben, können wir nun beginnen das Modell zu bauen. Im Mittelpunkt stehen dabei die drei Hauptkomponenten und die Wahl der richtigen Größe für deren Parameter. Nur wenn diese richtig gewählt sind, kann ein gutes und leistungsfähiges Modell trainiert werden.
Folgende Parameter müssen anhand des Datensatzes richtig gewählt werden:
- Der Parameter \(p \) (Autoregressive Ordnung) bestimmt die Anzahl der Lags, welche für die Autoregression beachtet werden müssen. Bei \( p = 2 \) werden beispielsweise die letzten beiden Datenpunkte für die Vorhersage des zukünftigen Wertes verwendet.
- Der Parameter \( d \) (Differenzierung) legt fest, wie oft die Zeitreihe differenziert werden muss, damit der Datensatz stationär ist, also die statistischen Kennzahlen konstant sind. Üblicherweise kann hier \( d = 1 \) gesetzt werden, da in vielen Fällen eine Differenzierung ausreicht, um Trends und Muster zu entfernen und dadurch die Zeitreihe stationär zu gestalten.
- Der Parameter \( q \) (Moving Average Ordnung) definiert die Anzahl der vergangenen Fehler, die im Modell verwendet werden.
Um die richtigen Werte für die Parameter \(p\) und \(q\) zu finden, können grafische Werkzeuge verwendet werden, die bei der Wahl hilfreich sein können.
Autokorrelationsfunktion (ACF)
Diese Funktion zeigt die Korrelation einer Zeitreihe mit den verschiedenen Lags an. Dadurch lässt sich grafisch erkennen, ob und wie stark ein Wert in der Zeitreihe mit den vorangegangenen Lags korreliert ist.

Wenn die Korrelation nur langsam abfällt, wie in dem obigen Graph, dann kann dies ein Hinweis darauf sein, dass ein Modell mit einem bestimmten \(p\)-Wert geeignet sein kann, der anhand der nachfolgenden Funktion genauer gewählt werden kann. Wenn es jedoch einen starken Abfall zwischen zwei Lags geben würde, dann würde dies für ein Moving Average Modell sprechen.
Partielle Autokorrelationsfunktion (PACF)
Die PACF zeigt die partielle Korrelation zwischen zwei Datenpunkten und hat dabei den Einfluss der dazwischenliegenden Punkte bereits entfernt. Konkret bedeutet dies, dass ein Abbruch im PACF nach ein bestimmten Lag ein guter Indikator für einen ersten \(p\)-Wert ist, der getestet werden kann.

In diesem Graph weisen die ersten beiden Lags eine signifikante Korrelation auf und nach dem zweiten Lag gibt es einen rapiden Absturz. Somit sollte für das Modell basierend auf dem Datensatz der Wert \(p = 2\) gesetzt werden. Dadurch dass die ACF-Funktion nur sehr schwach abfällt, könnte man ein Modell mit \(q = 0\) oder \(q = 1\) testen.
Bevor das Modell trainiert werden kann, müssen die Daten noch stationär gemacht werden. Dazu kann man die Zeitreihe differenzieren und erhält so in vielen Fällen bereits stationäre Daten. Dies sind die wichtigsten Schritte, um ein ARIMA Modell trainieren zu können.
Wie implementiert man das ARIMA-Modell in Python?
Ein ARIMA – Modell kann in Python mithilfe der Bibliothek pmdarima umsetzen, die bereits eine fertige Funktion dafür bietet. In diesem Beispiel verwenden wir den Datensatz „Air Passengers“, welcher eine Zeitreihe zu den monatlichen Passagierzahlen von internationalen Fluggesellschaften enthält. Diesen lesen wir über die URL des zugehörigen Datensatzes von GitHub ein:

Für jeden Monat seit Januar 1949 bis 1960 sehen wir hierfür die Anzahl der Fluggäste und deren Entwicklung:

Um mit den Daten arbeiten zu können, wird die Monatsangabe in eine Datumsangabe umgewandelt, da wir nicht mit einem String umgehen können.

Außerdem wird die Monatsangabe als Index des DataFrames verwendet, um einfacher mit den. Daten arbeiten zu können.

Nachdem die Daten nun ausreichend aufbereitet sind, können wir mithilfe der ACF und PACF-Funktion die Autokorrelation betrachten, um die Parameter festlegen zu können. Wie wir später sehen werden, ist dieser Schritt eigentlich nicht mehr notwendig, da die Funktion auto_arima automatisch die besten Parameter findet, jedoch hilft es, um ein Grundverständnis für die Informationen zu erhalten.
Die beiden Funktionen können mithilfe von Matplotlib und den Modulen aus statsmodels importiert und erstellt werden:

Um nun ein ARIMA-Modell zu instanziieren, nutzen wir die auto_arima Funktion, die automatisch die optimalen Parameter auswählt, indem wir ihr die Daten übergeben. Zusätzlich setzen wir den Parameter seasonal zu true, da wir eine Saisonalität in den Daten erwarten. Der Default-Wert ist an sich auch true, sodass wir es eigentlich nicht zusätzlich definieren müssen. Mit dem Parameter m können die Anzahl der Observationen für einen Cycle definiert werden. Da wir von einer Saisonalität ausgehen, die sich jährlich, also alle zwölf Monate, wiederholt, setzen wir den Parameter m = 12.

Nun wir das instanziierte Modell an die Daten angepasst und die optimalen Parameter werden gefunden. Für unseren Datensatz sind die optimalen Parameter (2, 1, 1), also \(p = 2\), \(d = 1\) und \(q = 1\).

Dieses Modell kann anschließend verwendet werden, um Aussagen zu treffen. Dazu wird die .predict() Funktion genutzt und es wird die Anzahl an Perioden definiert, für die eine Vorhersage getroffen werden soll:

Um die Qualität der Vorhersagen bewerten zu können, können wir uns die grafische Darstellung der Kurve anschauen. Die Vorhersagen scheinen akkurat zu sein, da die Saisonalität fortgeführt wird und auch der Aufwärtstrend in den Passagierzahlen erhalten bleibt.

Mithilfe von diesen einfachen Schritten lässt sich in Python ein ARIMA-Modell trainieren. Durch die automatische Suche der optimalen Parameter, muss lediglich der Datensatz gut aufbereitet werden und möglicherweise noch die Saisonalität eingestellt werden. Zum Abschluss sollte das Modell mit geeigneten Kennzahlen evaluiert werden. Welche dafür in Frage kommen können, sehen wir uns im nächsten Abschnitt genauer an.
Wie kann ein Modell bewertet werden?
Nachdem wir das ARIMA-Modell trainiert haben, ist es entscheidend die Leistungsfähigkeit ausreichend zu bewerten, um sicherzustellen, dass es die zugrundeliegende Zeitreihe gut genug repräsentiert. Um diese Modellbewertung durchzuführen, gibt es verschiedene Kennzahlen und Analysen, die berechnet werden können.
Restanalyse
Bei der Restanalyse geht es darum, die Fehler der Vorhersagen genauer zu untersuchen. Im Optimalfall sind diese wie „weißes Rauschen“ und weisen somit keine systematischen Muster mehr auf. Außerdem hat ein „guter“ Fehler einen Mittelwert von 0.
Mithilfe der bereits vorgestellten Autokorrelationsfunktion (ACF) kann untersucht werden, ob die Residuen eine Korrelation zu den eigenen, vergangenen Werten aufweisen. Die Residuen des Modells erhält man mithilfe von model.resid() und kann diese dann mithilfe von statsmodels in eine Grafik überführen.
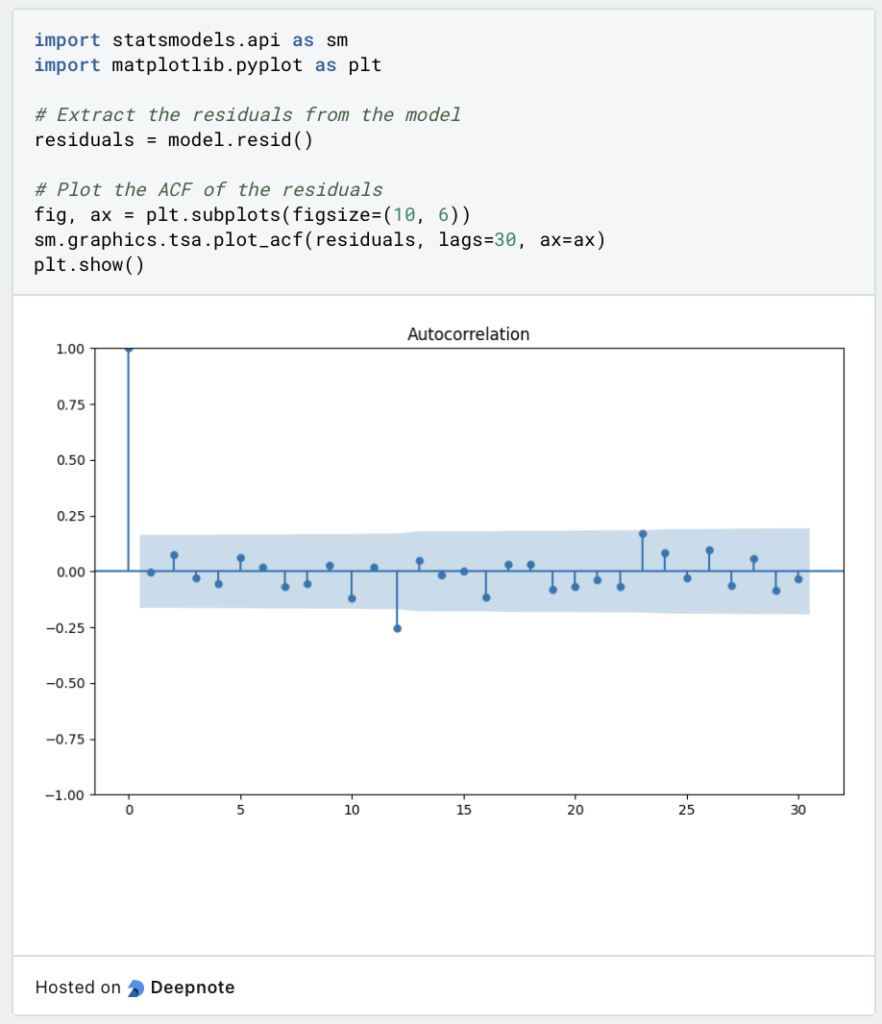
Wie in dem Graph zu sehen ist, gibt es keine wirklich signifikante Autokorrelation zwischen den Residuen.
Validierung des Modells
Zusätzlich kann man ähnlich wie bei anderen Modellen auch, den mittleren quadratischen und den mittleren absoluten Fehler berechnen, um die Genauigkeit der Vorhersagen beurteilen zu können. Ein kleinerer Fehler bedeutet dabei eine höhere Genauigkeit der Vorhersagen.
Dazu wird der Datensatz in Trainings- und Testset aufgesplittet, um überprüfen zu können, wie das Modell auf ungesehene Daten reagiert, die nicht für das Training verwendet wurden. Bei einem kleinen Datensatz bietet sich beispielsweise ein 80/20 Split an, sodass 80 % der Daten für das Training verwendet werden und die übrigen 20 % der Daten für das Testing übrigbleiben.

Im Diagramm ist zu sehen, dass die Vorhersage in Rot dem Verlauf der tatsächlichen Daten ziemlich genau folgt, jedoch die Werte nicht immer ganz genau trifft, sodass auch ein nicht unerheblicher Fehler bestehen bleibt. Für bessere Ergebnisse könnten die Parameter noch weiter optimiert und weitere Trainingsdurchläufe durchgeführt werden.
Was ist das Saisonale ARIMA Modell?
Über die Jahre haben sich einige Erweiterungen von ARIMA ergeben, die das Basismodell nochmals anpassen und für speziellere Anwendungen optimieren. Eine davon ist das SARIMA-Modell, also das Saisonale ARIMA, welches die Möglichkeit bietet, saisonale Muster in der Vorhersage zu berücksichtigen. Dazu gibt es einige zusätzliche Parameter, die diese saisonalen Zyklen einfangen:
- P: Auch hierbei steht der Parameter \(p\) für die autoregressive Ordnung. Jedoch geht es darum, wie sehr frühere saisonale Werte auf aktuelle saisonale Werte Einfluss haben.
- D: Dieser Parameter misst weiterhin, wie oft die Daten differenziert werden müssen, um die Daten stationär und somit frei von saisonalen Trends zu machen.
- Q: Der Parameter \(q\) berücksichtigt die zufälligen Fehler aus früheren saisonalen Perioden.
- S: Dieser Parameter ist neu und beschreibt wie viele Datenpunkte eine einzige Saison enthält.
Das SARIMA-Modell sollte vor allem dann verwendet werden, wenn die Zeitreihen nicht nur Trends unterliegen, sondern auch regelmäßig wiederkehrende Zyklen durchlaufen. Ein Beispiel hierfür könnte zum Beispiel der Energieverbrauch aller Haushalte sein, der saisonalen Schwankungen unterliegt, da beispielsweise im Winter mehr Licht benötigt wird und dadurch mehr Strom als im Sommer verbraucht wird.
In welchen Anwendungen kommt ARIMA zum Einsatz?
ARIMA-Modelle sind eine leistungsfähige Möglichkeit, um Zeitreihen effektiv zu analysieren und vorherzusagen. In verschiedensten Anwendungen wird Wert daraufgelegt, möglichst genaue Vorhersagen über die Zukunft treffen zu können. Zu den populärsten Applikationen von ARIMA zählen beispielsweise:
- Finanzmarkt: Für die Vorhersage von finanziellen Zeitreihen, wie beispielsweise Aktien- oder Währungskursen, werden ARIMA-Modelle eingesetzt.
- Energie- und Versorgungsunternehmen: Um ausreichend Energie für die Kunden bereitstellen zu können, müssen Energieunternehmen bereits frühzeitig eine Abschätzung über die zukünftigen Verbräuche haben. Dafür eignen sich ARIMA-Modelle oder sogar SARIMA-Modelle sehr gut, da sie Saisonalitäten und Trends in die Vorhersage mit einbeziehen können.
- Gesundheit & Medizin: In der Gesundheitsbranche werden Zeitreihen über Krankenfälle oder Krankenhausbesuche analysiert, um das System auf zukünftige Belastungen einzustellen und bereits frühzeitig die entsprechenden Medikamente am Lager zu haben.
- Wettervorhersage: Auch für die Vorhersage von Wettervariablen, wie zum Beispiel Temperatur oder Niederschlag, kommen ARIMA-Modelle zum Einsatz. Diese helfen Meteorologen dabei frühzeitig genaue Vorhersagen treffen zu können und so beispielsweise auch rechtzeitig vor extremen Wetterereignissen warnen zu können.
ARIMA-Modelle sind ein nützliches Tool bei der Analyse von Zeitreihendaten und können in verschiedensten Anwendungen zum Einsatz kommen.
Das solltest Du mitnehmen
- ARIMA steht für den AutoRegressive Integrated Moving Average und ist eine Möglichkeit zur Analyse und Vorhersage von Zeitreihen.
- Für die Verwendung dieser Methode ist es wichtig, dass die Zeitreihe stationär ist, also konstante statistische Kennwerte enthält. Dafür kann die Differenzierung verwendet werden.
- In Python kann unter anderem die Bibliothek
statsmodelsgenutzt werden, um ein ARIMA-Modell zu trainieren. Der Vorteil bei dieser Umsetzung ist, dass automatisch die optimalen Parameter gesetzt werden und diese nicht im Vorhinein bestimmt werden müssen. - Für die Bewertung des Modells kann entweder die sogenannte Restanalyse verwendet werden oder es kann mit einer Kreuzvalidierung die Performance auf dem Testset analysiert werden.
- Für saisonale Daten, die zum Beispiel von den Jahreszeiten abhängen, kann eine Variante von ARIMA, das sogenannte SARIMA-Modell angewendet werden.

Was ist eine Wahrscheinlichkeitsverteilung?
Wahrscheinlichkeitsverteilungen in der Statistik: Lernen Sie die Arten, Anwendungen und Schlüsselkonzepte der Datenanalyse kennen.

Was ist die F-Statistik?
Erforschen Sie die F-Statistik: Ihre Bedeutung, Berechnung und Anwendungen in der Statistik.

Was ist Gibbs-Sampling?
Erforschen Sie Gibbs-Sampling: Lernen Sie die Anwendungen kennen und erfahren Sie, wie sie in der Datenanalyse eingesetzt werden.

Was ist ein Bias?
Auswirkungen und Maßnahmen zur Abschwächung eines Bias: Dieser Leitfaden hilft Ihnen, den Bias zu verstehen und zu erkennen.

Was ist die Varianz?
Die Rolle der Varianz in der Statistik und der Datenanalyse: Verstehen Sie, wie man die Streuung von Daten messen kann.

Was ist die KL Divergence (Kullback-Leibler Divergence)?
Erkunden Sie die Kullback-Leibler Divergence (KL Divergence), eine wichtige Metrik in der Informationstheorie und im maschinellen Lernen.
Andere Beiträge zum Thema ARIMA
Die deutsche Universität Kassel hat eine interessante Arbeit über das ARMA- und das ARIMA-Modell veröffentlicht.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.