Im Bereich der Statistik und Datenanalyse ist das Bestimmtheitsmaß, auch als R-Squared bekannt, ein grundlegendes Konzept. Es spielt eine entscheidende Rolle bei der Bewertung der Stärke und Anpassungsgüte von Regressionsmodellen und ist damit ein unverzichtbares Werkzeug für Forscher, Analysten und Datenwissenschaftler in verschiedenen Bereichen.
In diesem Artikel begeben wir uns auf eine Reise, um die Feinheiten des Bestimmtheitsmaßes zu enthüllen. Wir werden in seine konzeptionellen Grundlagen eintauchen, seine praktischen Anwendungen erkunden und dich mit dem Wissen ausstatten, es effektiv in deinen Datenanalysebemühungen einzusetzen. Ob du ein erfahrener Statistiker oder ein neugieriger Anfänger bist, die Kraft des Bestimmtheitsmaßes liegt in deiner Reichweite und bietet Einblicke, die deine datengesteuerten Entscheidungen prägen können.
Was sind Regressionsmodelle und wie funktionieren sie?
Die Regressionsanalyse in ihren verschiedenen Formen ist ein Eckpfeiler im Bereich der Statistik und Datenanalyse. Sie dient als vielseitiges Werkzeug, das die Lücke zwischen Rohdaten und aussagekräftigen Erkenntnissen in zahlreichen Disziplinen schließt, von Wirtschaft und Finanzen bis hin zur Biologie und darüber hinaus.
Im Wesentlichen ist ein Regressionsmodell eine mathematische Darstellung der Beziehung zwischen einer oder mehreren unabhängigen Variablen und einer abhängigen Variablen. Es bemüht sich, aufzudecken und zu quantifizieren, wie sich Veränderungen in den unabhängigen Variablen auf die abhängige Variable auswirken. Dieses grundlegende Konzept bildet das Rückgrat sowohl linearer als auch nichtlinearer Regressionsmodelle.
Lineare Regression: Ein einfacher Start
Die lineare Regression, die einfachste ihrer Art, untersucht lineare Beziehungen zwischen Variablen. Sie geht davon aus, dass eine gerade Linie die Verbindung zwischen den unabhängigen und abhängigen Variablen treffend erfassen kann. Diese Methode findet in Bereichen wie der Wirtschaft Anwendung, wo sie verwendet wird, um die Beziehung zwischen Einkommen und Ausgaben zu modellieren, oder in der Finanzwelt, um die Verbindung zwischen Zinssätzen und Aktienkursen zu analysieren.
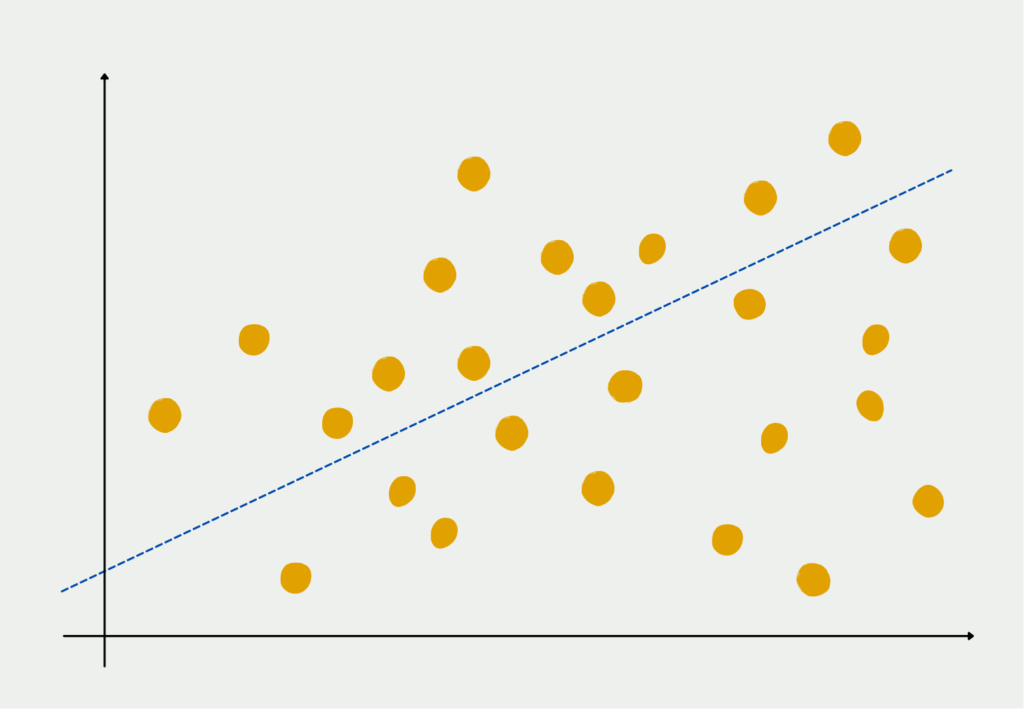
Jenseits der Linearität: Nichtlineare Regression
Die lineare Regression ist zwar ein unschätzbares Hilfsmittel, doch die Beziehungen in der Realität sind nicht immer linear. Hier kommt die nichtlineare Regression ins Spiel, die sich der Komplexität gekrümmter Beziehungen annimmt. Dieser Ansatz berücksichtigt komplizierte, nicht lineare Muster und wird in Bereichen wie der Biologie eingesetzt, wo er bei der Modellierung von Bevölkerungswachstumskurven hilft, oder in der Umweltwissenschaft, um das Verhalten ökologischer Systeme vorherzusagen.
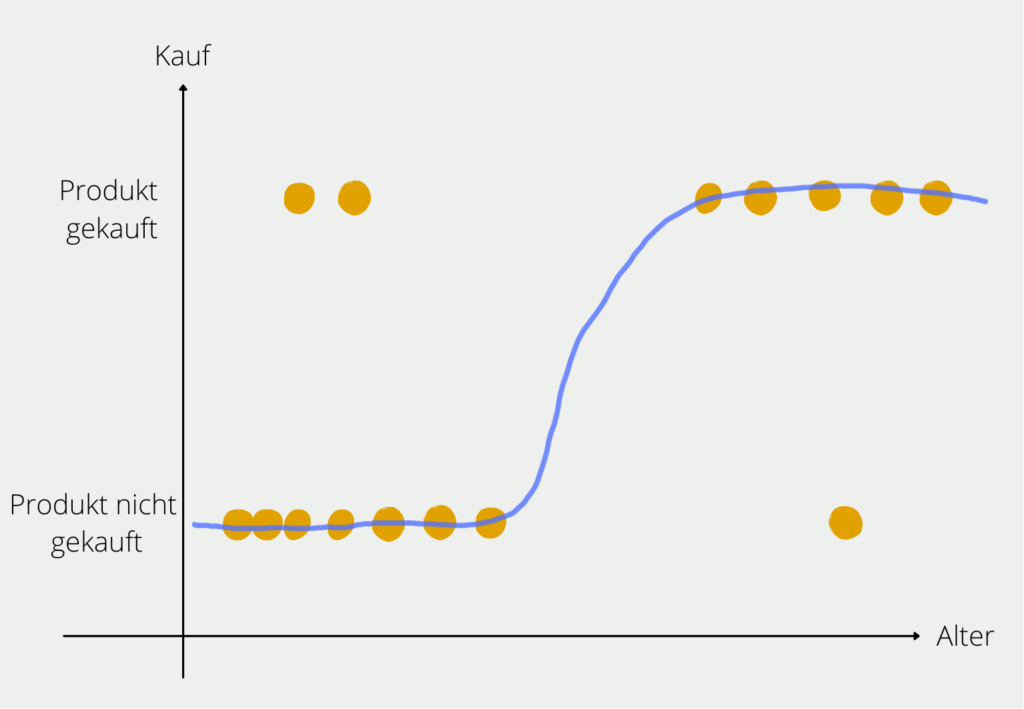
Unabhängig davon, ob es sich um lineare oder nichtlineare Regression handelt, bleibt das Hauptziel der Regressionsanalyse dasselbe: Beziehungen zwischen Variablen herzustellen. Sie dient als Vehikel, um die verborgenen Verbindungen aufzudecken, die Phänomene in verschiedenen Bereichen antreiben. In der Wirtschaft kann sie enthüllen, wie sich Änderungen der Zinssätze auf das Konsumverhalten auswirken. In der Biologie kann sie die Faktoren entschlüsseln, die die Artenvielfalt beeinflussen. In der Finanzwelt trägt sie zur Prognose von Aktienkursbewegungen auf der Grundlage historischer Daten bei.
Was ist die Varianz und warum ist sie wichtig für das Bestimmtheitsmaß?
Bevor wir uns in die Tiefen des Bestimmtheitsmaßes begeben, ist es wichtig, ein grundlegendes Konzept zu erfassen, das dieser statistischen Kennzahl zugrunde liegt: die Varianz. Die Varianz ist das Maß für die Streuung oder Verteilung von Datenpunkten um ihren Durchschnitt und spielt eine entscheidende Rolle, um die Bedeutung des Bestimmtheitsmaßes in der Regressionsanalyse zu verstehen.
Im Kontext der Regressionsanalyse dient die Varianz als kritischer Maßstab. Sie quantifiziert, wie stark Datenpunkte vom Durchschnitt oder der zentralen Tendenz abweichen. Diese Variabilität der Datenpunkte ist der Kern dessen, was Regressionsmodelle zu erfassen und zu erklären versuchen. Die Varianz spiegelt im Wesentlichen die inhärente Komplexität und Vielfalt im Datensatz wider.
Das Bestimmtheitsmaß oder der R-Squared hängt vom Konzept der erklärten Varianz ab. Es misst den Anteil der gesamten Varianz in der abhängigen Variable, der durch die unabhängigen Variablen in einem Regressionsmodell “erklärt” wird. Einfach ausgedrückt zeigt es, wie gut das Modell die Variabilität in den Daten erfasst und erklärt.
Die Bedeutung der erklärten Varianz kann nicht genug betont werden. Ein hoher Wert deutet darauf hin, dass ein erheblicher Teil der Varianz in der abhängigen Variable erfolgreich durch das Modell berücksichtigt wurde. Dies bedeutet, dass die Vorhersagen des Modells eng mit den beobachteten Daten übereinstimmen, was es zu einem wertvollen Instrument zur Verständnis und Vorhersage von Ergebnissen macht.
Umgekehrt deutet ein niedriges Bestimmtheitsmaß darauf hin, dass das Modell einen erheblichen Teil der Varianz nicht erklärt hat. In solchen Fällen kann das Modell eine Überarbeitung oder zusätzliche unabhängige Variablen benötigen, um seine Erklärungskraft zu verbessern.
Während wir weiter in die Welt des Bestimmtheitsmaßes eintauchen, ist es entscheidend, im Hinterkopf zu behalten, dass die Varianz im Zentrum dieser Statistik steht. Sie beleuchtet die Bandbreite der Möglichkeiten innerhalb der Daten, während das Bestimmtheitsmaß unsere Fähigkeit quantifiziert, diese Variabilität zu bewältigen und zu verstehen. Zusammen ermöglichen sie es Datenanalysten und Forschern, die Güte der Anpassung von Regressionsmodellen zu bewerten und tiefere Einblicke in die Beziehungen zwischen den Variablen zu gewinnen.
Wie berechnet man das Bestimmtheitsmaß?
Das Bestimmtheitsmaß ist eine entscheidende Statistik in der Regressionsanalyse. Es quantifiziert die Güte der Anpassung eines Regressionsmodells, indem es den Anteil der Varianz in der abhängigen Variable misst, der durch die unabhängigen Variablen erklärt wird. Die Berechnung erfolgt durch einen einfachen Prozess, der die Fähigkeit des Modells beleuchtet, die Variabilität in den Daten zu erfassen und zu erklären.
Die Formel für das Bestimmtheitsmaß
Der R-Squared wird mithilfe der folgenden Formel berechnet:
\(\) \[ R^2 = 1 – \frac{SSR}{SST} \]
Wobei:
- SSR (Sum of Squares of Residuals) ist die Summe der quadrierten Differenzen zwischen den tatsächlichen Werten und den durch das Modell vorhergesagten Werten.
- SST (Total Sum of Squares) ist die Summe der quadrierten Differenzen zwischen den tatsächlichen Werten und dem Mittelwert der abhängigen Variable.
Schritt-für-Schritt-Berechnung
- Berechne den Mittelwert der abhängigen Variable:
\(\) \[ \bar{y} \]
- Berechne die Gesamtsumme der Quadrate SST, indem Du die quadrierten Differenzen zwischen jedem tatsächlichen Wert 𝑦𝑖 und dem Mittelwert addierst:
\(\) \[ SST = \sum_{i=1}^{n} (y_i – \bar{y})^2 \]
- Passe Dein Regressionsmodell an die Daten an und erhalte die vorhergesagten Werte:
\(\) \[ \hat{y_i} \]
- Berechne die Summe der Quadrate der Residuen SSR, indem Du die quadrierten Differenzen zwischen jedem tatsächlichen Wert 𝑦𝑖 und dem entsprechenden vorhergesagten Wert addierst:
\(\) \[ SSR = \sum_{i=1}^{n} (y_i – \hat{y_i})^2 \]
- Wende schließlich die Formel zur Berechnung von R-Squared an:
\(\) \[ R^2 = 1 – \frac{SSR}{SST} \]
Wie interpretiert man das Bestimmtheitsmaß?
Angenommen, du bist ein Datenanalyst, der für eine Immobilienagentur arbeitet, und deine Aufgabe besteht darin, ein Regressionsmodell zu entwickeln, um Hauspreise basierend auf verschiedenen Merkmalen wie Quadratmeterzahl, Anzahl der Schlafzimmer und Entfernung zum Stadtzentrum vorherzusagen. Nachdem du das Modell erstellt hast, erhältst du einen Bestimmtheitsmaßwert von 0,80.
- 0,80 Bestimmtheitsmaß: Dies bedeutet, dass dein Regressionsmodell 80% der Variabilität der Hauspreise mithilfe der ausgewählten Merkmale erklärt. Mit anderen Worten, 80% der Schwankungen der Hauspreise werden durch Faktoren wie Quadratmeterzahl, Anzahl der Schlafzimmer und Entfernung zum Stadtzentrum, die dein Modell berücksichtigt, erklärt.
- Gute Anpassung: Ein Bestimmtheitsmaß von 0,80 gilt im Allgemeinen als gute Anpassung für ein Regressionsmodell. Es zeigt an, dass dein Modell einen erheblichen Teil der Beziehungen zwischen den Merkmalen und den Hauspreisen erfasst.
- Vorhersagekraft: Du kannst Vertrauen in die Vorhersagekraft deines Modells haben. Es legt nahe, dass die Vorhersagen des Modells gut mit tatsächlichen Hauspreisen übereinstimmen, was es zu einem wertvollen Werkzeug zur Schätzung von Preisen auf der Grundlage der ausgewählten Variablen macht.
- Verbesserungspotenzial: Obwohl 0,80 ein starker Wert ist, bleiben immer noch 20% der Variabilität der Hauspreise unerklärt. Dies könnte auf andere Faktoren zurückzuführen sein, die nicht im Modell enthalten sind, oder auf die inhärente Zufälligkeit des Immobilienmarktes.
- Modellverfeinerung: Wenn das Erreichen eines höheren Bestimmtheitsmaßes für deine Anwendung entscheidend ist, könntest du in Betracht ziehen, weitere relevante Merkmale hinzuzufügen oder das Modell zu verfeinern, um zusätzliche Quellen der Variabilität zu berücksichtigen.
In diesem Szenario bietet ein Bestimmtheitsmaßwert von 0,80 Vertrauen in die Fähigkeit des Modells, die Hauspreise anhand der ausgewählten Variablen zu erklären und vorherzusagen. Es dient als wertvoller Indikator für die Güte der Anpassung deines Modells an die Daten.
Welche Einschränkungen hat das Bestimmtheitsmaß?
Obwohl das Bestimmtheitsmaß (R-Squared) eine wertvolle Metrik zur Beurteilung der Anpassungsgüte eines Regressionsmodells ist, hat es bestimmte Einschränkungen und sollte in Verbindung mit anderen Bewertungsmaßnahmen für eine umfassendere Analyse verwendet werden. Hier sind einige wichtige Einschränkungen zu beachten:
- Abhängigkeit von der Modellkomplexität: Das Bestimmtheitsmaß steigt tendenziell an, wenn du mehr unabhängige Variablen zu einem Modell hinzufügst, selbst wenn diese Variablen die Vorhersagekraft des Modells nicht wirklich verbessern. Dies kann zu Überanpassung führen, bei der das Modell die Trainingsdaten gut anpasst, aber auf ungesehenen Daten schlecht abschneidet.
- Keine Informationen über Kausalität: Es misst die Stärke der Beziehung zwischen den unabhängigen Variablen und der abhängigen Variablen, etabliert jedoch keine Kausalität. Ein hohes Bestimmtheitsmaß bedeutet nicht, dass eine Variable Änderungen in der anderen verursacht.
- Empfindlich gegenüber Ausreißern: Es ist empfindlich gegenüber Ausreißern, insbesondere in kleinen Datensätzen. Ein einzelner Ausreißer kann den Wert des Bestimmtheitsmaßes erheblich beeinflussen und möglicherweise zu irreführenden Schlussfolgerungen über die Anpassung des Modells führen.
- Annahme der Linearität: Die Metrik geht von einer linearen Beziehung zwischen den unabhängigen und abhängigen Variablen aus. Wenn die Beziehung nicht linear ist, spiegelt sie möglicherweise nicht genau die Leistung des Modells wider.
- Multikollinearität: Bei hoher Multikollinearität (Korrelation zwischen unabhängigen Variablen) kann das Bestimmtheitsmaß die Stärke der Effekte einzelner Variablen überschätzen, was es schwierig macht, den tatsächlichen Beitrag jeder Variablen zu identifizieren.
- Keine Bestätigung der Modellangemessenheit: Die Kennzahl allein bewertet nicht, ob das Regressionsmodell angemessen spezifiziert ist. Es bestätigt nicht, dass die ausgewählten unabhängigen Variablen am besten geeignet sind, um die abhängige Variable zu erklären.
- Kontextabhängigkeit: Die Interpretation des Bestimmtheitsmaßes variiert je nach spezifischem Problem und Kontext. Was als “guter” Wert betrachtet wird, kann in verschiedenen Bereichen und Anwendungen unterschiedlich sein.
- Nicht für den Vergleich von Modellen geeignet: Beim Vergleich von Modellen mit unterschiedlichen abhängigen Variablen kann das Bestimmtheitsmaß nicht direkt verwendet werden. Es ist wichtig, das adjustierte Bestimmtheitsmaß oder andere geeignete Metriken für sinnvolle Vergleiche zu berücksichtigen.
- Stichprobenabhängigkeit: Das Bestimmtheitsmaß kann von der Stichprobengröße beeinflusst werden. In kleinen Stichproben kann der Wert weniger zuverlässig sein und sich möglicherweise nicht gut auf größere Populationen verallgemeinern lassen.
- Externe Faktoren: Es berücksichtigt möglicherweise nicht externe Faktoren oder Veränderungen in der Datenumgebung, die die abhängige Variable beeinflussen können. Diese Faktoren werden möglicherweise nicht vom Modell erfasst.
Um diese Einschränkungen anzugehen, ist es ratsam, neben dem Bestimmtheitsmaß auch andere Bewertungskriterien zu verwenden und die Ergebnisse im Kontext der spezifischen Anwendungen und Fragestellungen zu interpretieren.
Was ist der adjusted R-squared?
In der Regressionsanalyse ist das adjustierte Bestimmtheitsmaß eine modifizierte Version der traditionellen Bestimmtheitsmaß-Metrik. Es behebt eine Einschränkung der Standardmetrik, indem es die Anzahl der Prädiktoren (unabhängigen Variablen) im Modell berücksichtigt.
- Berücksichtigung der Modellkomplexität:
- Traditionelles Bestimmtheitsmaß: Es misst den Anteil der Varianz in der abhängigen Variable, der durch die unabhängigen Variablen in einem Regressionsmodell erklärt wird. Wenn jedoch mehr Prädiktoren zu einem Modell hinzugefügt werden, steigt das Bestimmtheitsmaß tendenziell an, selbst wenn diese zusätzlichen Prädiktoren die Vorhersagekraft des Modells nicht signifikant verbessern. Dies kann zu Überanpassung führen, bei der das Modell die Trainingsdaten sehr gut anpasst, aber auf neuen, ungesehenen Daten schlecht abschneidet.
- Adjustiertes Bestimmtheitsmaß: Um dieses Problem zu lösen, passt das adjustierte Bestimmtheitsmaß den Wert auf Basis der Anzahl der Prädiktoren im Modell und der Stichprobengröße an. Es bestraft die Aufnahme unnötiger Prädiktoren, die nicht wesentlich zur Leistung des Modells beitragen. Diese Anpassung hilft, Überanpassung vorzubeugen und liefert eine genauere Darstellung der Anpassungsgüte des Modells.
- Die Formel für das adjustierte Bestimmtheitsmaß:
Die Formel lautet wie folgt:
\(\) \[ R^2_{\text{adj}} = 1 – \left( \frac{(1 – R^2) \cdot (n – 1)}{n – k – 1} \right) \]
Dabei:
- n ist die Anzahl der Beobachtungen (Stichprobengröße).
- k ist die Anzahl der unabhängigen Variablen (Prädiktoren) im Modell.
- Interpretation:
- Ein adjustiertes Bestimmtheitsmaß nahe 1 zeigt an, dass das Modell einen erheblichen Teil der Varianz in der abhängigen Variable erklärt, während es die Komplexität des Modells berücksichtigt.
- Wenn du sinnvolle Prädiktoren zum Modell hinzufügst, wird das adjustierte Bestimmtheitsmaß zunehmen. Das Hinzufügen irrelevanter Prädiktoren oder solcher mit schwachen Beziehungen kann jedoch zu einer Abnahme des Werts führen.
- Verwendung bei der Modellauswahl:
- Das adjustierte Bestimmtheitsmaß ist ein wertvolles Werkzeug für die Modellauswahl. Wenn du mehrere Regressionsmodelle vergleichst, kannst du das adjustierte Bestimmtheitsmaß verwenden, um das Modell zu identifizieren, das ein Gleichgewicht zwischen Anpassungsgüte und Modellsimplizität findet.
- Im Allgemeinen zeigt ein höherer Wert ein besser passendes Modell an, aber du solltest auch die Anzahl der Prädiktoren und die praktische Bedeutung des Modells berücksichtigen.
Zusammenfassend ist das adjustierte Bestimmtheitsmaß eine Modifikation des traditionellen Maßes, das die Modellkomplexität berücksichtigt. Es hilft, Überanpassung zu verhindern, indem es die Aufnahme unnötiger Prädiktoren bestraft. Bei der Bewertung von Regressionsmodellen oder der Auswahl des geeignetsten Modells bietet das adjustierte Bestimmtheitsmaß ein ausgewogeneres Maß für die Anpassungsgüte.
Das solltest Du mitnehmen
- R-Squared ist eine entscheidende Metrik in der Regressionsanalyse, die den Anteil der erklärten Varianz durch unabhängige Variablen in einem Modell quantifiziert.
- Es hilft dabei zu beurteilen, ob die Beziehungen zwischen Prädiktoren und der abhängigen Variable statistisch signifikant sind.
- Das R-Squared erleichtert den Vergleich verschiedener Modelle und dient als Grundlage für die Modellauswahl.
- Obwohl wertvoll, hat es Einschränkungen, wie die Sensibilität gegenüber der Modellkomplexität und die Unfähigkeit, Kausalität herzustellen.
- Um diese Einschränkungen zu adressieren, passt das adjustierte R-Squared die Modellkomplexität an und macht es zu einer robusteren Wahl für die Modellbewertung.
- Ein hohes R-Squared zu erreichen, sollte nicht auf Kosten der Modellkomplexität gehen. Die Balance zwischen Anpassungsgüte und Modellsimplizität ist entscheidend.

Was ist Gibbs-Sampling?
Erforschen Sie Gibbs-Sampling: Lernen Sie die Anwendungen kennen und erfahren Sie, wie sie in der Datenanalyse eingesetzt werden.

Was ist ein Bias?
Auswirkungen und Maßnahmen zur Abschwächung eines Bias: Dieser Leitfaden hilft Ihnen, den Bias zu verstehen und zu erkennen.

Was ist die Varianz?
Die Rolle der Varianz in der Statistik und der Datenanalyse: Verstehen Sie, wie man die Streuung von Daten messen kann.

Was ist die KL Divergence (Kullback-Leibler Divergence)?
Erkunden Sie die Kullback-Leibler Divergence (KL Divergence), eine wichtige Metrik in der Informationstheorie und im maschinellen Lernen.

Was ist MLE: Maximum-Likelihood-Methode?
Verstehen Sie die Maximum-Likelihood-Methode (MLE), ein leistungsfähiges Werkzeug zur Parameterschätzung und Datenmodellierung.

Was ist der Varianzinflationsfaktor (VIF)?
Erfahren Sie, wie der Varianzinflationsfaktor (VIF) Multikollinearität in Regressionen erkennt, um eine bessere Datenanalyse zu ermöglichen.
Andere Beiträge zum Thema Bestimmtheitsmaß
Die Universität von Newcastle hat einen interessanten Artikel zu diesem Thema verfasst, den Du hier finden kannst.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.