MapReduce ist ein Algorithmus, der es ermöglicht große Datensätze parallel, also auf mehreren Computern gleichzeitig, verarbeiten zu können. Dadurch werden Abfragen für große Datenmengen stark beschleunigt.
Wofür nutzen wir MapReduce?
MapReduce wurde ursprünglich von Google eingesetzt, um die große Menge an Suchergebnissen effizient durchsuchen zu können. Richtig berühmt wurde der Algorithmus jedoch erst durch die Nutzung innerhalb des Hadoop Frameworks. Dieses Tool speichert große Datenmengen in dem Hadoop Distributed File System (kurz: HDFS) und nutzt MapReduce für Abfragen oder Aggregationen von Informationen im Bereich von Terra- oder Petabytes.
Angenommen wir haben alle Teile der Harry Potter Romane in Hadoop als PDF abgelegt und möchten nun die einzelnen Wörter zählen, die in den Büchern vorkommen. Dies ist eine klassische Aufgabe bei der uns die Aufteilung in eine Map-Funktion und eine Reduce Funktion helfen kann.
Wie wurde es früher gemacht?
Bevor es die Möglichkeit gab, solche aufwendigen Abfragen auf ein ganzes Computer-Cluster aufzuteilen und parallel berechnen zu können, war man gezwungen, den kompletten Datensatz nacheinander zu durchlaufen. Dadurch wurde die Abfragezeit natürlich auch umso länger, umso größer der Datensatz wurde.
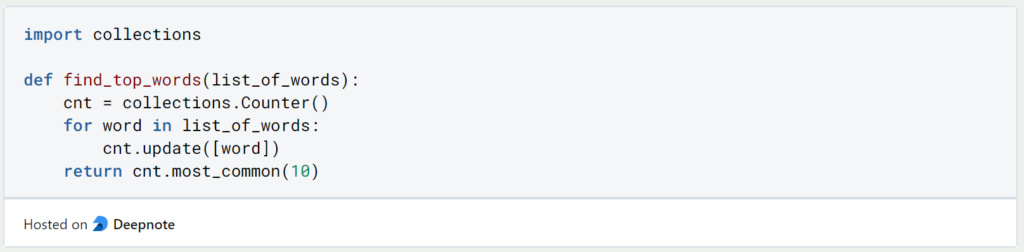
Angenommen wir haben die Harry Potter Texte bereits Wort für Wort in einer Python Liste vorliegen:

Wir können die vorkommenden Wörter zählen, indem wir diese Liste mit einer For-Schleife durchlaufen und jedes Wort in den “Counter” aus dem Python Modul “Collections” laden. Diese Funktion übernimmt dann für uns das Zählen der Wörter und gibt die zehn häufigsten Wörter aus. Mithilfe des Python Moduls “Time” können wir uns anzeigen lassen, wie lange unser Computer benötigt hat, um diese Funktion auszuführen.
Laut der Website wordcounter.io hat der erste Harry Potter Teil insgesamt 76.944 Wörter. Da unser Beispielsatz nur 20 Wörter (inklusive Punkt) hat, bedeutet das, dass wir etwa 3.850 Mal (76.944 / 20 ~ 3.847) diesen Beispielsatz wiederholen müssen, um eine Liste mit genauso vielen Wörtern zu bekommen, wie Harry Potter’s Stein der Weisen:
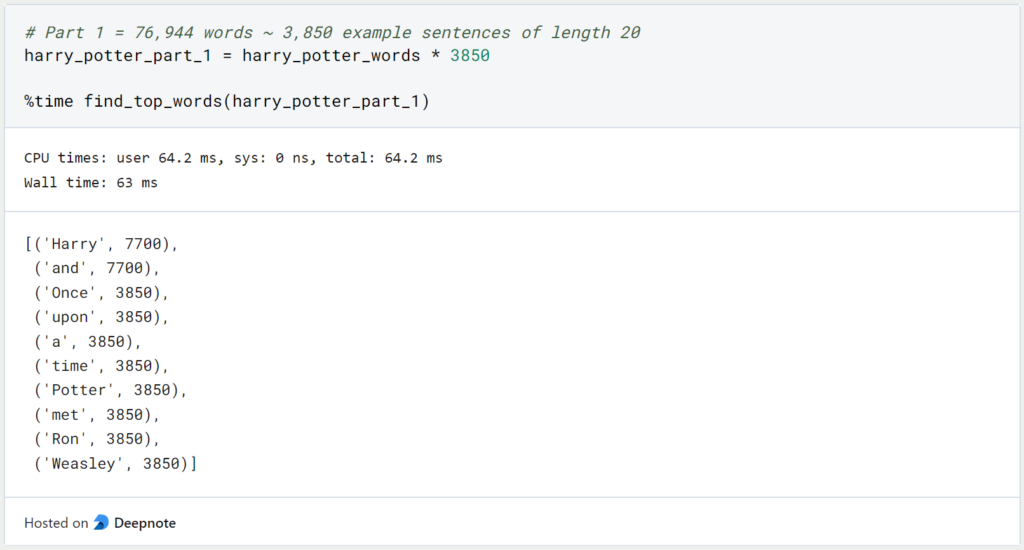
Unsere Funktionen benötigt 64 Millisekunden, um alle Wörter des ersten Teils zu durchlaufen und zu zählen, wie oft sie vorkommen. Wenn wir die gleiche Abfrage für alle Harry Potter Teile mit insgesamt 3.397.170 Wörtern (Quelle: wordcounter.io) durchführen, dauert es insgesamt 2,4 Sekunden.
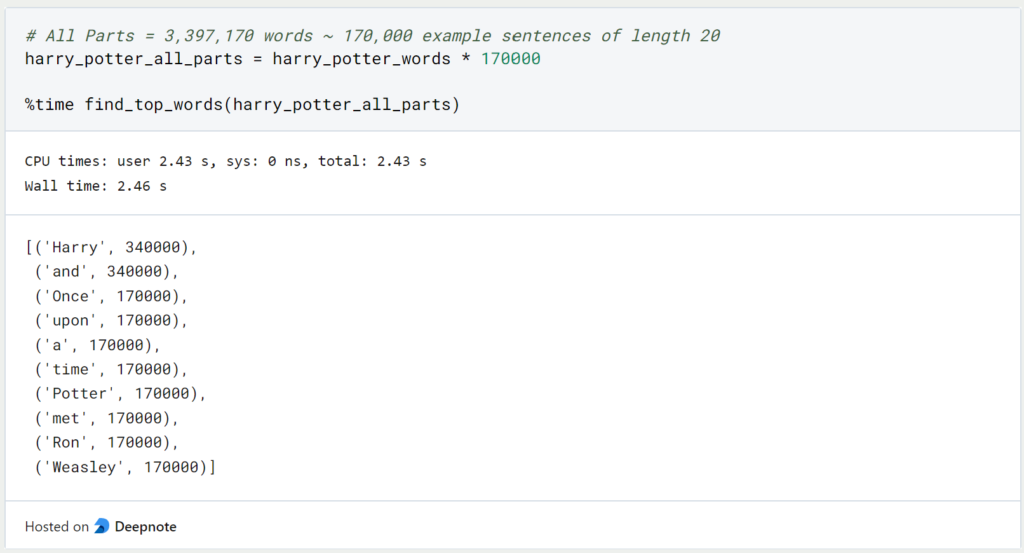
Diese Abfrage dauert vergleichsweise lange und wird für größere Datensätze natürlich immer länger. Der einzige Weg um die Ausführung der Funktion zu beschleunigen ist es, einen Computer mit einem leistungsfähigeren Prozessor (CPU) auszustatten, also dessen Hardware zu verbessern. Wenn man versucht, die Ausführung eines Algorithmus zu beschleunigen, indem man die Hardware des Gerätes verbessert, nennt man das vertikales Skalieren.
Wie funktioniert der MapReduce Algorithmus?
Mithilfe von MapReduce ist es möglich eine solche Abfrage deutlich zu beschleunigen, indem man die Aufgabe in kleinere Teilaufgaben aufsplittet. Das hat dann wiederum den Vorteil, dass die Teilaufgaben auf viele verschiedene Computer aufgeteilt und von ihnen ausgeführt werden kann. Dadurch müssen wir nicht die Hardware eines einzigen Gerätes verbessern, sondern können viele, vergleichsweise leistungsschwächere, Computer nutzen und trotzdem die Abfragezeit verringern. Ein solches Vorgehen nennt man horizontales Skalieren.
Kommen wir zurück zu unserem Beispiel: Bisher waren wir bildlich so vorgegangen, dass wir alle Harry Potter Teile gelesen haben und nach jedem gelesenen Wort die Strichliste mit den einzelnen Wörtern einfach um einen Strich erweitert haben. Das Problem daran ist, dass wir diese Vorgehensweise nicht parallelisieren können. Angenommen eine zweite Person will uns unterstützen, dann kann sie das nicht tun, weil sie die Strichliste, mit der wir gerade arbeiten, benötigt, um weiterzumachen. Solange sie diese nicht hat, kann sie nicht unterstützen.
Sie kann uns aber unterstützen, indem sie bereits mit dem zweiten Teil der Harry Potter Reihe beginnt und eine eigene Strichliste nur für das zweite Buch erstellt. Zum Schluss können wir dann alle einzelnen Strichlisten zusammenführen und beispielsweise die Häufigkeit des Wortes “Harry” auf allen Strichlisten zusammenaddieren.
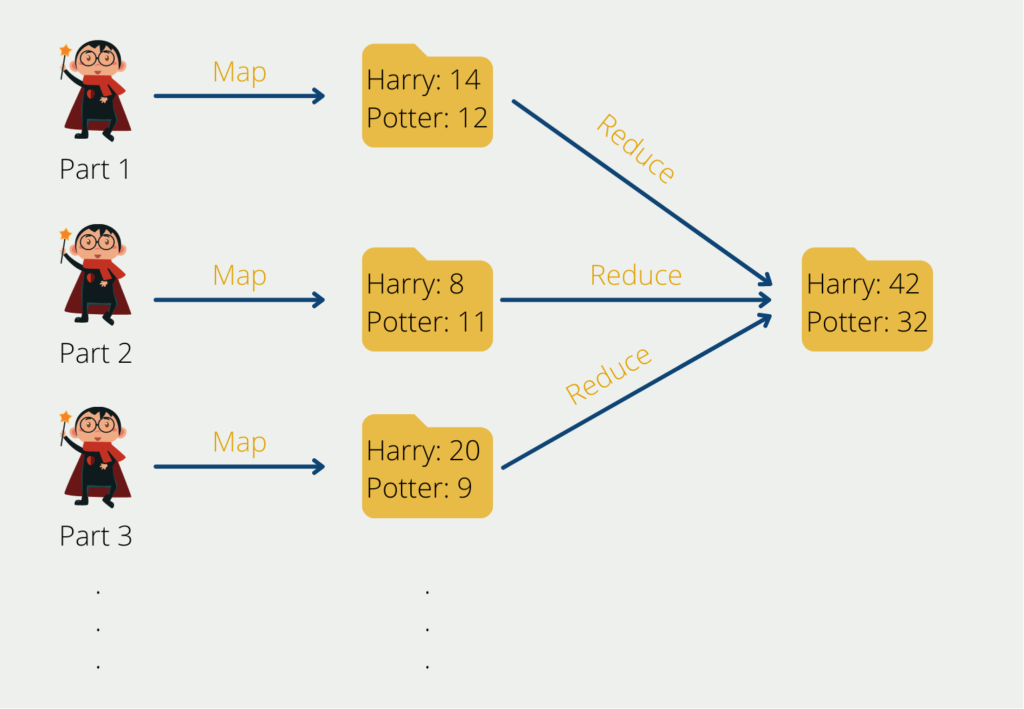
Dadurch lässt sich die Aufgabe auch relativ einfach horizontal skalieren, indem jeweils eine Person pro Harry Potter Buch arbeitet. Wenn wir noch schneller arbeiten wollen, können wir auch mehrere Personen mit einbeziehen und jede Person ein einziges Kapitel bearbeiten lassen. Am Schluss müssen wir dann nur alle Ergebnisse der einzelnen Personen zusammennehmen, um so zu einem Gesamtergebnis zu gelangen.
Welche Anwendungen nutzen MapReduce?
MapReduce ist ein beliebtes Programmiermodell und eine Technologie für die Verarbeitung großer Datenmengen in einer verteilten Computerumgebung. Es hat eine breite Palette von Anwendungen in verschiedenen Branchen und Bereichen, wie z. B.:
- Big-Data-Verarbeitung: MapReduce wird häufig für die Verarbeitung und Analyse großer Datenmengen in Branchen wie dem Finanzwesen, dem Gesundheitswesen und dem elektronischen Handel eingesetzt. Es bietet eine skalierbare und kostengünstige Lösung für die Verarbeitung und Analyse großer Datenmengen.
- Suchmaschinen: MapReduce wird von Suchmaschinen wie Google und Yahoo häufig zur Indizierung und Suche in großen Mengen von Webinhalten verwendet. Es ermöglicht eine schnelle und effiziente Indizierung von Webseiten und versetzt Benutzer in die Lage, große Datenmengen schnell zu durchsuchen.
- Empfehlungssysteme: MapReduce kann zum Aufbau von Empfehlungssystemen verwendet werden, die den Nutzern auf der Grundlage ihrer Vorlieben und ihres bisherigen Verhaltens Produkte oder Dienstleistungen vorschlagen können. Durch die Analyse von Benutzerdaten, wie z. B. der Kauf- und Suchhistorie, kann MapReduce personalisierte Empfehlungen für einzelne Benutzer erstellen.
- Betrugserkennung: MapReduce kann zur Betrugserkennung in Echtzeit eingesetzt werden, indem große Mengen von Transaktionsdaten analysiert werden. Es kann Muster und Anomalien in Transaktionsdaten erkennen, z. B. ungewöhnliche Ausgabenmuster oder betrügerische Aktivitäten, und diese für weitere Untersuchungen kennzeichnen.
- Analyse sozialer Medien: MapReduce kann zur Analyse von Social-Media-Daten verwendet werden, um Nutzerverhalten, Stimmungen und Trends zu verstehen. Mit MapReduce können Daten von Social-Media-Plattformen wie Twitter, Facebook und LinkedIn analysiert werden, um Einblicke in Kundenpräferenzen und -verhalten zu gewinnen.
- Bild- und Videoverarbeitung: MapReduce kann für die Verarbeitung großer Mengen von Bild- und Videodaten verwendet werden, z. B. in Sicherheitsüberwachungssystemen oder in der medizinischen Bildgebung. Es kann für Aufgaben wie Bilderkennung, Objekterkennung und Videokomprimierung verwendet werden.
Zusammenfassend lässt sich sagen, dass MapReduce eine breite Palette von Anwendungen in verschiedenen Branchen und Bereichen hat, darunter Big Data-Verarbeitung, Suchmaschinen, Empfehlungssysteme, Betrugserkennung, Analyse sozialer Medien sowie Bild- und Videoverarbeitung. Ihre Skalierbarkeit, Effizienz und Fehlertoleranz machen sie zu einer idealen Technologie für die Verarbeitung und Analyse großer Datenmengen in einer verteilten Computerumgebung.
Wie funktioniert MapReduce in Python?
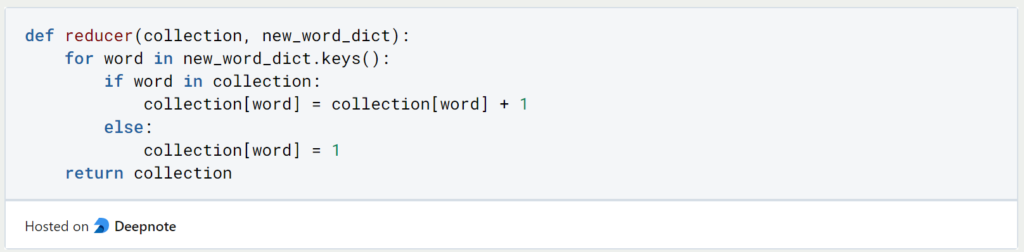
Insgesamt brauchen wir also zwei Funktionen einen Mapper und einen Reducer. Den Mapper definieren wir so, dass er für jedes Wort, das er bekommt, ein Dictionary zurückgibt mit dem Wort als Schlüssel und dem Wert 1:

Analog zu unserem Beispiel gibt der Mapper also eine “Strichliste” zurück, die aussagt: “Das Wort, das mir übergeben wurde, kommt genau einmal vor”. Der Reducer übernimmt dann im zweiten Schritt alle einzelnen “Strichlisten” und fügt diese zu einer großen gesamten “Strichliste” zusammen. Er unterscheidet dabei zwei Fälle: Wenn das Wort, das ihm übergeben wird, bereits in seiner großen “Strichliste” vorkommt, dann fügt er in der entsprechenden Zeile einfach ein Strich hinzu. Wenn das neue Wort noch nicht in seiner Liste auftaucht, fügt der Reducer einfach eine neue Zeile mit dem Wort in die große “Strichliste” hinzu.
Wenn wir diese beiden Teilaufgaben zusammenführen, dauert dieselbe Abfrage wie zuvor nur noch 1,4 Sekunden:
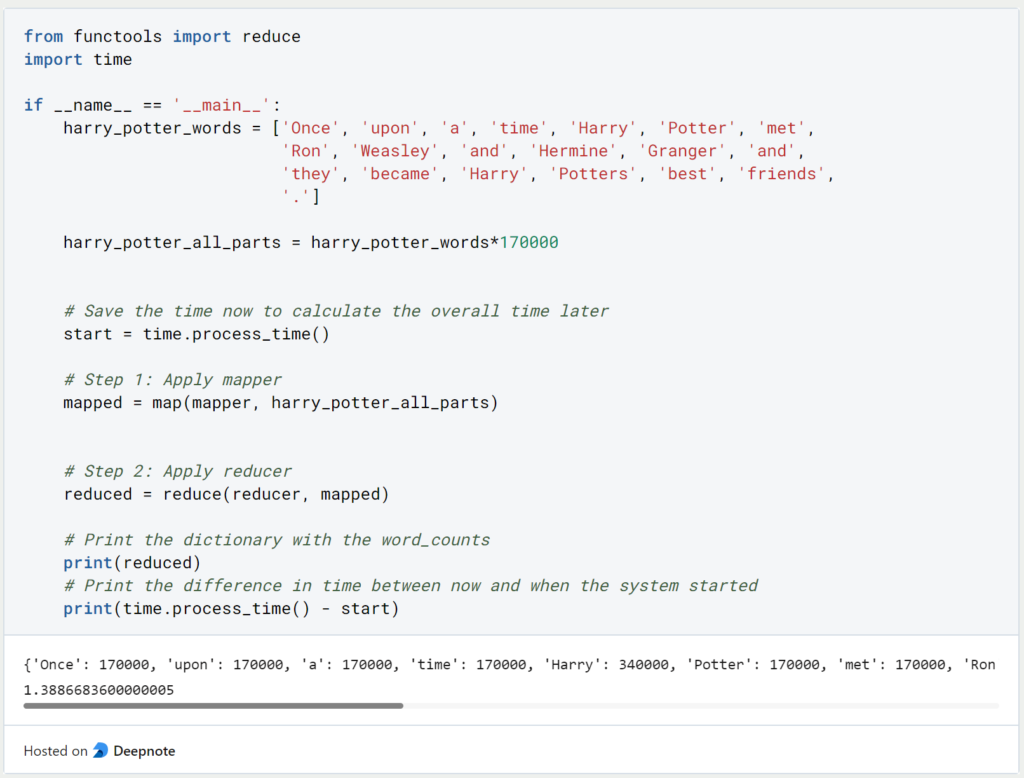
Somit konnten wir durch den MapReduce Algorithmus die Abfragezeit für alle Harry Potter Bücher mehr als halbieren, ohne dass wir horizontale oder vertikale Skalierung vorgenommen haben. Wenn uns jedoch die Abfragezeit von 1,5 Sekunden immer noch zu groß ist, könnten wir die Wortliste auch einfach beliebig aufteilen und den Mapper auf verschiedenen Computern parallel ausführen lassen, um den Prozess weiter zu beschleunigen.
Was sind die Nachteile von MapReduce?
Unser Beispiel hat eindrucksvoll gezeigt, dass wir mithilfe von MapReduce große Datenmengen schneller Abfragen können und den Algorithmus gleichzeitig für eine horizontale Skalierung vorbereiten. Jedoch kann MapReduce nicht immer eingesetzt werden oder bringt je nach Anwendungsfall auch Nachteile mit sich:
- Manche Abfragen lassen sich nicht in das MapReduce Schema bringen.
- Die Map Funktionen laufen isoliert voneinander ab. Somit ist es nicht möglich, dass die Prozesse untereinander kommunizieren.
- Verteilte Systeme sind deutlich schwerer zu beaufsichtigen und kontrollieren als ein einziger Computer. Es sollte also genau abgewogen werden, ob wirklich ein Computing Cluster benötigt wird. Für die Kontrolle eines Computer-Clusters kann das Software-Tool Kubernetes genutzt werden.
Welche Best Practices gibt es für die Einführung von Apache MapReduce?
Im Folgenden finden Sie einige bewährte Verfahren für die Implementierung von MapReduce:
- Entwerfe Deine MapReduce-Aufträge so, dass sie skalierbar und fehlertolerant sind.
- Verwende kleinstmögliche Datenmengen als Eingabe für jeden Auftrag, um die Verarbeitungszeit zu verkürzen.
- Verwende Komprimierungstechniken, um die Größe der Eingabe- und Ausgabedaten zu reduzieren und die Leistung zu verbessern.
- Optimiere die Leistung der Map- und Reduce-Funktionen und stelle sicher, dass sie einfach, effizient und effektiv sind.
- Vermeide es, zu viele Daten auf die Festplatte zu schreiben, da dies die Verarbeitungszeiten verlangsamen kann.
- Verwende Combiner, um die MapReduce-Leistung zu optimieren, indem Du die Datenmenge, die zwischen den Map- und Reduce-Phasen übergeben wird, reduzierst.
- Überwache und optimiere Deine Cluster regelmäßig, um eine optimale Leistung zu gewährleisten.
- Teste Deine MapReduce-Aufträge gründlich, bevor Du sie in der Produktion ausführst, um eventuelle Probleme zu erkennen und zu beheben.
- Verwende je nach Art und Größe der Daten das richtige Dateiformat für die Eingabe-/Ausgabedaten.
- Wähle die richtige Hardwarekonfiguration für Dein Cluster, basierend auf der Größe der Daten und den Verarbeitungsanforderungen.1
Das solltest Du mitnehmen
- MapReduce ist ein Algorithmus, der es ermöglicht große Datensätze parallel und schnell zu verarbeiten.
- Der MapReduce Algorithmus splittet eine große Abfrage in mehrere kleine Teilaufgaben auf, die dann auf verschiedene Computer verteilt und bearbeitet werden können.
- Nicht jede Anwendungen lässt sich in das MapReduce Schema überführen, sodass es manchmal auch gar nicht möglich ist, diesen Algorithmus zu nutzen.
Vielen Dank an Deepnote für das Sponsoring dieses Artikels! Deepnote bietet mir die Möglichkeit, Python-Code einfach und schnell auf dieser Website einzubetten und auch die zugehörigen Notebooks in der Cloud zu hosten.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema MapReduce
- Das Paper von Google, in dem MapReduce zum ersten Mal vorgestellt wurde, findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.