MapReduce is an algorithm that allows large data sets to be processed in parallel, i.e. on multiple computers simultaneously. This greatly accelerates queries for large data sets.
What do we use MapReduce for?
MapReduce was originally used by Google to efficiently search the large volume of search results. However, the algorithm only became really famous through its use within the Hadoop framework. It stores large amounts of data in the Hadoop Distributed File System (HDFS for short) and uses MapReduce for queries or aggregations of information in the range of terabytes or petabytes.
Suppose we have stored all parts of the Harry Potter novels in Hadoop as a PDF and now want to count the individual words that appear in the books. This is a classic task where the division into a map function and a reduce function can help us.
How was it done before?
Before there was the possibility to split such complex queries to a whole computer cluster and to calculate them in parallel, one was forced to run through the complete data set one after the other. Of course, the larger the data set, the longer the query time.
Suppose we already have the Harry Potter texts word for word in a Python list:

We can count the words that occur by looping through this list with a For loop and loading each word into the “Counter” from the Python “Collections” module. This function then does the word counting for us and outputs the ten most frequent words. Using the Python module “Time”, we can display how long it took our computer to execute this function.
According to the website wordcounter.io, the first Harry Potter part has a total of 76,944 words. Since our example sentence has only 20 words (including period), this means that we have to repeat this example sentence about 3,850 times (76,944 / 20 ~ 3,847) to get a list with as many words as Harry Potter’s first part:
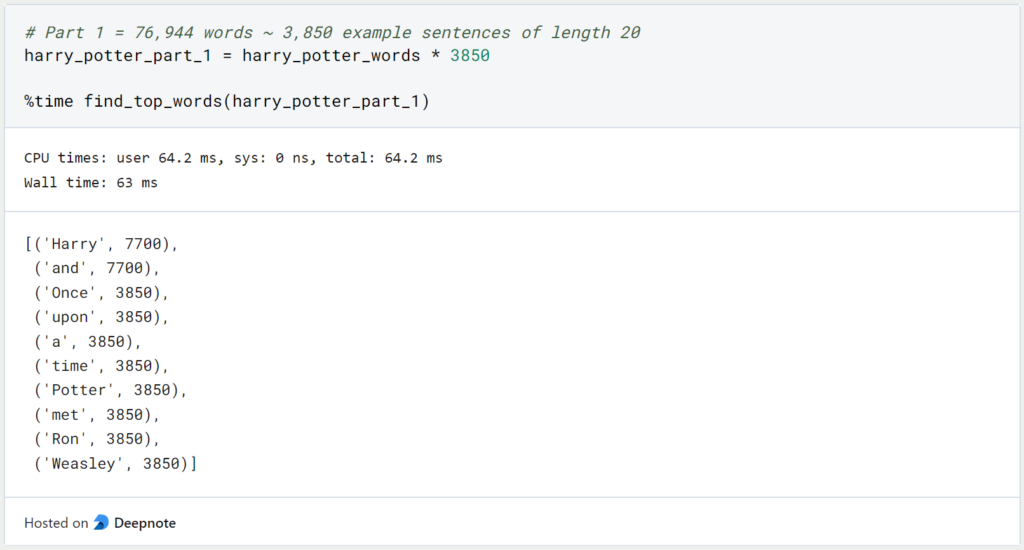
Our function needs 64 milliseconds to run through all the words of the first part and count how often they occur. If we perform the same query for all Harry Potter parts with a total of 3,397,170 words (source: wordcounter.io), it takes a total of 2.4 seconds.
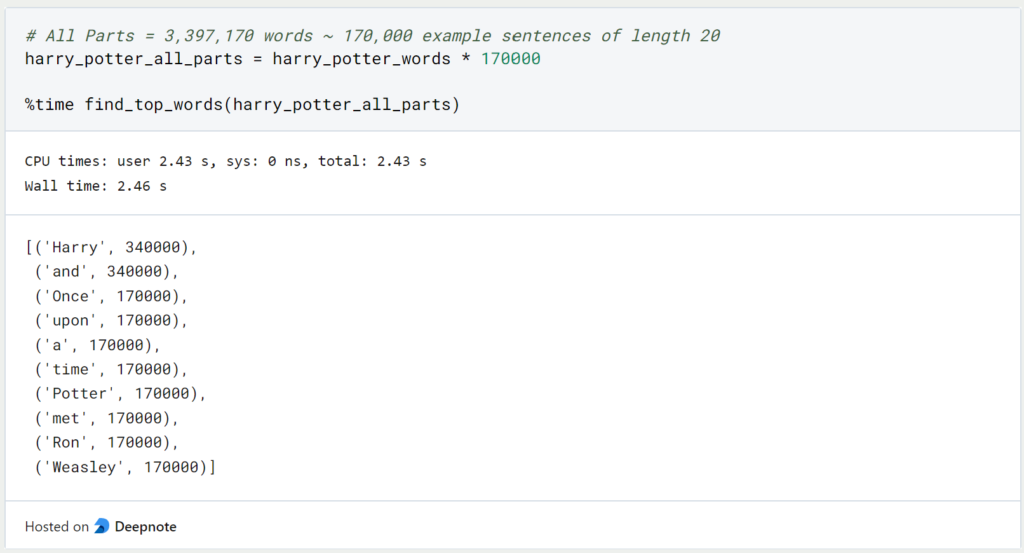
This query takes a comparatively long time and naturally becomes longer and longer for larger data sets. The only way to speed up the execution of the function is to equip a computer with a more powerful processor (CPU), i.e. to improve its hardware. When one tries to speed up the execution of an algorithm by improving the hardware of the device, this is called vertical scaling.
How does the MapReduce algorithm work?
With the help of MapReduce, it is possible to significantly speed up such a query by splitting the task into smaller subtasks. This in turn has the advantage that the subtasks can be divided among and executed by many different computers. This means that we do not have to improve the hardware of a single device, but can use many, comparatively less powerful, computers and still reduce the query time. Such an approach is called horizontal scaling.
Let’s get back to our example: Up to now, we had figuratively proceeded in such a way that we read all Harry Potter parts and simply extended the tally sheet with the individual words by one tally after each word we read. The problem with this is that we can’t parallelize this approach. Assuming a second person wants to assist us, she can’t do so because she needs the tally sheet we’re currently working with to continue. As long as she doesn’t have it, she can’t support it.
However, she can support us by already starting with the second part of the Harry Potter series and creating a separate tally list just for the second book. Finally, we can then merge all the individual tally sheets and, for example, add up the frequency of the word “Harry” on all the tally sheets.
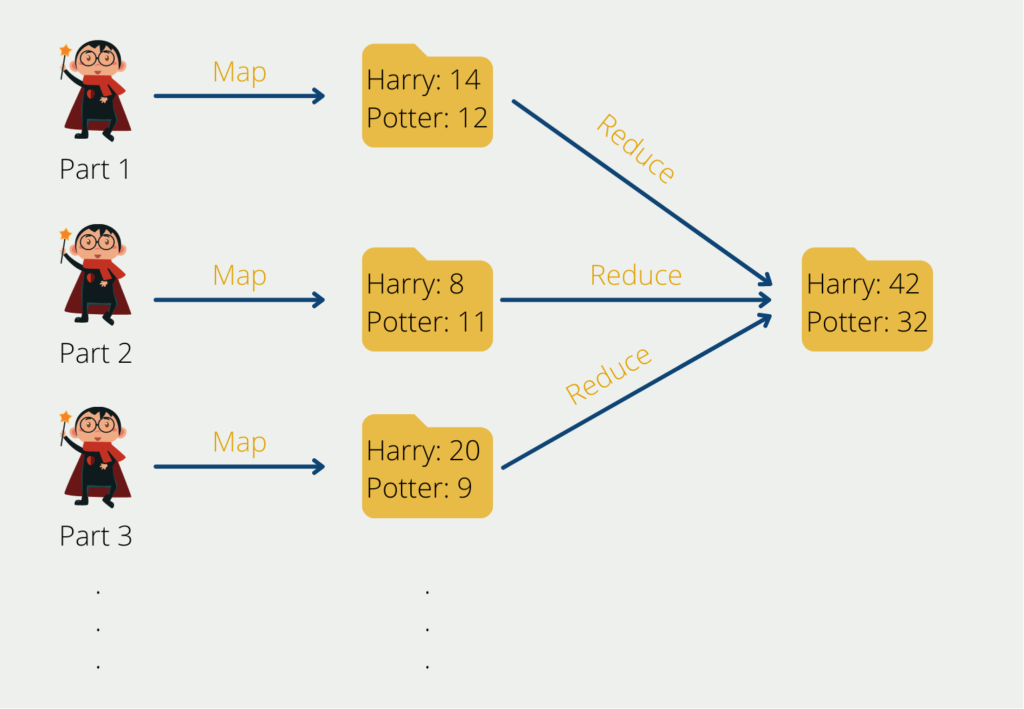
This also makes it relatively easy to scale the task horizontally by having one person work on each Harry Potter book. If we want to work even faster, we can also involve several people and let each person work on a single chapter. In the end, we only have to combine all the results of the individual persons to arrive at an overall result.
Which applications use MapReduce?
MapReduce is a popular programming model and technology for processing large datasets in a distributed computing environment. It has a wide range of applications in various industries and domains, such as:
- Big data processing: MapReduce is commonly used for processing and analyzing large datasets in industries such as finance, healthcare, and e-commerce. It provides a scalable and cost-effective solution for processing and analyzing large datasets.
- Search engines: MapReduce is widely used by search engines such as Google and Yahoo to index and search through vast amounts of web content. It allows for fast and efficient indexing of web pages and enables users to search through massive amounts of data quickly.
- Recommendation systems: MapReduce can be used to build recommendation systems that can suggest products or services to users based on their preferences and past behavior. By analyzing user data, such as purchase history and search history, MapReduce can generate personalized recommendations for individual users.
- Fraud detection: MapReduce can be used to detect fraud in real-time by analyzing large volumes of transaction data. It can identify patterns and anomalies in transaction data, such as unusual spending patterns or fraudulent activity, and flag them for further investigation.
- Social media analysis: MapReduce can be used to analyze social media data to understand user behavior, sentiment, and trends. It can be used to analyze data from social media platforms such as Twitter, Facebook, and LinkedIn to gain insights into customer preferences and behavior.
- Image and video processing: MapReduce can be used to process large amounts of image and video data, such as in security surveillance systems or medical imaging. It can be used to perform tasks such as image recognition, object detection, and video compression.
In summary, MapReduce has a wide range of applications in various industries and domains, including big data processing, search engines, recommendation systems, fraud detection, social media analysis, and image and video processing. Its scalability, efficiency, and fault-tolerance make it an ideal technology for processing and analyzing large datasets in a distributed computing environment.
How does MapReduce work in Python?
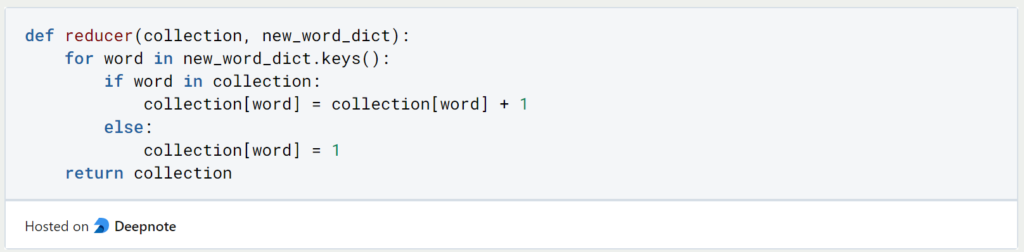
In total, we need two functions a mapper and a reducer. We define the mapper in such a way that it returns a dictionary for each word it receives with the word as key and the value 1:

Analogous to our example, the mapper returns a tally list that says: “The word that was passed to me occurs exactly once”. In the second step, the reducer then takes all the individual tally sheets and merges them into one large overall tally sheet. It distinguishes two cases: If the word that is passed to it already occurs in its large tally list, then it simply adds a dash in the corresponding line. If the new word does not yet appear in its list, the reducer simply adds a new line with the word to the large tally list.
If we merge these two subtasks, the same query as before takes only 1.4 seconds:
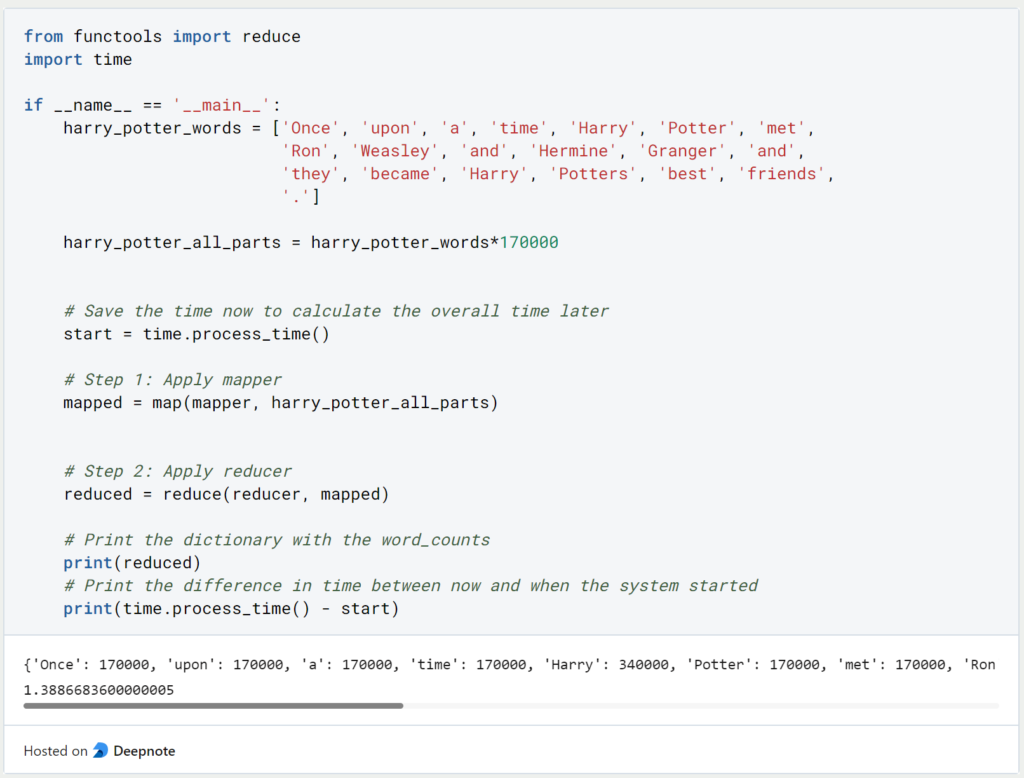
Thus, using the MapReduce algorithm, we were able to more than halve the query time for all Harry Potter books without doing any horizontal or vertical scaling. However, if the query time of 1.4 seconds is still too large for us, we could simply split the word list arbitrarily and run the mapper on different computers in parallel to further speed up the process. Without the MapReduce algorithm, this would not be possible.
What are the Disadvantages of MapReduce?
Our example has impressively shown that we can use MapReduce to query large amounts of data faster and at the same time prepare the algorithm for horizontal scaling. However, MapReduce cannot always be used or also brings disadvantages depending on the use case:
- Some queries cannot be brought into the MapReduce schema.
- The map functions run isolated from each other. Thus, it is not possible for the processes to communicate with each other.
- Distributed systems are much more difficult to supervise and control than a single computer. Therefore, it should be carefully considered whether a computing cluster is really needed. The Kubernetes software tool can be used to control a computer cluster.
What are the Best Practices for implementing MapReduce?
Here are some best practices for implementing MapReduce:
- Design your MapReduce jobs to be scalable and fault-tolerant.
- Use the smallest amount of data possible as input for each job to reduce processing time.
- Use compression techniques to reduce input/output data size and improve performance.
- Optimize the performance of your Map and Reduce functions, making sure they are simple, efficient, and effective.
- Avoid writing too much data to disk as it can slow down processing times.
- Use combiners to optimize MapReduce performance by reducing the amount of data passed between the Map and Reduce phases.
- Monitor and tune your cluster regularly to ensure optimal performance.
- Test your MapReduce jobs thoroughly before running them in production to identify and fix any issues.
- Use the appropriate file format for input/output data, based on the type and size of data.
- Choose the right hardware configuration for your cluster based on the size of your data and processing needs.
This is what you should take with you
- MapReduce is an algorithm that allows large data sets to be processed in parallel and quickly.
- The MapReduce algorithm splits a large query into several small subtasks that can then be distributed and processed on different computers.
- Not every application can be converted to the MapReduce scheme, so sometimes it is not even possible to use this algorithm.
Thanks to Deepnote for sponsoring this article! Deepnote offers me the possibility to embed Python code easily and quickly on this website and also to host the related notebooks in the cloud.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of MapReduce
- The paper from Google that first introduced MapReduce can be found here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.