Die referentielle Integrität ist ein Begriff aus der Datenbanktheorie und beschreibt Regeln, wie eine relationale Datenbank die Integrität und die Konsistenz, also den Wahrheitsgehalt, der Daten sicherstellt. Dabei wird sich vor allem auf die Primär- und Fremdschlüssel in den Tabellen fokussiert.
Was sind Primär- und Fremdschlüssel?
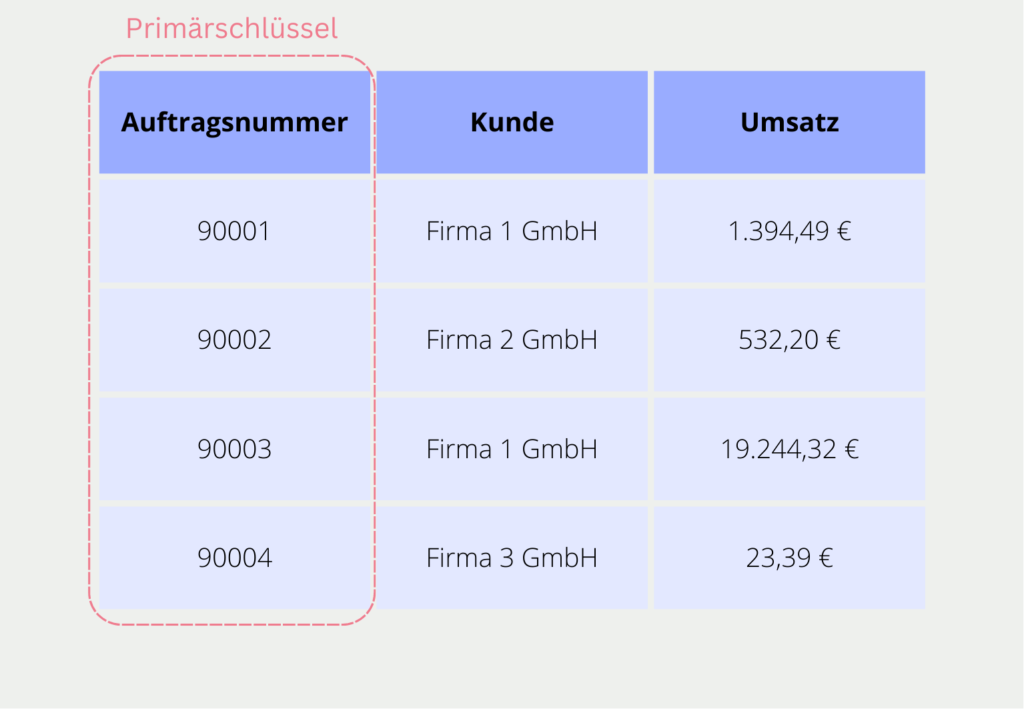
Jede Tabelle in einer Datenbank hat im Idealfall eine Spalte oder eine Kombination aus mehreren Spalten, die einen eindeutigen Wert für einen Datensatz aufweisen. Diese Spalte oder mehrere gemeinsame Spalten werden als Primärschlüssel der Tabelle bezeichnet. Er sorgt dafür, dass jeder Datensatz, also jede Zeile der Tabelle, eindeutig identifiziert werden kann. Das bietet die Möglichkeit mithilfe einer SQL-Abfrage auf einzelne Datensätze zuzugreifen.
Wenn eine Tabelle keine Spalte mit eindeutigen Werten besitzt, können auch mehrere Spalten genutzt werden, um diese Eindeutigkeit herzustellen. Dadurch werden verschiedene Arten von primären Schlüsseln unterschieden.
Der Fremdschlüssel ist ein Attribut oder eine Kombination aus mehreren Attributen, das in einer anderen Tabelle der primäre Schlüssel ist. Dadurch lassen sich in Datenbanken Verbindungen zwischen Tabellen herstellen. Abhängig vom primären Schlüssel in der anderen Tabelle, kann es sich um einen zusammengesetzten oder eindeutigen Fremdschlüssel handeln.

Wichtig ist dabei jedoch zu erwähnen, dass der fremde Schlüssel in der eigenen Tabelle nicht eindeutig sein muss, sondern Werte auch öfters vorkommen können. Mithilfe von solchen Verbindungen können große Tabellen, in mehrere, kleinere Tabellen aufgespalten werden, was sowohl Speicherplatz spart, als auch der Übersichtlichkeit dient.
Was ist die referentielle Integrität?
Die referentielle Integrität (RI) stellt sicher, dass die Tabellenbeziehungen in Datenbanken nicht zu Inkonsistenzen in der Datenbank führen. Dazu werden insgesamt zwei Regeln aufgestellt, die eingehalten werden müssen, damit die referentielle Integrität sichergestellt ist:
- 1. RI-Regel: Wenn ein neuer Datensatz mit Fremdschlüssel eingefügt wird, muss sichergestellt sein, dass in der referenzierten Tabelle auch wirklich ein Datensatz für diesen Schlüssel existiert. Wenn dies nicht der Fall ist, sollte der Einfügeprozess nicht möglich sein.
- 2. RI-Regel: Ein Datensatz darf nicht gelöscht werden, wenn er in einer anderen Tabelle als Fremdschlüssel genutzt wird. Die Datenbank muss sicherstellen, dass solche Transaktionen nicht möglich sind.
Wenn diese beiden Regeln erfüllt sind, kann es bei Änderungen in der Datenbank nicht zu Inkonsistenzen kommen.
Wie erstellt man referentielle Integrität in einer Datenbank?
Moderne Datenbanksysteme, wie beispielsweise MySQL, stellen sicher, dass keine Transaktionen stattfinden, die die referentielle Integrität verletzen. Im Fall einer Verletzung wird die Transaktion nicht ausgeführt und eine entsprechende Fehlermeldung ausgegeben. Wenn wir beispielsweise einen Kunden in unserem Beispiel mit dem SQL-Statement “DELETE” löschen wollten, würde ein Fehler auftreten, da in der Auftragstabelle noch auf den Kunden referenziert werden würde.
Da es in großen Datenbanken schnell unübersichtlich werden kann und man nicht alle Einträge von Hand löschen will, um die referentielle Integrität sicherzustellen, gibt es einen speziellen SQL-Befehl mit dem man Datensätze löschen kann und die Integrität sichergestellt ist. Mithilfe von “ON DELETE CASCADE” können wir den Kunden löschen und es würden auch automatisch alle Aufträge des Kunden in der Auftragstabelle gelöscht werden, damit die Integrität weiterhin besteht.
In der Realität würde man solch eine Transaktion natürlich nicht ausführen, da sie die Umsatzzahlen verfälscht und stattdessen eher mit einem Status für Kunden arbeiten, der diese entweder als aktiv oder als inaktiv markiert.
Welche Integritätsbestimmungen für Datenbanken gibt es?
Neben der referentiellen Integrität gibt es noch andere Integritätsbestimmungen, die eine Datenbank erfüllen muss, um in einem konsistenten, also einem wahrheitsgemäßen, Zustand sein. Zu diesen zählen:
- Bereichsintegrität: Die Werte in einem Attribut, also in einer Spalte, müssen in einem vordefinierten Bereich liegen. Die Eingabe eines Alters beispielsweise kann nur zwischen 0 und 150 Jahren liegen, wenn ein Eintrag jedoch ein Alter von 200 Jahren hinterlegen will, ist die Bereichsintegrität verletzt.
- Entitätsintegrität: Für jeden Datensatz, also jede Entität, muss ein eindeutiger Primärschlüssel definiert sein.
- Referentielle Integrität: Es muss sichergestellt werden, dass ein Fremdschlüssel auf einen Datensatz verweist. Außerdem kann ein Primärschlüssel nur dann gelöscht werden, wenn der Datensatz in dem der Schlüssel als Fremdschlüssel auftritt, auch gelöscht wird.
- Logische Konsistenz: Je nach Anwendung kann der Benutzer eigene Integritätsbestimmungen aufstellen, die zusätzlich erfüllt sein müssen.
Nur wenn all diese Bestimmungen erfüllt sind, befindet sich die Datenbank in einem konsistenten Zustand.
Wie erhält man die referentielle Integrität einer Datenbank nachhaltig?
Die referentielle Integrität umfasst nicht nur die initiale Einrichtung einer Datenbank, sondern muss auch über den Betrieb hinweg sichergestellt werden, beispielsweise wenn Daten aktualisiert oder gelöscht werden. Deshalb ist es wichtig, sich auch über die korrekte Handhabung dieser Vorgänge Gedanken zu machen und entsprechende Prozesse aufzusetzen.
Aktualisierungen
Wenn Werte oder Zeilen in einer Tabelle aktualisiert werden und Teil einer Beziehung sind, werden die Regeln der referentiellen Integrität genutzt, um sicherzustellen, dass die bestehenden Beziehungen nicht beeinträchtigt werden. Die folgenden Befehle können genutzt werden:
- Kaskaden-Updates: Mit dem Befehl CASCADE wird bei der Aktualisierung eines Primärschlüssels in allen Tabellen mit einer Beziehung automatisch die dazugehörigen Fremdschlüssel auch aktualisiert. Diese Anwendung sollte genutzt werden, damit Änderungen in einer Tabelle in der gesamten Datenbank Anwendung finden.
- Einschränkung von Aktualisierungen: Der gegenläufige Befehl dazu ist NO ACTION, der die Aktualisierungen auf die Bezugsdatensätze verhindert. Dadurch wird die Datenkonsistenz sichergestellt und es kommt zu keinen unbeabsichtigten Änderungen an Schlüsselwerten.
- Null setzen oder Standard setzen: Wenn die Fremdschlüssel mit SET NULL oder SET DEFAULT definiert wurden, kann eine Aktualisierung des Primärschlüssels in einer angehängten Tabelle dazu führen, dass die Fremdschlüsselwerte auf NULL oder den definierten Standardwert gesetzt werden.
Löschungen
Wenn Datensätze gelöscht werden kann es schnell dazu führen, dass referenzierte Datensätze dadurch verwaisen oder Beziehungen ihre Gültigkeit verlieren. Deshalb kann mit den folgenden Befehlen gearbeitet werden, um diese Probleme zu verhindern:
- Kaskadenlöschungen: Genau wie bei der Aktualisierung bewirkt CASCADE auch bei der Löschung, dass Bezugsdatensätze in untergeordneten Tabellen mit gelöscht werden. Jedoch sollte jede Ausführung mit Vorsicht genutzt werden, um Datenverlust durch unbeabsichtigte Löschung zu verhindern.
- Löschungen einschränken: Das Analog zu NO ACTION bei Aktualisierungen ist der Befehl RESTRICT, der bei Löschungen dafür sorgt, dass die Datensätze in Bezugstabellen nicht gelöscht werden. Dadurch stellt die referentielle Integrität sicher, dass die Datenintegrität gewahrt wird und keine versehentliche Datenverluste vorkommen.
- Null setzen oder Standard setzen: Wenn die Tabellen und deren Fremdschlüssel mit SET NULL oder SET DEFAULT eingerichtet wurden, kann die Löschung dazu führen, dass die Fremdschlüssel in den Bezugstabellen auf NULL oder den Default – Wert gesetzt werden.
Abwägungen
- Die CASCADE Funktion ist ein mächtiges und hilfreiches Tool, das jedoch große Auswirkungen haben kann. Deshalb sollte vor der Implementierung von CASCADE Aktionen geprüft werden, welche Änderungen dadurch stattfinden, um einen ungewollten Datenverlust zu verhindern.
- Die geeignete Option zur Sicherstellung der referentiellen Integrität sollte abhängig von den Bedürfnissen an die Datenintegrität gewählt werden.
- Komplexe Beziehungen werden schnell unübersichtlich und sollten vermieden werden, da sie ansonsten bei Aktualisierungen oder Löschungen zu Problemen führen können.
Best Practices
- Ein Datenbankschema hilft die Beziehungen zwischen Tabellen zu dokumentieren und die Einschränkungen der referentiellen Integrität aufzulisten. Dadurch leiten sich klare Regeln für die zukünftige Wartung und Entwicklung der Datenbank ab.
- Bevor es zu Änderungen in der Produktionsdatenbank kommt, sollten Änderungen und Löschungen in Testumgebungen ausgeführt werden, um sicherzustellen, dass es zu keinen unerwünschten Folgen kommt.
- Wenn viele CASCADE Aktionen genutzt werden, sollte die Datenbank regelmäßig auf Anomalien geprüft werden, insbesondere dann, wenn Löschungen oder Aktualisierungen stattgefunden haben.
Löschungen und Aktualisierungen im Rahmen der referentiellen Integrität sind entscheidend, um eine konsistente und genaue Datenbank aufzubauen und zu erhalten. Wenn jedoch die genannten Aktionen berücksichtigt werden, wird sichergestellt, dass Löschungen oder Aktualisierungen nicht zu unerwünschten Nebenwirkungen führen und die Datenbank frei von Inkonsistenzen bleiben.
Was ist die Normalisierung?
Die Normalisierung bezeichnet ein Konzept aus dem Datenbankdesign mit dem Ziel, die Redundanzen, also die Dopplungen in der Datenbank, zu eliminieren. Dadurch lässt sich Speicherplatz sparen und außerdem kommt es nicht mehr zu Anomalien. Die Integrität und die Normalisierung sind zwei eng verwandte Themen in der Datenbanktheorie, weshalb sie immer gemeinsam betrachtet werden sollten.
In der Praxis sind vor allem drei Normalformen von Bedeutung. Denn oft, wenn diese erfüllt sind, ist die Datenbank performant und es musste nur verhältnismäßig wenig Arbeit investiert werden. Somit ist das Kosten-Nutzen-Verhältnis bis zur dritten Normalform vergleichsweise hoch. In der Theorie gibt es jedoch bis zu fünf Normalformen, jedoch beschränken wir uns in diesem Beitrag nur auf die ersten drei:
- Die 1. Normalform ist erreicht, wenn alle Datensätze atomar sind. Das bedeutet, dass jedes Datenfeld lediglich einen Wert enthalten darf. Außerdem sollte sichergestellt sein, dass jede Spalte nur Werte desselben Datentyps (Numerisch, Text, etc.) enthält. Folgende Beispiele müssten entsprechend verändert werden, damit eine Datenbank in der 1. Normalform vorhanden ist:
- Die 2. Normalform ist erfüllt, wenn die erste Normalform erfüllt ist, und außerdem jede Spalte in einer Zeile voll funktional abhängig ist vom Primärschlüssel. Der Primärschlüssel bezeichnet ein Attribut, das zur eindeutigen Identifikation einer Datenbankzeile verwendet werden kann. Dazu zählen beispielsweise die Rechnungsnummer zur Identifikation einer Rechnung oder die Ausweisnummer zur Identifikation einer Person.
- Die 3. Normalform liegt vor, wenn die beiden vorhergehenden Normalformen erfüllt sind, und es zusätzlich keine sogenannten transitiven Abhängigkeiten gibt. Eine transitive Abhängigkeit liegt vor, wenn ein Attribut, welches kein Primärschlüssel ist, nicht nur von diesem abhängt, sondern auch von anderen Attributen.
Das solltest Du mitnehmen
- Die referentielle Integrität beschreibt Bestimmungen über Fremdschlüssel in Datenbank, die zu konsistenten Datensätzen führen.
- Bei der Änderung von Datensätzen muss sichergestellt sein, dass Fremdschlüssel auf existierende Datensätze verweisen und bei der Löschung von Primärschlüsseln auch alle verweisenden Datensätze gelöscht werden.
- Moderne Datenbanksysteme lassen bereits keine Transaktionen zu, die die referentielle Integrität verletzen würden und geben eine entsprechende Fehlermeldung aus.
- Neben der referentiellen Integrität gibt es noch die Bereichsintegrität, die Entitätsintegrität und die logische Konsistenz, die sicherstellen, dass die Konsistenz von Daten gegeben ist.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Referentielle Integrität
IBM hat einen interessanten Artikel zum Thema Referentielle Integrität veröffentlicht.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.