Die Normalisierung bezeichnet ein Konzept aus dem Datenbankdesign mit dem Ziel, die Redundanzen, also die Dopplungen in der Datenbank, zu eliminieren. Dadurch lässt sich Speicherplatz sparen und außerdem kommt es nicht mehr zu Anomalien.
Was versteht man unter einer relationalen Datenbank?
In einer Datenbank werden große Datenmengen, meist strukturiert, abgespeichert und zur Abfrage verfügbar gemacht. Es ist dabei nahezu immer um ein elektronisches System. Theoretisch handelt es sich jedoch auch bei analogen Informationssammlungen, wie beispielsweise bei einer Bibliothek, um eine Datenbank. Bereits in den 1960er Jahren entstand die Notwendigkeit für zentrale Datenspeicher, da Dinge, wie die Zugriffsberechtigung auf Daten oder die Datenprüfung, nicht innerhalb einer Anwendungen, sondern gesondert davon erfolgen sollten.
Die intuitivste Art und Weise diese Informationen abzuspeichern ist in tabellarischer Form, also mit Zeilen und Spalten. Für viele Daten, wie beispielsweise im Rechnungswesen, bietet sich diese Darstellung auch an, da die Daten immer eine feste Form aufweisen. Solche Datenbanken in tabellarischer Form bezeichnet man als relationale Datenbanken, abgeleitet von dem mathematischen Konzept der Relationen.
Welche Ziele hat die Normalisierung der Datenbank?
Mit der Normalisierung einer Datenbank sollen die folgenden Ziele erreicht werden:
- Beseitigung von Redundanzen: Durch die Normalisierung können doppelte Daten gelöscht werden ohne, dass die Datenbank selbst an Informationsgehalt verliert. Das spart Speicherressourcen und führt dadurch auch zu schnelleren Abfragen. Außerdem verringert es das Potenzial von Fehlern, da bei einer Änderung immer alle redundanten Datensätze geändert werden müssten.
- Datenmodell: Durch die Normalisierung ergibt sich oft auch automatisch ein übersichtliches und einheitliches Datenmodell. Eine große Tabelle wird nämlich oft in mehrere, überschaubare Tabellen aufgeteilt und es ergeben sich die bekannten Schemata, wie das Sternschema oder Schneeflockenschema.
Welche Normalformen gibt es?
In der Praxis sind vor allem drei Normalformen von Bedeutung. Denn wenn diese erfüllt sind, ist die Datenbank performant und es musste nur verhältnismäßig wenig Arbeit investiert werden. Somit ist das Kosten-Nutzen-Verhältnis bis zur dritten Normalform vergleichsweise hoch. In der Theorie gibt es jedoch bis zu fünf Normalformen, jedoch beschränken wir uns in diesem Beitrag nur auf die ersten drei.
Hierbei ist auch wichtig, dass die Normalformen aufeinander aufbauen. Das bedeutet, dass eine hohe Normalform nur dann erfüllt ist, wenn auch alle (!) vorhergegangenen Normalformen erfüllt sind.
1. Normalform (1NF)
Die 1. Normalform ist erreicht, wenn alle Datensätze atomar sind. Das bedeutet, dass jedes Datenfeld lediglich einen Wert enthalten darf. Außerdem sollte sichergestellt sein, dass jede Spalte nur Werte desselben Datentyps (Numerisch, Text, etc.) enthält. Folgende Beispiele müssten entsprechend verändert werden, damit eine Datenbank in der 1. Normalform vorhanden ist:
- Adresse: “Hauptstraße 1, 12345 Berlin” –> Straße: “Hauptstraße”, Hausnummer: “1”, PLZ: “12345”, Ort: “Berlin”
- Rechnungsbetrag: “128,45 €” –> Betrag: “128,45”, Währung: “€”
2. Normalform (2NF)
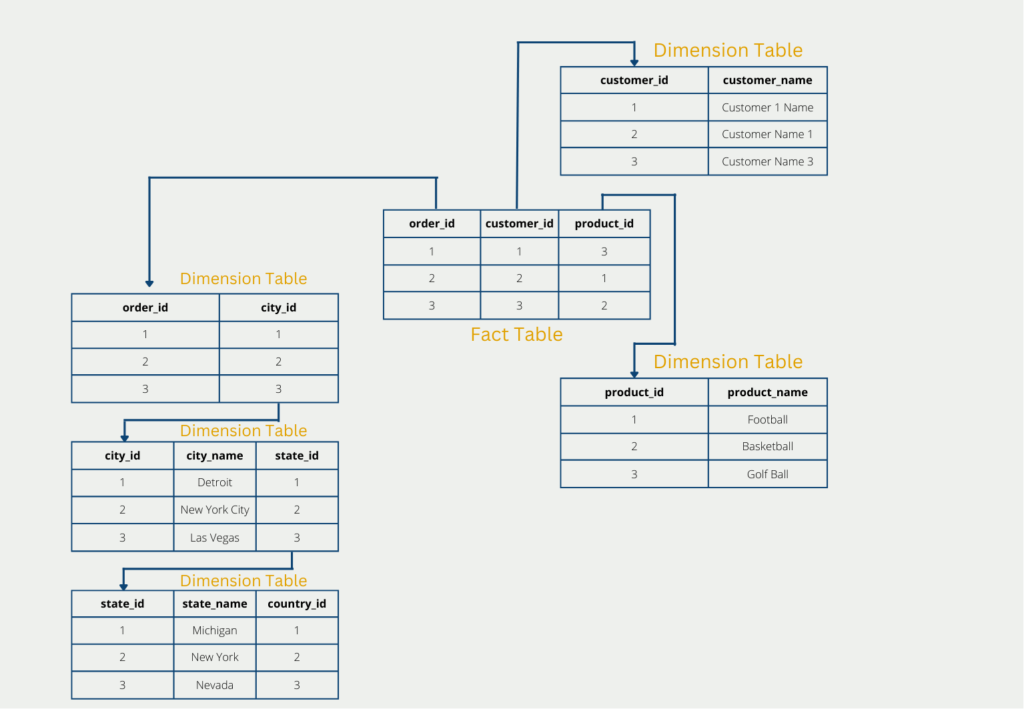
Die 2. Normalform ist erfüllt, wenn die erste Normalform erfüllt ist, und außerdem jede Spalte in einer Zeile voll funktional abhängig ist vom Primärschlüssel. Der Primärschlüssel bezeichnet ein Attribut, das zur eindeutigen Identifikation einer Datenbankzeile verwendet werden kann. Dazu zählen beispielsweise die Rechnungsnummer zur Identifikation einer Rechnung oder die Ausweisnummer zur Identifikation einer Person.
Konkret bedeutet dies in der Anwendung, dass alle Merkmale ausgelagert werden müssen, die nicht ausschließlich vom Primärschlüssel abhängig sind. In der Praxis führt dies dann oft zu einem sogenannten Sternschema.

In unserem Beispiel ist der Kundenname nicht vom Primärschlüssel “order_id” der ursprünglichen Tabelle abhängig. Deswegen muss der Kundenname in einer neuen Tabelle ausgelagert werden. Lediglich der Fremdschlüssel “customer_id” referenziert dann auf die neue Tabelle, sodass keine Information verloren geht.
3. Normalform (3NF)
Die dritte Normalform liegt vor, wenn die beiden vorhergehenden Normalformen erfüllt sind, und es zusätzlich keine sogenannten transitiven Abhängigkeiten gibt. Eine transitive Abhängigkeit liegt vor, wenn ein Attribut, welches kein Primärschlüssel ist, nicht nur von diesem abhängt, sondern auch von anderen Attributen.
Wenn wir in unserem Beispiel eine Tabelle haben, in der die Rechnungsnummer, die Produktnummer und der Preis gegeben ist, haben wir höchstwahrscheinlich eine transitive Abhängigkeit. Der Preis des Produktes hängt nämlich nicht wirklich von der Rechnungsnummer ab, sondern vielmehr von der Produktnummer, da für jedes Produkt ein fester Preis definiert ist.
Diese Abhängigkeit kann man auflösen, indem man die Produkte in eine neue Tabelle auslagert und somit das Attribut Preis aus der ursprünglichen Tabelle rausfällt.
Was sind die Grenzen der Normalisierung?
Relationale Datenbanken werden in die verschiedenen Normalformen überführt, um die Datenintegrität und eine effiziente Datenspeicherung zu gewährleisten. Jedoch bieten die Normalformen nicht nur erhebliche Vorteile, sondern stößt auch an Grenzen, die bei der Arbeit mit Datenbanken beachtet werden sollten. In diesem Kapitel befassen wir uns mit den Grenzen der Datenbanknormalisierung und welche Überlegungen im Vorhinein stattfinden sollten:
- Auswirkungen auf die Leistung: Eine normalisierte Datenbank kann starke Auswirkungen auf die Abfrageleistung haben. Mit der zunehmenden Form werden komplexere Joins und mehr Abfragen nötig, um Daten zu erhalten. Dies führt vor allem bei großen Datenmengen zu erheblich langsameren Abfragen. Dies wird noch zusätzlich dadurch verstärkt, dass durch die Normalisierung mehr Tabellen nötig werden und dadurch zusätzliche Komplexität eingeführt wird.
- Datenredundanz: Das Hauptziel der Normalisierung ist die Beseitigung von Datenredundanzen, durch die Aufteilung der Daten in unterschiedliche Tabellen. Dies führt neben der zusätzlichen Komplexität auch zu deutlichen Leistungseinbußen bei der Datenabfrage. Deshalb können sogenannte Denormalisierungstechniken genutzt werden, um eine gewisse Datenredundanz zuzulassen und dafür die Leistungsfähigkeit zu erhalten.
- Erhöhte Komplexität: Die erhöhte Komplexität der Normalisierung führt vor allem zu aufwendigeren und umfangreicheren Abfragekonstruktionen. Dies führt dazu, dass die Nutzer genügend Kenntnisse in SQL und Datenbankdesign haben müssen, um die Daten richtig abzufragen. Außerdem müssen auch die Administratoren entsprechend die Normalisierungsprinzipien kennen, um die Datenbank effektiv verwalten zu können.
- Herausforderungen bei der Wartung: Die Wartung und Verwaltung einer normalisierten Datenbank sollte nicht unterschätzt werden. Denn auch die Änderung oder Löschung von Daten kann Operationen in verschiedenen Tabellen erfordern. Wenn diese nicht stattfinden, ist das Risiko für Inkonsistenzen hoch.
- Flexibilität und Anpassungsfähigkeit: Neben der Instandhaltung wird natürlich auch die Erweiterung und Anpassung deutlich komplexer. Das Hinzufügen von neuen Attributen oder Änderungen in der Datenstruktur erfordern aufgrund der Normalisierung meist auch Änderungen in verschiedenen Tabellen.
- Gleichgewicht zwischen Normalisierung und Leistung: Nicht immer ist eine höhere Normalisierungsform auch die optimale Wahl für ein Datenbanksystem. Es muss im Einzelfall ein Gleichgewicht zwischen ausreichender Normalisierung / Datenintegrität und Denormalisierung für eine optimale Leistung gefunden werden.
- Kompromisse bei der Berichterstellung und Analyse: Neben der Datenspeicherung an sich, sollten bei der Konzeption von Datenbanken auch die nachfolgenden Prozesse, wie beispielsweise das Berichtswesen berücksichtigt werden. Durch die Normalisierung kann es auch hier zur Beeinträchtigung von Performance kommen, wenn das Aggregieren der Daten deutlich länger dauert.
- Kontextspezifische Überlegungen: Die Normalisierung sollte im Einzelfall für die Anwendung geprüft werden und eine entsprechende Entscheidung getroffen werden. Dazu zählt beispielsweise auch die Prüfung der Datentypen und ob diese normalisiert werden sollten. Beispielsweise bei Protokollen kann es passieren, dass höhere Normalisierungsstufen nicht wirklich vorteilhaft sind.
Die Normalisierung von Datenbanksystemen sichert zwar die Datenintegrität, jedoch hat es auch einen großen Einfluss auf die Arbeit mit Datenbanken. Deshalb ist eine sorgfältigte Bewertung der Kompromisse zwischen Normalisierung und Leistung unumgänglich. Nur dann ist eine effektive Datenverwaltung möglich.
Was ist das Konzept der Denormalisierung?
Die Denormalisierung ist eine Methode zur Optimierung der Datenbankleistung, indem gezielte Redundanzen in ein normalisiertes Datenbankschema eingeführt werden. Während die Normalisierung eigentlich versucht diese Redundanzen zu beseitigen, setzt die Denormalisierung diese gezielt ein, um die Abfrageleistung zu verbessern und die Effizienz des Systems zu steigern.
Durch die absichtliche Duplizierung von Tabellen oder einer weniger stark aufgeteilten Struktur, wird der Bedarf für komplexe Joins bei der Datenabfrage verringert und somit die Abfrageleistung erhöht. Bei der Denormalisierung werden verschiedene Techniken genutzt, wie zum Beispiel:
- Abflachen von Tabellen: Hierbei werden mehrere Tabellen in einer einzigen zugesammengefasst, um den Bedarf für Joins zu verringern. Dadurch lassen sich Abfragen deutlich vereinfachen und die Leistung wird verbessert, da nicht so viele Leseoperationen getätigt werden müssen.
- Hinzufügen redundanter Daten: Bei diesem Ansatz werden Daten aus einer Tabelle dupliziert mit dem Ziel die Notwendigkeit von Joins zu verringert. Auch hierdurch wird die Abfrageleistung verbessert. Diese Methode macht vor allem Sinn für häufig abgefragte Informationen.
- Abgeleitete Spalten einführen: Ein weiteres Mittel der Denormalisierung ist die Einführung von berechnenden Spalten, die abgeleitete oder berechnete Werte enthalten kann. Dadurch müssen diese nicht live währen der Abfrage berechnet werden, wodurch sich wiederum die Leistung verbessern lässt.
Die Denormalisierung kommt vor allem bei Anwendungen zum Einsatz, in denen die Abfrageleistung einen hohen Stellenwert hat, wie beispielsweise beim Data Warehousing und dem Business Intelligence. Jedoch muss natürlich beachtet werden, dass es aufgrund dieser Methoden zu Dateninkonsistenzen kommen. Zusätzlich ist der Speicherbedarf auch höher, da Daten gezielt doppelt gespeichert werden.
Genauso wie die Normalisierung, sollte auch die Nutzung der Denormalisierung gut durchdacht sein und abhängig vom Anwendungsfall genutzt werden. Es kann keine allgemeingültige Aussage getroffen werden, ob grundsätzlich auf die Normalisierung oder die Denormalisierung zurückgegriffen werden sollte. Vielmehr sollte ein gesundes Gleichgewicht zwischen beiden Extremen gefunden werden, das den Anforderungen entspricht.
Das solltest Du mitnehmen
- Unter der Normalisierung einer Datenbank versteht man das systematische Eliminieren von Redundanzen.
- Dadurch lassen sich sowohl Speicherplatz sparen, als auch Abfragen performanter gestalten.
- In der Praxis werden häufig nur die ersten drei Normalformen umgesetzt, da bei diesen das Kosten-Nutzen-Verhältnis am höchsten ist.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Normalisierung
Auf Wikipedia gibt es einen ausführlichen Artikel zur Normalisierung von Datenbanken.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.