Das Snowflake Schema beschreibt die Anordnung von Datenbanktabellen, die möglichst speichereffizient und leistungsstark sein sollen. Wie der Name bereits verrät, sind die Tabellen dabei schneeflockenförmig in einer sogennanten Faktentabelle angeordnet, die von mehreren sogenannten Dimensionstabellen umgeben ist.
Was ist das Snowflake-Schema?
Bei großen Datenmengen wird die Speicherung in Datenbanken oder dem Data Warehouse schnell unübersichtlich und Abfragen sind nicht nur kompliziert, sondern dauern auch relativ lange. Deshalb benötigt man intelligente Wege, um Tabellen anzulegen, sodass Speicher gespart werden kann und somit Abfragen schneller stattfinden können.
Ein Ansatz dafür ist das sogenannte Snowflake Schema, welches eine weitere Ausbaustufe des Star Schemas darstellt. Dabei werden in Fakten- und Dimensionstabellen unterschieden:
- Die Fakten sind Kennzahlen oder Messwerte, die analysiert oder veranschaulicht werden sollen. Sie bilden den Mittelpunkt der Analyse und stehen in der zentralen Faktentabelle. Diese besteht neben den Kennzahlen noch aus den Schlüsseln, die auf die umliegenden Dimensionen verweisen. Im Unternehmensumfeld sind Fakten beispielsweise die Umsatzmenge, der Umsatz oder der Auftragseingang.
- Die Dimensionen hingegen sind die Eigenschaften der Fakten und können genutzt werden, um die Kennzahlen zu visualisieren. In diesen sind dann die verschiedenen Detailstufen der Dimensionen gespeichert und somit kann Speicher gespart werden, da die Details nur ein einziges Mal in der Dimensionstabelle hinterlegt werden müssen. Dimensionen im Unternehmensumfeld sind beispielsweise die Kundeninformationen, das Datum des Auftrags oder Produktinformationen.
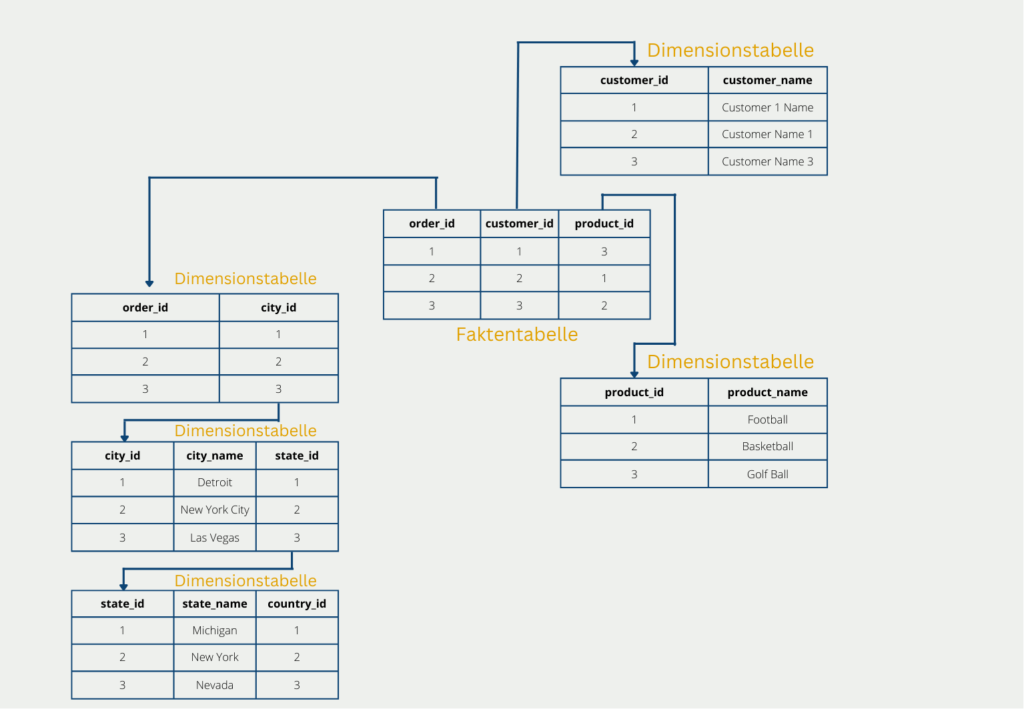
Das sogenannte Schneeflocken-Schema hat das Ziel die Tabellen komplett zu normalisieren und dadurch die Nachteile des Starschemas gewissermaßen zu umgehen. Der Aufbau einer Schneeflocke ergibt sich kurzgesagt dadurch, dass die Dimensionstabellen noch weiter aufgeschlüsselt und klassifiziert werden. Die Faktentabelle hingegen bleibt unverändert.
In unserem Beispiel könnte das dazu führen, dass die Dimensionstabelle mit den Lieferadressen weiter klassifiziert wird in Land, Bundesland und Stadt. Dadurch werden die Tabellen normalisiert und es ist auch die dritte Normalform erfüllt, jedoch geht dies zu Lasten von weiteren Verzweigungen. Diese sind vor allem bei einer späteren Abfrage nachteilig, da diese mit aufwändigen Joins wieder zusammengefügt werden müssen.
Die Weiterverzweigung führt also dazu, dass die Daten weniger redundant abgespeichert werden und dadurch die Datenmenge nochmal weiter reduziert wird im Vergleich zum Starschema. Dies geht jedoch zu Lasten der Performance, da bei der Abfrage die Dimensionstabellen wieder zusammengeführt werden müssen, was häufig sehr aufwändig ist.
Was ist die Normalisierung?
Wenn Daten in Datenbanken abgelegt werden, kann dies schnell sehr unübersichtlich und redundant werden. Deshalb sollte man sich bei der Erstellung eines Datenbankschemas darüber Gedanken machen, wie sich redundante Informationen, also beispielsweise Duplikate vermeiden lassen.
Die Normalisierung ist dabei eine Abfolge von verschiedenen Schritten, die mehr und mehr vermeidbare Redundanzen verhindern sollen. Dazu gibt es die sogenannten Normalformen, die aufeinander aufbauen und immer strengere Regeln aufweisen. Für das Snowflakeschema sind lediglich die ersten drei Normalenformen interessant, da eine Datenbank im Sternenschema lediglich die ersten zwei Normalformen erfüllt, nicht aber die dritte:
- Eine Datenbank ist in der 1. Normalform, wenn alle Attribute/Spalten lediglich einen einzigen Wert aufweisen. Das heißt in keinem Feld kommt es zu einer Ansammlungen von Werten.
- Eine Datenbank befindet sich in der 2. Normalform, wenn jedes Attribut der Tabelle voll vom Primärschlüssel abhängig ist. Das bedeutet auch, dass alle Attribute, die nicht vom Primärschlüssel abhängen in eine separate Datenbanktabelle ausgelagert werden müssen. Natürlich muss eine Datenbank, die in der 2. Normalform ist, auch gleichzeitig die 1. Normalform erfüllen, da diese aufeinander aufbauen. Dasselbe gilt auch für die nachfolgenden Normalformen.
- Eine Datenbank ist in der 3. Normalform, wenn kein Attribut, das nicht Primärschlüssel der Tabelle ist, nicht auf ein anderes Nichtschlüsselattribut hinweist. Wenn dies der Fall ist, muss dafür eine neue Relation, also eine neue Tabelle, erstellt werden.
Das Sternenschema verfehlt, im Vergleich zum Snowflake Schema, in den meisten Fällen die dritte Normalform, da in der Dimensionstabellen häufig mehrere Attribute vorkommen, die zwar kein Primärschlüsselattribut sind und trotzdem aufeinander hinweisen. In der Dimensionstabelle “Produkte” lässt sich der Preis beispielsweise durch die Kombination aus dem “Produktnamen” und der “Farbe” bestimmen, obwohl weder der Produktname noch die Farbe ein Primärschlüsselattribut sind.
Was sind die Vor- und Nachteile des Snowflake Schemas?
Durch die Einhaltung der Normalisierung gibt es keine redundanten Daten, was wiederum zur Einsparung von Speicherplatz führt. Neben dem Speicherplatz kann das Snowflake Schema dadurch auch Abfragezeit einsparen, da die Dimensionstabellen deutlich kleiner sind. Jedoch wird dieser Effekt auch gewissermaßen wieder zunichte gemacht, da durch das Schneeflocken Design die Zusammenhänge zwischen den Tabellen wiederum komplexer werden, was die Abfragezeit erhöht.
Die größere Anzahl an Tabellen macht den Datenspeicher unübersichtlicher, wodurch es für Laien nur schwierig möglich ist, den Datensatz direkt zu verstehen und die tatsächlichen Zusammenhänge zu erkennen.
Sternschema vs. Snowflake Schema
Das Starschema und das Snowflake-Schema sind relativ ähnlich aufgebaut und werden auch deshalb oft miteinander verglichen. Tatsächlich hängt die Wahl eines passenden Datenbankschemas vor allem von der konkreten Anwendung ab.
Kurz gesagt ist das Ziel des Starschemas eine gute Grundlag, wenn häufige Abfragen stattfinden sollen und trotzdem die Datenmenge verringert werden soll. Das wird erzeugt, indem eine Aufspaltung in Fakten- und Dimensionstabellen vorgenommen wird. Dadurch lassen sich viele Redundanzen entfernen und die ersten zwei Normalformen erfüllen. Die Zahl der Tabellen bleibt verhältnismäßig klein und dadurch sind Abfragen mit wenigen Joins und schnellen Antwortzeiten möglich. Jedoch kann keine vollständige Normalisierung der Datenbank erfolgen und einige Redundanzen bleiben bestehen.

Das Schneeflocken-Schema hingegen ist eine Weiterentwicklung des Starschemas mit dem Ziel, eine Normalisierung der Datenbank herbeizuführen. Dabei wird die Faktentabelle beibehalten und die Dimensionstabellen werden noch weiter klassifiziert und in weitere Relationen aufgeteilt. Dadurch werden zwar die verbleibenden Redundanzen des Starschemas beseitigt, jedoch werden Abfragen dadurch langsamer und aufwändiger, da die Dimensionstabellen erst wieder zusammengeführt werden müssen.
Wie performant ist das Snowflake Schema?
Das Snowflake-Schema, das für seine normalisierte Struktur bekannt ist, bietet bestimmte Vorteile und Kompromisse hinsichtlich der Skalierbarkeit und Leistung. Hier ist eine Erkundung, wie das Snowflake-Schema mit diesen Aspekten umgeht:
1. Normalisierung für Effizienz:
- Das Snowflake Schema ist mit einem hohen Grad an Normalisierung konzipiert, was die Datenredundanz minimiert und die Datenintegrität sicherstellt.
- Die Normalisierung verbessert die Effizienz der Datenspeicherung, indem der benötigte Speicherplatz reduziert wird, was für große Datensätze vorteilhaft sein kann.
2. Komplexe Joins:
- Eine der Hauptmerkmale des Snowflake Schemas ist seine komplexe Join-Struktur.
- Um sinnvolle Informationen abzurufen, erfordern Abfragen oft mehrere Joins zwischen normalisierten Tabellen, was die Abfrageleistung potenziell beeinflussen kann.
3. Überlegungen zur Abfrageleistung:
- Während die Normalisierung des Snowflake Schemas für die Datenkonsistenz vorteilhaft ist, kann sie zu komplexen SQL-Abfragen mit zahlreichen Joins führen.
- Die Datenbankleistung kann beeinträchtigt werden, wenn komplexe, mehrfache Tabellen-Joins, insbesondere für ad-hoc- oder analytische Abfragen, verwendet werden.
4. Indexierung und Optimierung:
- Zur Verbesserung der Abfrageleistung im Snowflake-Schema sind sorgfältige Indexierung und Abfrageoptimierung erforderlich.
- Indizes auf häufig verwendeten Join-Spalten und gut strukturierte Abfragen sind unerlässlich, um eine gute Leistung aufrechtzuerhalten.
5. Datenlagerplattformen:
- Moderne Datenlagerplattformen sind mit den komplexen Abfrageanforderungen des Snowflake-Schemas ausgestattet.
- Diese Plattformen bieten oft Funktionen wie parallele Verarbeitung, Abfrageoptimierung und Zwischenspeicherung, um die Leistung zu verbessern.
6. Aggregationstabellen:
- Ähnlich wie beim Star Schema können Snowflake Schema Implementierungen von der Verwendung von Aggregationstabellen profitieren.
- Aggregationstabellen speichern vorberechnete Zusammenfassungen und reduzieren die Notwendigkeit umfangreicher Joins und Berechnungen während der Abfrageausführung.
7. Skalierungsoptionen:
- Das Snowflake Schema kann horizontal und vertikal skalieren, ähnlich wie andere Datenbankschemata.
- Vertikales Skalieren beinhaltet die Erhöhung der Ressourcen (CPU, Speicher) des Datenbankservers, um größere Datensätze zu verarbeiten.
- Horizontales Skalieren kann durch Techniken wie Sharding oder Aufteilung auf mehrere Server oder Cluster erreicht werden.
8. Berücksichtigung komplexer Abfragen:
- Komplexe ad-hoc-Abfragen, die das Verbinden mehrerer normalisierter Tabellen erfordern, können Herausforderungen in Bezug auf die Abfrageleistung darstellen.
- Eine sorgfältige Abfragegestaltung und -optimierung sind erforderlich, um akzeptable Abfrageantwortzeiten aufrechtzuerhalten.
9. Datenkompression und Speicherung:
- Datenkompressionstechniken können angewendet werden, um den Speicherbedarf zu reduzieren und die Geschwindigkeit der Datenabfrage in Snowflake-Schema-Datenbanken zu verbessern.
- Spaltenorientierte Speicherformate und Kompressionsalgorithmen werden häufig in Snowflake-Schema-Implementierungen verwendet.
Zusammenfassend bietet das Snowflake-Schema Vorteile in Bezug auf Datenintegrität und Speichereffizienz aufgrund seiner hohen Normalisierung. Seine komplexe Join-Struktur kann jedoch zu Herausforderungen in Bezug auf die Abfrageleistung führen, insbesondere bei komplexen ad-hoc-Abfragen. Um diese Herausforderungen zu bewältigen, profitieren Snowflake-Schema-Implementierungen von einer geeigneten Indexierung, Abfrageoptimierung und der Verwendung von Aggregationstabellen. Moderne Datenlagerplattformen unterstützen die Verwaltung der Leistung von Snowflake-Schema-Datenbanken bei steigender Datenmenge.
Das solltest Du mitnehmen
- Das Snowflake Schema ist ein Datenbankschema, das zum Ziel hat, die Daten in normalisierter Form abzuspeichern und dadurch Redundanzen zu verhindern.
- Das Snowflake Schema ist eine Weiterentwicklung des Starschemas, da es mehrere Stufen an Dimensionstabellen hat, die für die Normalisierung genutzt werden.
- Durch die Eliminierung von Redundanzen wird der Speicherplatz beim Snowflake Schema optimiert. Jedoch geht dies zu Lasten der Verständlichkeit, da komplexe n:m Beziehungen aufgebaut werden.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Snowflake Schema
Microsoft hat auch einen kurzen Beitrag zum Thema Snowflake Schema veröffentlicht.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.