The snowflake schema describes the arrangement of database tables, which should be as memory-efficient and powerful as possible. As the name suggests, the tables are arranged in the shape of snowflakes in a so-called fact table, which is surrounded by several so-called dimension tables.
What is the Snowflake Schema?
With large amounts of data, storage in databases or the data warehouse quickly becomes confusing and queries are not only complicated but also take a relatively long time. Therefore, intelligent ways are needed to create tables so that memory can be saved and queries can take place more quickly.
One approach to this is the so-called Snowflake Schema, which represents a further expansion stage of the Star Schema. A distinction is made between fact tables and dimension tables:
- The facts are key figures or measured values that are to be analyzed or illustrated. They form the center of the analysis and are located in the central fact table. In addition to the key figures, this also consists of the keys that refer to the surrounding dimensions. In the business environment, facts are, for example, the sales quantity, the turnover, or the incoming orders.
- The dimensions, on the other hand, are the properties of the facts and can be used to visualize the key figures. The different levels of detail of the dimensions are then stored in these and thus memory can be saved since the details only have to be stored once in the dimension table. Dimensions in the corporate environment are, for example, customer information, the date of the order, or product information.
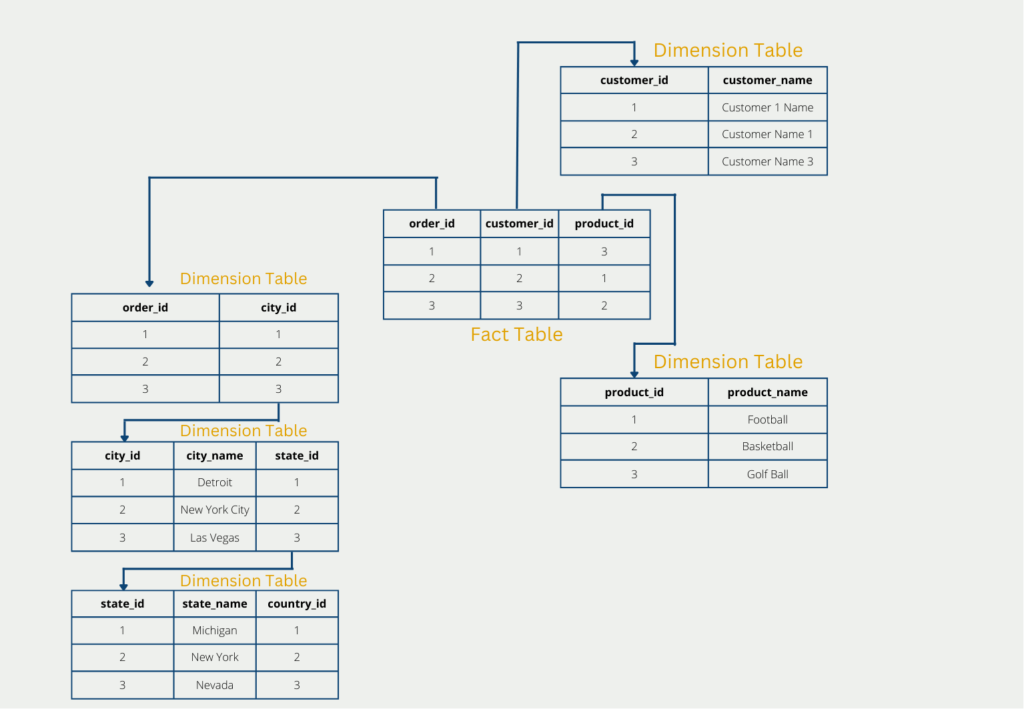
The so-called snowflake scheme has the goal to normalize the tables completely and thus circumvent the disadvantages of the star schema to a certain extent. The structure of snowflake results, in short, from the fact that the dimension tables are broken down and classified even further. The fact table, however, remains unchanged.
In our example, this could lead to the dimension table with the delivery addresses being further classified into country, state, and city. This normalizes the tables and the third normal form is also fulfilled, but this is at the expense of further branches. These are particularly disadvantageous in the case of a later query since these must be reassembled with complex joins.
The further branching thus leads to the fact that the data are stored less redundantly and thus the amount of data is reduced again in comparison to the star schema. However, this is at the expense of performance, since the dimension tables have to be merged again during the query, which is often very time-consuming.
What is Normalization?
When data is stored in databases, this can quickly become very confusing and redundant. Therefore, when creating a database schema, one should think about how redundant information, for example, duplicates, can be avoided.
Normalization is a sequence of different steps that are intended to prevent more and more avoidable redundancies. For this purpose, there are the so-called normal forms, which build on each other and have increasingly strict rules. For the snowflake scheme, only the first three normal forms are interesting, since a database in the star scheme only fulfills the first two normal forms, but not the third:
- A database is in 1st normal form when all attributes/columns have only a single value. That is, there is no accumulation of values in any field.
- A database is in 2nd normal form when every attribute in the table is fully dependent on the primary key. This also means that all attributes that do not depend on the primary key must be swapped out to a separate database table. Of course, a database that is in 2nd normal form must also satisfy 1st normal form at the same time, since they build on each other. The same applies to the subsequent normal forms.
- A database is in 3rd normal form if no attribute that is not a primary key of the table does not refer to another non-key attribute. If this is the case, a new relation, i.e. a new table, must be created for it.
The star schema, compared to the snowflake schema, misses the third normal form in most cases, because the dimension tables often contain several attributes that are not primary key attributes but nevertheless refer to each other. In the dimension table “Products”, for example, the price can be determined by the combination of the “Product name” and the “Color”, although neither the product name nor the color is a primary key attribute.
What are the advantages and disadvantages of the Snowflake Schema?
By adhering to normalization, there is no redundant data, which in turn leads to storage space savings. In addition to the storage space, the snowflake scheme can also save query time, since the dimension tables are significantly smaller. However, this effect is also to a certain extent canceled out again, since the snowflake design makes the relationships between the tables more complex, which increases the query time.
The larger number of tables makes the data store more confusing, making it difficult for non-experts to directly understand the data set and see the actual relationships.
Star Schema vs. Snowflake Schema
The Star schema and the Snowflake schema are relatively similar in structure and are often compared with each other for this reason. In fact, the choice of a suitable database schema depends mainly on the concrete application.
In short, the goal of the star schema is a good foundation when frequent queries are to take place, and yet the amount of data is to be reduced. This is created by splitting into fact and dimension tables. Thus many redundancies can be removed and the first two normal forms can be fulfilled. The number of tables remains relatively small and thus queries with few joins and fast response times are possible. However, complete normalization of the database cannot be achieved and some redundancies remain.
The snowflake schema, on the other hand, is a further development of the star schema with the aim of bringing about a normalization of the database. The fact table is retained and the dimension tables are further classified and divided into additional relations. Although this eliminates the remaining redundancies of the star schema, it makes queries slower and more time-consuming, since the dimension tables must first be merged again.
How performant is the Snowflake Schema?
The Snowflake Schema, known for its normalized structure, offers certain advantages and trade-offs when it comes to scalability and performance. Here’s an exploration of how the Snowflake Schema handles these aspects:
1. Normalization for Efficiency:
- The Snowflake Schema is designed with a high degree of normalization, minimizing data redundancy and ensuring data integrity.
- Normalization improves data storage efficiency by reducing the storage space required, which can be beneficial for large datasets.
2. Complex Joins:
- One of the key characteristics of the Snowflake Schema is its complex join structure.
- To retrieve meaningful information, queries often involve multiple joins between normalized tables, which can potentially impact query performance.
3. Query Performance Considerations:
- While Snowflake Schema’s normalization is advantageous for data consistency, it can lead to complex SQL queries with numerous joins.
- Database performance can be affected when dealing with complex, multi-table joins, especially for ad-hoc or analytical queries.
4. Indexing and Optimization:
- To enhance query performance in Snowflake Schema, careful indexing and query optimization are necessary.
- Indexes on frequently joined columns and well-structured queries are essential for maintaining good performance.
5. Data Warehousing Platforms:
- Modern data warehousing platforms are equipped to handle the complex querying requirements of Snowflake Schema.
- These platforms often provide features like parallel processing, query optimization, and caching to improve performance.
6. Aggregation Tables:
- Similar to the Star Schema, Snowflake Schema implementations can benefit from the use of aggregation tables.
- Aggregation tables store pre-computed summaries, reducing the need for extensive joins and calculations during query execution.
7. Scalability Options:
- The Snowflake Schema can scale horizontally and vertically, much like other database schemas.
- Vertical scaling involves increasing the resources (CPU, memory) of the database server to handle larger datasets.
- Horizontal scaling can be achieved through techniques like sharding or partitioning across multiple servers or clusters.
8. Consideration for Complex Queries:
- Complex ad-hoc queries that require joining multiple normalized tables may pose challenges in terms of query performance.
- Careful query design and optimization are necessary to maintain acceptable query response times.
9. Data Compression and Storage:
- Data compression techniques can be applied to reduce storage requirements, helping to improve data retrieval speed in Snowflake Schema databases.
- Columnar storage formats and compression algorithms are commonly used in Snowflake Schema implementations.
In summary, the Snowflake Schema offers advantages in terms of data integrity and storage efficiency due to its high degree of normalization. However, its complex join structure can lead to challenges in query performance, particularly for complex ad-hoc queries. To mitigate these challenges, Snowflake Schema implementations benefit from proper indexing, query optimization, and the use of aggregation tables. Modern data warehousing platforms provide support for managing the performance of Snowflake Schema databases as data scales.
This is what you should take with you
- The Snowflake schema is a database schema that aims to store data in a normalized form, thus preventing redundancies.
- The Snowflake schema is a further development of the Star schema since it has several levels of dimension tables that are used for normalization.
- By eliminating redundancies, the Snowflake scheme optimizes memory space. However, this is at the expense of comprehensibility, since complex n:m relationships are established.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Snowflake Schema
Microsoft has also published a short article about the Snowflake schema.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.