Stream Processing ist eine leistungsstarke Datenverarbeitungstechnik, die in den letzten Jahren aufgrund ihrer Fähigkeit, große Mengen an Echtzeitdaten zu verarbeiten, an Popularität gewonnen hat. In diesem Artikel werden wir untersuchen, was Stream Processing ist, wie es funktioniert und welche verschiedenen Anwendungen es gibt.
Was ist Stream Processing?
Streaming ist eine Datenverarbeitungstechnik, bei der Daten kontinuierlich verarbeitet und analysiert werden, sobald sie anfallen. Dies steht im Gegensatz zur Stapelverarbeitung, bei der die Daten nach ihrer Erfassung in Stapeln verarbeitet werden. Die Stream-Verarbeitung wird häufig in Anwendungen eingesetzt, bei denen geringe Latenzzeiten und ein hoher Durchsatz erforderlich sind, z. B. im Finanzwesen, im Gesundheitswesen und im Transportwesen.
Bei der Stream-Verarbeitung werden Daten in kleinen Stapeln oder einzeln verarbeitet, sobald sie von einer Quelle erzeugt werden. Die Daten werden in der Regel anhand einer Reihe von Regeln oder Algorithmen verarbeitet, die im Voraus festgelegt wurden. Bei der Verarbeitung der Daten können diese in Echtzeit analysiert und verarbeitet werden.
Stream-Processing-Systeme bestehen in der Regel aus mehreren Komponenten, darunter eine Datenquelle, eine Verarbeitungsmaschine und eine Datensenke. Die Datenquelle kann ein Sensor, eine Datenbank oder eine andere Art von Datengenerator sein. Die Verarbeitungs-Engine ist für die Verarbeitung und Analyse der Daten zuständig und kann Tools wie Apache Flink, Apache Spark Streaming und Apache Storm umfassen. Die Datensenke kann eine Datenbank, ein Dateisystem oder eine andere Art von Speichermechanismus sein.
Was sind die Anwendungen von Stream Processing?
Stream Processing hat viele Anwendungen in verschiedenen Bereichen, darunter:
- Finanzdienstleistungen: Stream Processing wird in der Finanzdienstleistungsbranche für die Betrugserkennung, das Risikomanagement und den algorithmischen Handel eingesetzt. Durch die Verarbeitung großer Mengen von Echtzeitdaten können Finanzinstitute betrügerische Aktivitäten und Markttrends schnell erkennen und darauf reagieren.
- Gesundheitswesen: In der Gesundheitsbranche wird es für die Patientenüberwachung in Echtzeit, die Krankheitsüberwachung und die Arzneimittelentwicklung eingesetzt. Durch die Analyse großer Mengen von Patientendaten können Gesundheitsdienstleister die Ergebnisse für die Patienten verbessern und die Kosten senken.
- Transportwesen: Die Datenstromverarbeitung wird in der Transportbranche zur Verkehrsüberwachung, Routenoptimierung und vorausschauenden Wartung eingesetzt. Durch die Verarbeitung von Echtzeitdaten aus Sensoren und anderen Quellen können Transportunternehmen die Effizienz und Sicherheit ihrer Abläufe verbessern.
- Internet der Dinge (IoT): Es wird für die Echtzeit-Überwachung und -Steuerung von IoT-Geräten in verschiedenen Branchen eingesetzt, z. B. in der Fertigung, im Energiesektor und in der Landwirtschaft. Durch die Verarbeitung von Daten von Sensoren und anderen Geräten können IoT-Systeme auf veränderte Bedingungen reagieren.
Warum verwendet man Stream Processing?
Stream Processing wird verwendet, wenn es um Echtzeitdaten geht, die verarbeitet und analysiert werden müssen, sobald sie erzeugt werden. Bei der Stapelverarbeitung hingegen werden die Daten in großen Stapeln verarbeitet, nachdem sie gesammelt worden sind. Der Vorteil der Stream-Verarbeitung besteht darin, dass sie eine sofortige Reaktion auf sich ändernde Daten ermöglicht, was sie ideal für Anwendungsfälle macht, die eine schnelle und genaue Entscheidungsfindung erfordern, wie z. B. Betrugserkennung, Echtzeitüberwachung und vorausschauende Wartung.
Ein weiterer Vorteil der Datenstromverarbeitung ist die Fähigkeit, große Datenmengen effizient zu verarbeiten. Durch die Verarbeitung von Daten in kleinen Stapeln oder einzeln können Stream-Processing-Systeme Daten mit hoher Geschwindigkeit verarbeiten und gleichzeitig Genauigkeit und Zuverlässigkeit gewährleisten.
Die Stream-Verarbeitung ist außerdem kosteneffizient, da sie die Verarbeitung und Analyse von Daten in Echtzeit ermöglicht und so den Bedarf an teurer Speicher- und Verarbeitungsinfrastruktur reduziert. Dies ist besonders wichtig, wenn es um große Datenmengen geht, da es schwierig und teuer sein kann, alle Daten auf einmal zu speichern und zu verarbeiten.
Insgesamt ist die Datenstromverarbeitung ein leistungsfähiges Werkzeug für den Umgang mit Echtzeitdaten, die schnell und effizient verarbeitet und analysiert werden müssen. Die Fähigkeit, große Datenmengen mit hoher Geschwindigkeit zu verarbeiten und gleichzeitig Genauigkeit und Zuverlässigkeit zu gewährleisten, macht sie zu einer idealen Lösung für eine Vielzahl von Anwendungsfällen.
Was ist der Unterschied zwischen Stream Processing und Stapelverarbeitung?
Die Entscheidung über die Architektur der Datenverarbeitung ist relativ schwierig und hängt vom Einzelfall ab. Dabei kann es auch sein, dass heute noch keine Echtzeit-Datenverarbeitung erforderlich ist, sich dies aber in naher Zukunft wieder ändern wird. Es ist daher wichtig, herauszufinden, welcher Zeithorizont für die jeweilige Anwendung erforderlich ist.
Die Stapelverarbeitung eignet sich für die Verarbeitung großer Datenmengen, die in der Regel in regelmäßigen Abständen anfallen. In diesen Fällen bietet die Stapelverarbeitung eine hohe Effizienz und Automatisierung des Prozesses bei vergleichsweise geringen Kosten.
Wenn der Schwerpunkt auf der Echtzeitverarbeitung der Daten liegt, sollte die stromweise Verarbeitung verwendet werden. Dies ist auch dann sinnvoll, wenn laufend neue Datensätze anfallen, wie dies z.B. bei Sensordaten der Fall ist. Allerdings ist der Implementierungs- und Wartungsaufwand deutlich höher, da das System ständig erreichbar sein muss und somit ständig Rechnerressourcen blockiert werden.
Was ist Kafka Stream Processing?
Apache Kafka ist eine Open-Source-Event-Streaming-Plattform, die es Unternehmen ermöglicht, Echtzeit-Datenströme zu erstellen und Daten zu speichern. Sie wurde 2011 von LinkedIn entwickelt und anschließend als Open Source zur Verfügung gestellt. Seitdem hat sich die Verwendung von Kafka als Event-Streaming-Lösung weit verbreitet.
Apache Kafka ist als Computercluster aufgebaut, der aus Servern und Clients besteht.
Die Server, die so genannten Broker, schreiben Daten mit Zeitstempeln in die Topics, wodurch die Datenströme entstehen. In einem Cluster kann es verschiedene Topics geben, die durch die Topic-Referenz getrennt werden können. In einem Unternehmen kann es zum Beispiel ein Topic mit Daten aus der Produktion und wieder ein Topic für Daten aus dem Vertrieb geben. Der sogenannte Broker speichert diese Nachrichten und kann sie auch im Cluster verteilen, um die Last gleichmäßiger zu verteilen.
Das schreibende System in der Kafka-Umgebung wird als Producer bezeichnet. Als Gegenstück dazu gibt es die so genannten Consumer, die die Datenströme lesen und die Daten weiterverarbeiten, indem sie sie beispielsweise speichern. Beim Lesen gibt es eine Besonderheit, die Kafka auszeichnet: Der Consumer muss nicht die ganze Zeit die Nachrichten lesen, sondern kann auch nur zu bestimmten Zeiten aufgerufen werden. Die Intervalle hängen von der Aktualität der Daten ab, die die Anwendung benötigt.
Um sicherzustellen, dass der Konsument alle Nachrichten liest, werden die Nachrichten mit dem so genannten Offset “nummeriert”, d. h. mit einer ganzen Zahl, die mit der ersten Nachricht beginnt und mit der jüngsten endet. Wenn wir einen Verbraucher einrichten, “abonniert” er das Thema und merkt sich den frühesten verfügbaren Offset. Nachdem er eine Nachricht verarbeitet hat, merkt er sich, welche Nachrichtenoffsets er bereits gelesen hat, und kann beim nächsten Start genau dort weitermachen, wo er aufgehört hat.
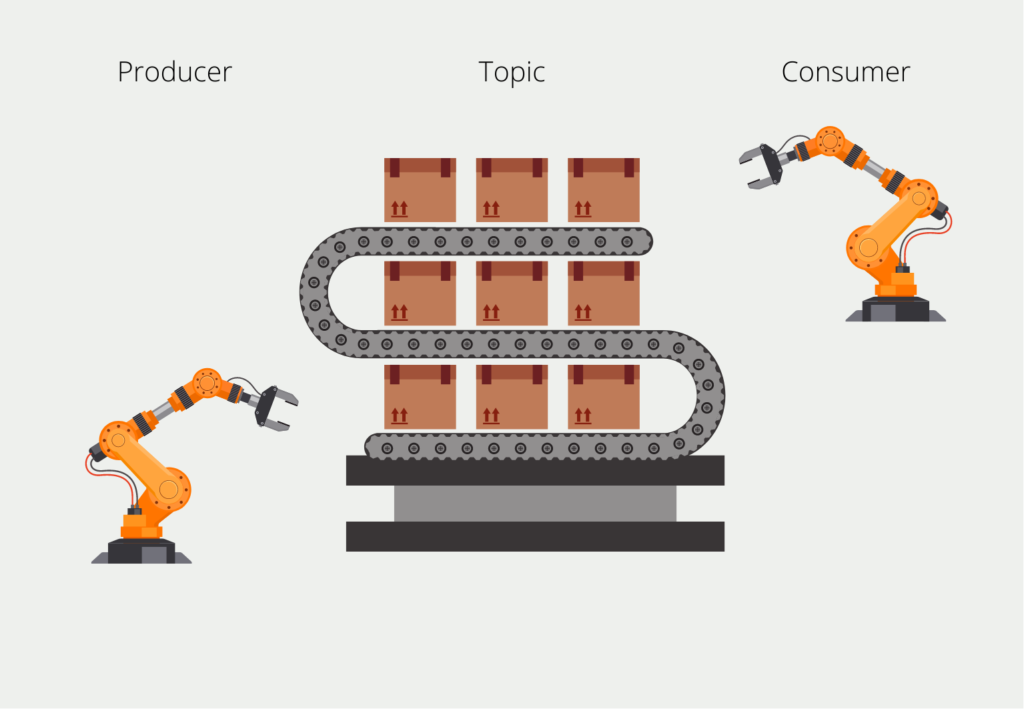
Dies ermöglicht z. B. eine Funktionalität, bei der wir den Verbraucher jede volle Stunde zehn Minuten lang laufen lassen. Dann stellt er fest, dass zehn Nachrichten noch nicht verarbeitet wurden, liest diese zehn Nachrichten und setzt seinen Offset gleich dem der letzten Nachricht. In der folgenden Stunde kann der Konsument dann wieder feststellen, wie viele neue Nachrichten hinzugekommen sind und diese nacheinander abarbeiten.
Ein Thema kann auch in so genannte Partitionen unterteilt werden, die zur Parallelisierung der Verarbeitung genutzt werden können, da die Partitionen auf verschiedenen Rechnern gespeichert sind. Dadurch können auch mehrere Personen gleichzeitig auf ein Thema zugreifen und der Gesamtspeicherplatz für ein Thema kann leichter skaliert werden.
Das solltest Du mitnehmen
- Stream Processing ist eine leistungsstarke Technik für die Datenverarbeitung in Echtzeit, die Unternehmen dabei helfen kann, wertvolle Erkenntnisse zu gewinnen und zeitnahe Entscheidungen auf der Grundlage eingehender Daten zu treffen.
- Die Stream-Verarbeitung ermöglicht die Analyse von Daten, während sie generiert werden, und versetzt Unternehmen in die Lage, Muster und Anomalien zu erkennen.
- Stream Processing kann in einer Vielzahl von Anwendungsfällen eingesetzt werden, darunter Betrugserkennung, vorausschauende Wartung und Echtzeit-Marketing.
- Einer der Hauptvorteile der Stream-Verarbeitung besteht darin, dass sie die Latenzzeit zwischen Datengenerierung und -analyse verkürzt und es Unternehmen ermöglicht, auf der Grundlage von Echtzeiterkenntnissen Maßnahmen zu ergreifen.
- Die Implementierung von Stream Processing kann jedoch ein komplexes Unterfangen sein, das Fachwissen über Big-Data-Technologien und Data Engineering erfordert.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!

Was ist die Bivariate Analyse?
Nutzen Sie die Bivariate Analyse: Erforschen Sie Typen und Streudiagramme und nutzen Sie Korrelation und Regression.
Andere Beiträge zum Thema Stream Processing
Google hat auch einen interessanten Artikel über Stream Processing.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.