Stream processing is a powerful data processing technique that has gained popularity in recent years due to its ability to handle large volumes of real-time data. In this article, we will explore what stream processing is, how it works, and its various applications.
What is Stream Processing?
Streaming is a data processing technique that involves continuously processing and analyzing data as it is generated. This is in contrast to batch processing, where data is processed in batches after it has been collected. Stream processing is often used in applications where low latency and high throughput are required, such as in finance, healthcare, and transportation.
Stream processing involves processing data in small batches or individually, as it is generated by a source. The data is typically processed using a set of rules or algorithms that have been defined beforehand. As the data is processed, it can be analyzed and acted upon in real time.
Stream processing systems typically consist of several components, including a data source, a processing engine, and a data sink. The data source can be a sensor, a database, or any other type of data generator. The processing engine is responsible for processing and analyzing the data and can include tools such as Apache Flink, Apache Spark Streaming, and Apache Storm. The data sink can be a database, a file system, or any other type of storage mechanism.
What are the applications of Stream Processing?
Stream processing has many applications in various fields, including:
- Financial Services: Stream processing is used for fraud detection, risk management, and algorithmic trading in the financial services industry. By processing large volumes of real-time data, financial institutions can quickly identify and respond to fraudulent activities and market trends.
- Healthcare: It is used for real-time patient monitoring, disease surveillance, and drug discovery in the healthcare industry. By analyzing large volumes of patient data, healthcare providers can improve patient outcomes and reduce costs.
- Transportation: Stream processing is used for traffic monitoring, route optimization, and predictive maintenance in the transportation industry. By processing real-time data from sensors and other sources, transportation companies can improve the efficiency and safety of their operations.
- Internet of Things (IoT): It is used for real-time monitoring and control of IoT devices in various industries, such as manufacturing, energy, and agriculture. By processing data from sensors and other devices, IoT systems can respond to changing conditions.
Why does one use Stream Processing?
Stream processing is used when dealing with real-time data that needs to be processed and analyzed as soon as it is generated. Batch processing, on the other hand, involves processing data in large batches after it has been collected. The advantage of stream processing is that it allows for immediate responses to changing data, making it ideal for use cases that require quick and accurate decision-making, such as fraud detection, real-time monitoring, and predictive maintenance.
Another advantage of stream processing is its ability to handle large volumes of data efficiently. By processing data in small batches or individually, stream processing systems can handle data at a high velocity while still ensuring accuracy and reliability.
Stream processing is also cost-effective because it allows for the processing and analysis of data in real time, reducing the need for expensive storage and processing infrastructure. This is particularly important when dealing with large volumes of data, as it can be difficult and expensive to store and process all the data at once.
Overall, stream processing is a powerful tool for dealing with real-time data that needs to be processed and analyzed quickly and efficiently. Its ability to handle large volumes of data at a high velocity, while still ensuring accuracy and reliability, makes it an ideal solution for a wide range of use cases.
What is the difference between stream processing and batch processing?
Deciding on architecture for data processing is relatively difficult and depends on the individual case. At the same time, it may also be the case that real-time data processing is not yet required today, but that this will change again in the near future. It is therefore important to find out what time horizon is required for the application in question.
Batch processing is suitable for processing large volumes of data, which usually occur at regular intervals. In these cases, batch processing offers high efficiency and automation of the process at a comparatively low cost.
If the focus is on real-time processing of the data, streamwise processing should be used. This is also a good idea if new data sets are continuously being generated, as is the case with sensor data, for example. However, the implementation and maintenance effort is significantly higher, since the system must be continuously accessible, and thus computer resources are blocked all the time.
What is Kafka Stream Processing?
Apache Kafka is an open-source event streaming platform that enables organizations to build real-time data streams and store data. It was developed at LinkedIn in 2011 and subsequently made available as open source. Since then, the use of Kafka as an event streaming solution has become widespread.
Apache Kafka is built as a computer cluster consisting of servers and clients.
The servers, or so-called brokers, write data with timestamps into the topics, which creates the data streams. In a cluster, there can be different topics, which can be separated by the topic reference. In a company, for example, there could be a topic with data from production and again a topic for data from sales. The so-called broker stores these messages and can also distribute them in the cluster to share the load more evenly.
The writing system in the Kafka environment is called the producer. As a counterpart, there are the so-called consumers, which read the data streams and process the data, for example by storing them. When reading, there is a special feature that distinguishes Kafka: The consumer does not have to read the messages all the time, but can also be called only at certain times. The intervals depend on the data timeliness required by the application.
To ensure that the consumer reads all messages, the messages are “numbered” with the so-called offset, i.e. an integer that starts with the first message and ends with the most recent. When we set up a consumer, it “subscribes” to the topic and remembers the earliest available offset. After it has processed a message, it remembers which message offsets it has already read and can pick up exactly where it left off the next time it is started.
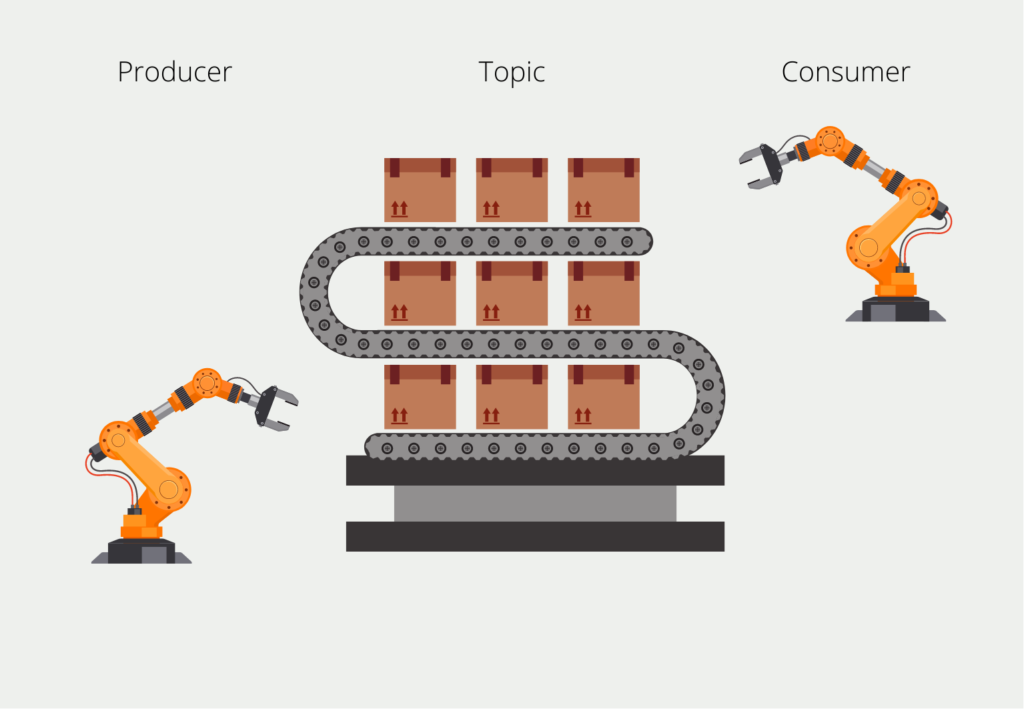
This allows, for example, a functionality in which we let the consumer run every full hour for ten minutes. Then it registers that ten messages have not yet been processed and it reads these ten messages and sets its offset equal to that of the last message. In the following hour, the consumer can then determine again how many new messages have been added and process them one after the other.
A topic can also be divided into so-called partitions, which can be used to parallelize processing because the partitions are stored on different computers. This also allows several people to access a topic at the same time and the total storage space for a topic can be scaled more easily.
This is what you should take with you
- Stream processing is a powerful technique for real-time data processing that can help organizations gain valuable insights and make timely decisions based on incoming data.
- Stream processing allows for the analysis of data as it is generated, enabling organizations to detect patterns and anomalies.
- Stream processing can be applied to a variety of use cases, including fraud detection, predictive maintenance, and real-time marketing.
- One of the key benefits of stream processing is its ability to reduce the latency between data generation and analysis, enabling organizations to take action based on real-time insights.
- However, implementing stream processing can be a complex undertaking, requiring expertise in big data technologies and data engineering.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.

What is the Bivariate Analysis?
Unlock insights with bivariate analysis. Explore types, scatterplots, correlation, and regression. Enhance your data analysis skills.

What is a RESTful API?
Learn all about RESTful APIs and how they can make your web development projects more efficient and scalable.

What is Time Series Data?
Unlock insights from time series data with analysis and forecasting techniques. Discover trends and patterns for informed decision-making.
Other Articles on the Topic of Stream Processing
Google also has an interesting article on Stream Processing.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.