The abbreviation ACID (Atomicity, Consistency, Isolation, Durability) is a term from database theory and describes rules and procedures for database transactions. If ACID specifications are adhered to, the data in a system is reliable and consistent. In the course of the article, in addition to ACID, we also highlight the properties of the CAP theorem that deal not only with databases but with distributed systems. We also highlight the advantages that arise when the ACID properties are satisfied.
What are the A-C-I-D basic principles?
Classical relational databases fulfill the four ACID properties. These state that the most important requirement for a database is to maintain the truthfulness and meaningfulness of the data. In many cases, data stores are seen as a “single point of truth”, thus it would be fatal if erroneous information is stored and passed on. The four properties include the following points:
- Atomicity (A): Data transactions, e.g. the entry of a new data record or the deletion of an old one, should either be executed completely or not at all. The transaction is only visible for other users when it is completely executed.
- Consistency (C): This property is satisfied when each data transaction moves the database from a consistent state to a consistent state.
- Isolation (I): When multiple transactions occur simultaneously, the final state must be the same as if the transactions occurred separately. That is, the database should pass the stress test. In other words, it should not result in incorrect database transactions due to overload.
- Durability (D): The data within the database must only change as a result of a transaction and must not be changeable by external influences. For example, a software update must not inadvertently cause data to change or possibly be deleted.
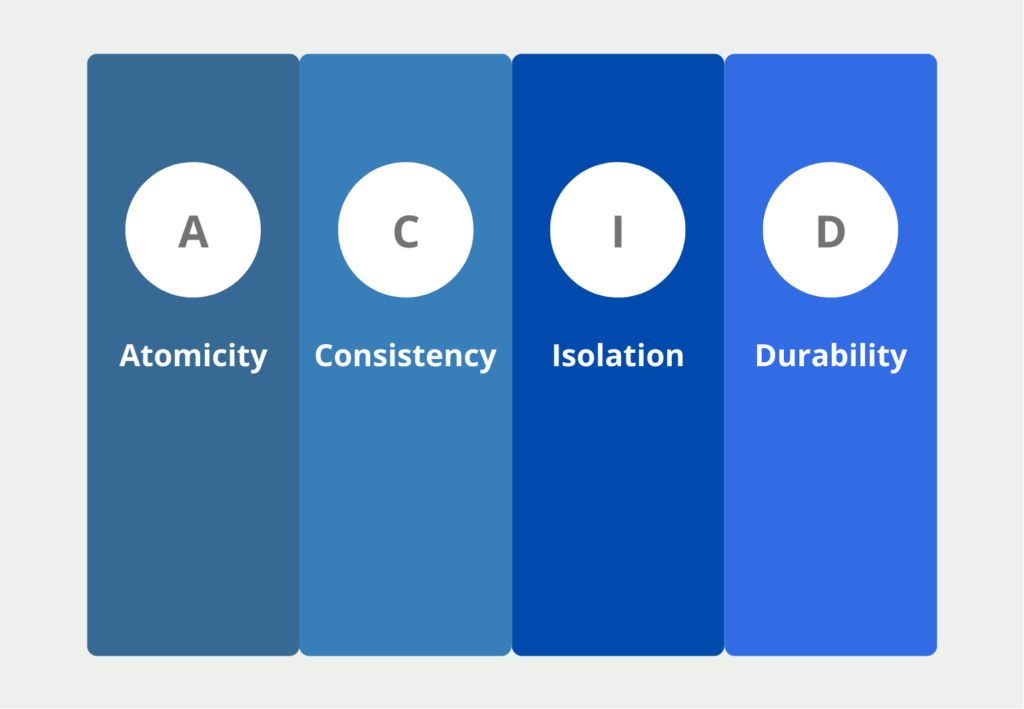
The Basic Principles on the Example
The most common example to illustrate the components of ACID are bank transfers, where money is transferred from one account to another. The goal, of course, is to ensure that all transfers are correct and that all customers have the amount of money in their account that they are entitled to.
Assume that a transfer from account A to account B takes place. Atomicity describes that transactions are either executed completely or fail completely. For our example, this means that if account A is debited with the amount of money and then there is a system failure, the money is simply credited back to account A. If this did not happen, we would have destroyed money and the system would be in a false state.
For consistency, after each transaction, it must be determined that the database is still in a consistent state, for example, that it does not contain any conflicting data. Suppose our example bank maintains a table with all accounts and the current balance amounts. In this table, the account number is a primary key so that each account number may occur only once in the database. If, after an incorrect database transaction, there may be two records for one account number, there is an inconsistency and the transaction must be reversed.
Isolation states that several transactions running in parallel must not lead to different results than if the transactions had taken place individually and one after the other. Thus, if a bank has to process 100 transfers simultaneously during peaks, it must be ensured that the balances of the affected accounts are just as high as if the transfers had taken place one after the other.
Finally, for durability, the bank must be able to guarantee that the consistent data inventory is not impaired by external influences. This includes, for example, power failures, system crashes, or software updates.
What are the Benefits of ACID?
In application, databases that comply with ACID principles offer many advantages. These include:
- ACID makes it possible for several people to work on a database without any concerns.
- Database users and developers can assume that the database is error-free and do not have to deal with troubleshooting.
- Manual debugging is no longer necessary because no errors occur.
Do NoSQL Databases fulfill the ACID Properties?
NoSQL solutions generally cannot comply with the ACID properties, although there are exceptions, such as graph databases, which comply with all the concepts. NoSQL databases are in many cases distributed across multiple devices and servers. This allows much larger amounts of data to be processed and stored simultaneously, which is a key requirement for these systems. However, this means that they do not fulfill the property of consistency.
Suppose we have implemented a NoSQL database on two physical servers, one in Germany and the other in the USA. The databases contain the account balances and transactions of German and American customers. The German accounts are stored in Germany and the American accounts are stored on the American server.
It may now happen that a German customer makes a transfer to an American account. Then both data stores are changed and are inconsistent during this processing period. For example, it may happen that we start a database query while the processing in Germany has already been completed, but the processing in the USA has not yet been completed. In this time window, the “Inconsistency window”, the data in the database is not correct and is inconsistent. This would not happen in a relational database.
What is the CAP Theorem?
The CAP theorem describes a total of three properties of databases on distributed systems, which can never all be fulfilled at the same time. CAP is an abbreviation for the terms “Consistency”, “Availability” and “Partition Tolerance”. This theorem applies primarily to databases that are distributed across multiple systems and belong to the field of NoSQL databases. For classic relational databases, on the other hand, the so-called ACID principle is applied.
In essence, CAP consists of the following three properties:
- Consistency describes the fact that the data in the database must be consistent at all times. This means that there must be no irregularities when retrieving the data, regardless of which of the nodes is addressed. In practical terms, this means, for example, that when a new data record is inserted, the data states on all nodes must take place simultaneously.
- Availability means that the distributed system always provides a response, even if individual nodes may have just failed. This is independent of which node one addresses in the system. Thus one gets also an answer if one addressed coincidentally a failed node. The system as a whole is thus continuously available.
- Partition tolerance, also known as failure tolerance, describes the ability to ensure that requests are always processed correctly and completely, even if communication failures occur during the process.
It can be shown axiomatically that these properties cannot be fulfilled simultaneously in distributed systems under any circumstances. Therefore, the CAP theorem was formed, which states that one must limit oneself to two of the properties when building distributed databases and that the third property will thus be disregarded in any case.
What are the limitations of the ACID properties?
Although the ACID properties provide important guarantees for database transactions, they also have limitations that the user should be aware of. In the following sections we look at the most important limitations.
Strict adherence to all ACID properties can contribute to the performance and scalability of the database suffering as a result. For example, the consistency of databases cannot be maintained if they are distributed across several servers. This means that databases that fulfill the ACID properties cannot be scaled horizontally or can only be scaled under very difficult conditions. Even if distributed databases meet the consistency requirements, this often results in increased network latency.
The property of isolation also leads to conflicts and locks during the write process. This makes it more difficult to enable high write speeds and at the same time, there is high competition for shared resources.
In addition, compliance with ACID properties increases the need for resources, which can make comparable databases more expensive. This is particularly significant if the database has long running transactions or high write rates. This also results in increased resource consumption and possible performance problems.
Finally, it should be checked for each application whether the implementation of ACID transactions is really necessary or whether it is possible to rely on slightly weakened properties. For example, in systems with high availability and performance, compromises can be made in terms of strict consistency in order to ensure improved performance and scalability.
In conclusion, maintaining the ACID properties comes at a high price, depending on the application. For this reason, each new database should be evaluated in detail to determine whether the properties must be fulfilled or whether compromises can be made.
How can you implement ACID in databases?
To design an ACID-compliant database, several steps need to be implemented. The following tasks should allow you to build a basic database that fulfills the ACID properties.
- Atomicity (A):
- Transaction management: Transactions must be set up so that a related sequence of SQL statements is treated as a single and indivisible unit.
- Transaction logs: Each step in a transaction should be logged in such a way that the database can be rebuilt to the state before the transaction in the event of an error.
- Rollback mechanism: Once the logs have been introduced, a mechanism can be set up that allows a transaction to be rolled back if part of the transaction runs into an error. This ensures the consistency of the database.
- Consistency (C):
- Data validation: To maintain data consistency, integrity conditions should be defined and maintained, such as referential integrity or the uniqueness of primary keys.
- Validation rules: Before inserting or updating data, certain rules must be checked to ensure that only valid data is included in the database.
- Pre-transaction checks: The defined rules must also be built into practice in such a way that they are checked before each transaction so that no violations of consistency rules can occur.
- isolation (I):
- Concurrency Control: If concurrent transactions occur, mechanisms must be defined to deal with them. This can be, for example, a lock or a time stamp to manage the concurrent transactions.
- Isolation level: There should be different isolation levels in the database that allow users to select the required isolation level.
- Handling of deadlocks: Deadlocks occur when several transactions are waiting for each other’s resources. These should be recognized and, in the best case, resolved.
- Durability (D):
- Write-ahead logging: Durability can be ensured by implementing so-called write-ahead logging (WAL). These logs change before they are applied.
- Redo logs: The committed transactions are stored in the redo logs so that they can be used to restore the database after a system failure.
- Data backup: Backups of the data should be created at regular intervals so that only part of the data is lost even after a catastrophic failure.
- Transaction completion:
- Two-Phase Commit (2PC): Using a two-phase commit protocol ensures that distributed transactions are either confirmed or canceled by all participants together.
- Transaction recovery: If a system failure occurs during a transaction, it must either be completed after the failure or undone. For this process, programs should be built that are executed when the database is restarted after a failure.
- Testing and validation:
- Compliance testing: These operations should be used to thoroughly check that the database complies with all ACID properties, not only for normal operations but also for failures or concurrent accesses.
- Validation tools: Ready-made tools can be used to make it easier to check compliance with ACID requirements.
- Monitoring and maintenance:
- Continuous monitoring: In addition to the ACID properties, the performance of the database should also be checked regularly, for example, to be able to react to a full memory at an early stage.
- Regular maintenance: Certain routine tasks must be carried out from time to time to maintain compliance with requirements and to check backups, for example,
These steps pave the way for a database that is robust and reliable and lays a good foundation to fulfill the ACID properties.
ACID vs. CAP Theorem
In short, the CAP theorem and the ACID properties differ in that CAP deals with distributed systems whereas ACID makes statements about databases. However, we want to go into more detail at this point.
Both concepts deal with the consistency of data, but they differ in what effects this has. With ACID, data consistency is meant in the area of (relational) databases. This means that the data is consistent, as soon as there is conflicting data in the system, then the database is inconsistent. This can occur, for example, due to faulty duplicates, but it does not have to. It reaches much deeper and includes the interconnections between tables and the logic behind them, such as foreign and primary keys.
In the CAP theorem, on the other hand, consistency means that the distributed system always outputs the same result for a query. This means that there may be duplicates on different servers, but they must always have the same status so that no differences can occur. Then the consistency in the CAP theorem is fulfilled.
This is what you should take with you
- ACID (Atomicity, Consistency, Isolation, Durability) is a term from database theory and describes rules and procedures for database transactions.
- Relational databases fulfill these properties and are therefore consistent at all times. NoSQL databases, on the other hand, are to a large extent not ACID compliant.
- Compliance with the principles ensures that databases have an error-free database at all times and that concurrent accesses are possible without any concerns.
- ACID differs from the so-called CAP theorem mainly in the definition of consistency and in the fact that ACID is a concept for databases and CAP is a concept of distributed systems.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of ACID
- IBM also provides a detailed explanation of the principles of ACID.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.