In the world of data analysis, missing values are a common challenge that can hinder accurate insights and decision-making. Data imputation, a technique used to fill in missing values, plays a crucial role in enhancing data quality and ensuring robust analysis.
This article explores the concept of data imputation, its importance, and various methods used to address missing data, empowering analysts to make informed choices in handling incomplete datasets.
Why are missing values a problem in Machine Learning?
Missing values in Machine Learning are a common problem that can lead to biased or inaccurate results. When data contains missing values, it can affect the ability of Machine Learning algorithms to accurately model the relationships between variables, leading to errors in predictions and reduced model performance. Here are some of the main reasons why missing values are a problem in machine learning:
- Reduced sample size: Missing values reduce the effective sample size of the dataset, leading to a decrease in statistical power and potentially biased estimates. This is because the missing data may not be random, but rather systematically related to other variables in the dataset.
- Bias in estimates: When missing values are not missing at random (MNAR), meaning the missingness depends on the unobserved value itself, estimates based on the observed data can be biased. This can occur when, for example, participants who do not want to disclose their income also do not disclose their occupation, leading to an over-representation of low-income individuals in the observed data.
- Errors in predictions: Missing values can lead to errors in predictions when they occur in the target variable or the predictors. For example, in a model that predicts housing prices, missing data on the square footage of a property could result in a significant underestimation of the property’s value.
- Incomplete datasets: Incomplete datasets can also result in incomplete or erroneous conclusions. This is particularly problematic when the missing data is not missing at random, which can lead to biased conclusions about the relationships between variables.
- Limitations in feature engineering: Feature engineering is the process of creating new features from the existing data to improve the performance of machine learning algorithms. Missing data can limit the ability to create meaningful new features, reducing the performance of the model.
In summary, missing values are a problem because they reduce sample size, bias estimates, lead to errors in predictions, and limit the ability to create new features. Machine learning practitioners need to carefully consider the nature of the missing data and use appropriate imputation techniques to address the problem and improve the accuracy of their models.
What are the different types of imputation?
There are several types of data imputation methods, each with its own assumptions, advantages, and limitations. The choice of imputation method depends on the nature of the missing data, the research question, and the characteristics of the data set. Here are some of the most commonly used data imputation methods:
- Mean imputation: This type involves replacing missing values with the mean value of the observed data for that variable. This method is simple to implement, but it can lead to biased estimates if the missing values are not missing at random or if there is a large amount of missing data.
- Hot deck imputation: This method involves replacing missing values with the value of the closest observed data point based on a set of matching variables. This method preserves the correlations between variables and avoids the problem of mean imputation, but it requires more computational resources and may be sensitive to the choice of matching variables.
- Cold deck imputation: This method works by replacing missing values with values from an external data source, such as a reference dataset. This method is useful when the external data source has similar characteristics to the target dataset, but it may not be applicable when the external data source is not available or when the characteristics of the reference dataset differ significantly from the target dataset.
- Regression imputation: Regression imputation involves using a regression model to estimate the missing values based on the observed data and other variables that are correlated with the missing values. This method can capture complex relationships between variables and can lead to less biased estimates than mean imputation, but it requires a strong understanding of the underlying relationships between variables and may be sensitive to model assumptions.
- Multiple imputations: This method involves generating several complete datasets by imputing the missing values using a model-based method. Each dataset is then analyzed separately, and the results are combined to obtain a final estimate that accounts for the uncertainty in the imputation process. This method is generally considered the gold standard for data imputation, as it provides unbiased estimates and valid standard errors. However, it can be computationally intensive and may require a larger sample size to obtain accurate estimates.
In summary, there are several different types of data imputation methods, each with its own strengths and limitations. The choice of imputation method depends on the nature of the missing data and the research question, and it is important to carefully consider the assumptions and limitations of each method when selecting an appropriate approach.
What are the advantages and disadvantages of imputation?
Data imputation is a widely used technique in data analysis and machine learning that involves replacing missing values in a dataset with estimated values. While data imputation has many advantages, it also has some disadvantages that should be taken into account when deciding whether to use it. Here are some of the key advantages and disadvantages of data imputation:
Advantages of data imputation:
- Improves statistical power: It can improve the statistical power of a dataset by increasing the effective sample size, which can lead to more accurate and reliable statistical inferences.
- Preserves relationships between variables: These methods can preserve the relationships between variables in a dataset, which can help prevent bias and improve the accuracy of predictive models.
- Can reduce bias: They can help reduce bias in estimates when the missing data is not missing at random, by incorporating information from other variables that are related to the missing values.
- Provides more complete datasets: The technique can produce more complete datasets, which can be useful for exploratory data analysis, modeling, and other applications.
Disadvantages of data imputation:
- Can introduce bias: It can introduce bias in estimates if the imputation method is not appropriate or if the missing data is not missing at random.
- Uncertainty in estimates: It introduces uncertainty in estimates, which can affect the accuracy of statistical inferences and predictive models.
- Requires assumptions: The technique requires assumptions about the distribution of the data and the nature of the missing data, which can be difficult to verify in practice.
- May not be suitable for all datasets: It may not be suitable for datasets with a large proportion of missing data or where the missing data is not ignorable.
In summary, data imputation has many advantages, including improved statistical power, preserved relationships between variables, and more complete datasets. However, it also has some disadvantages, including the potential for bias, uncertainty in estimates, the need for assumptions, and its unsuitability for certain datasets. Careful consideration of these factors is essential when deciding whether to use data imputation in a particular analysis.
What can be challenges when replacing missing values?
Data imputation is a commonly used technique in data analysis and machine learning for handling missing data. However, there are several challenges that must be overcome to ensure that the imputed data is accurate and reliable.
One of the biggest challenges is dealing with missing data patterns. Different types of missing data patterns may require different techniques, and selecting the appropriate technique can be a challenge. For example, if missing data is completely at random (MCAR), simple techniques like mean imputation or last observation carried forward (LOCF) may be appropriate. However, if missing data is missing not at random (MNAR), more complex techniques like regression imputation or multiple imputations may be necessary.
Another challenge is avoiding overfitting or underfitting models. Overfitting occurs when a model is too complex and fits the noise in the data, while underfitting occurs when a model is too simple and does not capture the true relationship between variables. This can lead to inaccurate imputation results and biased estimates. To avoid overfitting or underfitting, techniques like cross-validation can be used to evaluate the performance of different models.
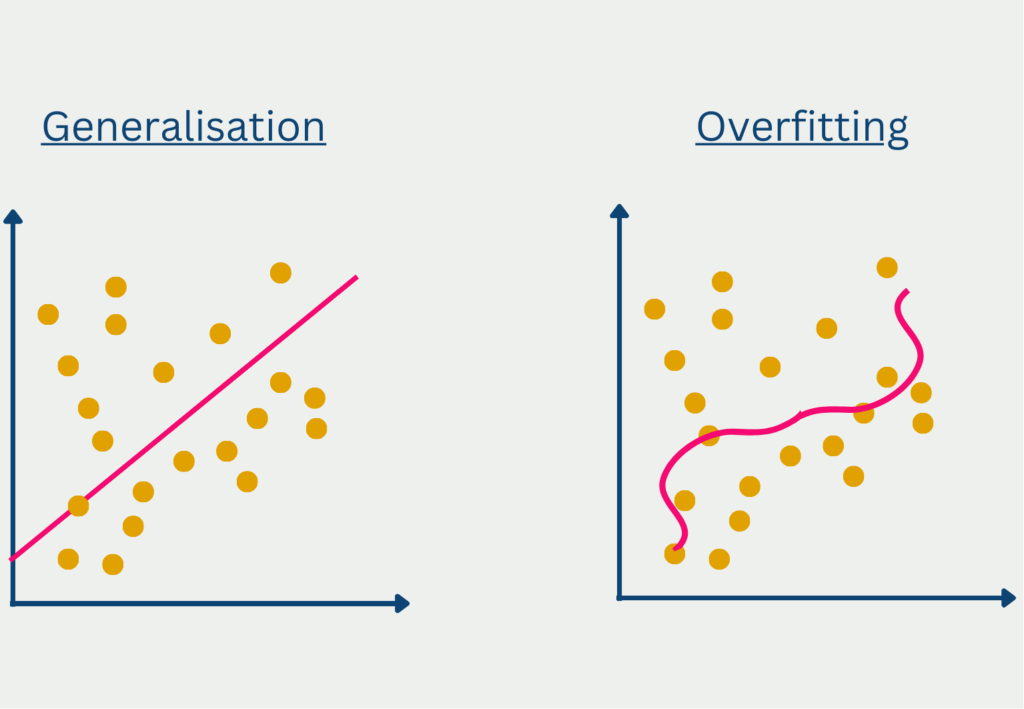
Interpreting imputed data can also be a challenge. Imputed values are estimates rather than true values, and they may introduce bias or uncertainty into downstream analyses. It is important to evaluate the quality of imputed data using metrics like mean squared error or correlation coefficients and to be transparent about the process.
Despite these challenges, data imputation has many benefits and can lead to more accurate and reliable analyses. To overcome the challenges of it, it is important to carefully consider the nature of the missing data and to use appropriate techniques that are suitable for the specific dataset and research question. Exploratory data analysis can be used to identify patterns in the missing data and techniques like cross-validation can be used to avoid overfitting or underfitting models. Ultimately, the choice of technique should be driven by careful consideration of the strengths and weaknesses of each method and its suitability for the specific dataset and research question.
This is what you should take with you
- Data imputation is a useful technique for handling missing data in datasets.
- It can improve statistical power, preserve relationships between variables, and provide more complete datasets.
- However, data imputation can also introduce bias and uncertainty in estimates.
- It requires assumptions about the distribution of the data and the nature of the missing data.
- Data imputation may not be suitable for datasets with a large proportion of missing data or where the missing data is not ignorable.
- To use data imputation effectively, it is important to carefully consider the nature of the missing data and use appropriate imputation techniques that are suitable for the specific dataset and research question.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.

What is the Bivariate Analysis?
Unlock insights with bivariate analysis. Explore types, scatterplots, correlation, and regression. Enhance your data analysis skills.
Other Articles on the Topic of Data Imputation
The Scikit-Learn documentation offers instructions on how to practically do data imputation in Python.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.