The CAP theorem describes a total of three properties of databases on distributed systems, which can never all be fulfilled at the same time. CAP is an abbreviation for the terms “Consistency”, “Availability” and “Partition Tolerance”. This theorem applies primarily to databases that are distributed across multiple systems and belong to the field of NoSQL databases. For classic relational databases, on the other hand, the so-called ACID principle is applied.
What are NoSQL databases?
NoSQL (“Not Only SQL”) describes databases that, unlike SQL, are non-relational, i.e. cannot be organized in tables, among other things. These approaches can also be distributed across different computer systems and are therefore highly scalable. NoSQL solutions are therefore very interesting for many Big Data applications.
The databases are characterized by two criteria in particular, which are very broad. Firstly, data is not stored in tables and secondly, the query language is not SQL, which is also made clear by the name “Not Only SQL”.
NoSQL solutions fall into one of four categories:
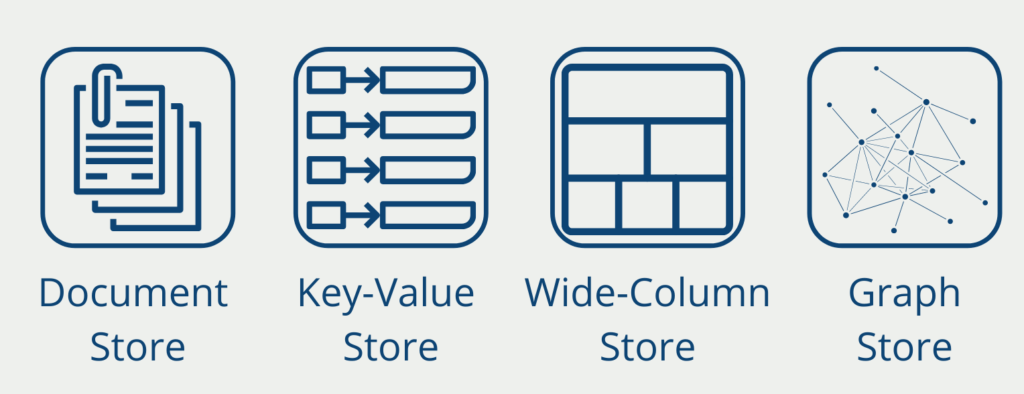
- Document stores store a variety of information within a document. For example, a document could contain all the data for one day.
- Key-value stores are very simple data structures in which each record is stored as a value with a unique key. This key can be used to retrieve specific information.
- Wide-Column Store stores a data record in a column and not as usual in a row. They have been optimized to quickly find data in large data sets.
- Graph databases store information in so-called nodes and edges. This makes it very easy to represent social networks, for example, in which people are individual nodes and the relationship between them is represented as an edge.
What do the properties of the CAP theorem mean?
At its core, CAP consists of the following three properties:
- Consistency describes the fact that the data in the database must be consistent at all times. This means that there must be no irregularities when retrieving the data, regardless of which of the nodes is addressed. In practical terms, this means, for example, that when a new data record is inserted, the data states on all nodes must take place simultaneously.
- Availability means that the distributed system always provides a response, even if individual nodes may have just failed. This is independent of which node one addresses in the system. Thus one gets also an answer if one addressed coincidentally a failed node. The system as a whole is thus continuously available.
- Partition tolerance, also known as failure tolerance, describes the ability to ensure that requests are always processed correctly and completely, even if communication failures occur during the process.
It can be shown axiomatically that these properties cannot be fulfilled simultaneously in distributed systems under any circumstances. Therefore, the CAP theorem was formed, which states that one must limit oneself to two of the properties when building distributed databases and that the third property will thus be disregarded in any case.
What does the CAP theorem mean in practice?
The CAP theorem states that when building distributed systems, one must limit oneself to two of the three properties mentioned. In practice, this means that there are a total of three possibilities for which properties are fulfilled simultaneously. We will take a closer look at these in the following.
CA – System
Relational databases are a classic example of systems that are consistent and available, but not partition-tolerant. This is because they cannot be distributed across multiple nodes, as otherwise the consistency of the data would no longer be given.
However, if you want to distribute the relational database to several systems, you will quickly run into problems with consistency. In order to be able to query the data at any time, one could also partially duplicate the data and store it on several servers. However, if something changes in the duplicated data, it is technically very difficult to change both data sets at exactly the same time. So in the short moment of the change, there is then an inconsistency.
AP – System
An AP system ensures that the database is always accessible and failure-tolerant. A well-known example of this is the so-called Domain Name Server. The websites that we address on the Internet are actually defined by IP addresses. However, since this is not so easy for humans to remember, alias names are used, which we know as “www.databasecamp.de”, for example. The translation from the IP address to the URL is stored in the Domain Name Server.
Since we access the Internet worldwide, the DNS system is also distributed on thousands of servers. If the URL is changed, it may even take several days until the change is made on all worldwide servers. During this time, the system is inconsistent, because it can happen that when one server is queried, the old URL is still output, while another server is already outputting the new URL. This is clearly an inconsistency.
CP – System
In practice, availability is a very important factor that is only reluctantly traded. Just imagine that for every third page you visit on the Internet, the domain name server would not work. This is a scenario that must be prevented. That’s why systems that need to be consistent and fail-safe are rare in practice.
For individual applications, however, these properties are indispensable. In the financial and banking sector, for example, consistency and fail-safety are of immense importance so that no erroneous transfers take place and the credit balances are also always correct. Availability plays a rather subordinate role here because, after all, you can simply repeat the transaction again if the system was not available at the first attempt.
What is ACID?
In the field of Data Science, the acronyms CAP Theorem and ACID are often confused, mainly because both deal with consistency. However, before we can turn to the distinction, we should first take a closer look at ACID.
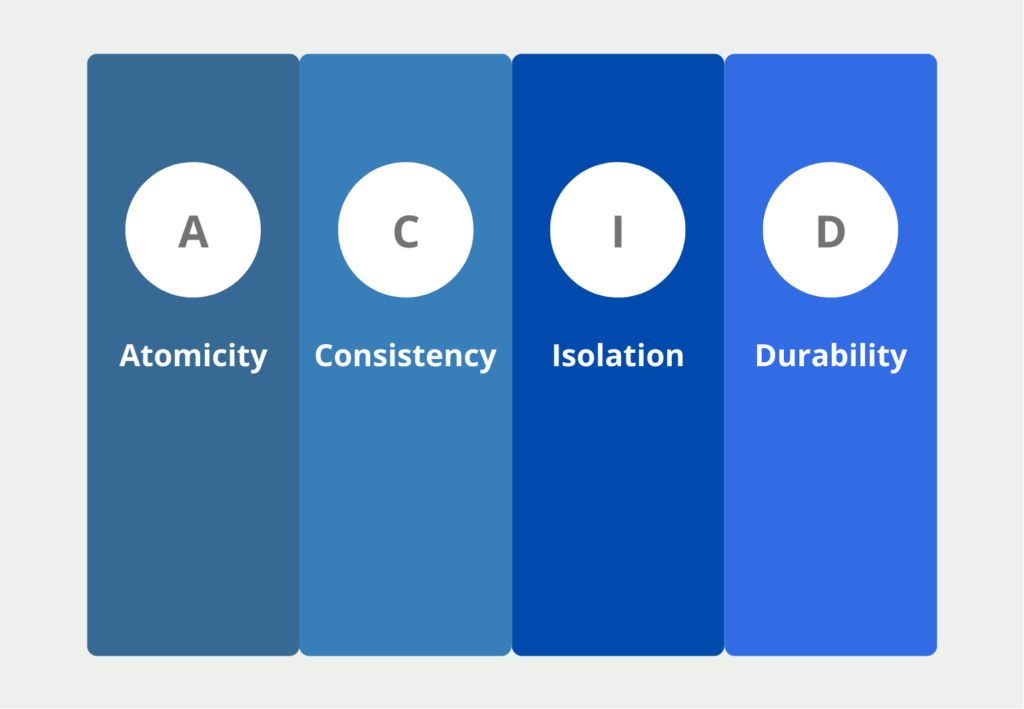
Classical relational databases fulfill the four ACID properties. These state that the most important requirement for a database is to maintain the truthfulness and meaningfulness of the data. In many cases, data stores are seen as a “single point of truth”, thus it would be fatal if erroneous information is stored and passed on. The four properties include the following points:
- Atomicity (A): Data transactions, e.g. the entry of a new data record or the deletion of an old one, should either be executed completely or not at all. The transaction is only visible to other users when it is completely executed.
- Consistency (C): This property is satisfied when each data transaction moves the database from a consistent state to a consistent state.
- Isolation (I): When multiple transactions occur simultaneously, the final state must be the same as if the transactions occurred separately. That is, the database should pass the stress test. In other words, it should not result in incorrect database transactions due to overload.
- Durability (D): The data within the database must only change as a result of a transaction and must not be changeable by external influences. For example, a software update must not inadvertently cause data to change or possibly be deleted.
CAP Theorem vs. ACID
In short, the CAP theorem and the ACID properties differ in that CAP deals with distributed systems, whereas ACID makes statements about databases. However, we want to go into more detail at this point.
Both concepts deal with the consistency of data, but they differ in what effects this has. In ACID, data consistency is meant in the area of (relational) databases. This means that the data is consistent, but as soon as there is contradictory data in the system, the database is inconsistent. This can occur, for example, due to faulty duplicates, but it does not have to. It goes much deeper and includes the interconnections between tables and the logic behind them, such as foreign and primary keys.
In the CAP theorem, on the other hand, consistency means that the distributed system always outputs the same result for a query. This means that there may be duplicates on different servers, but they must always have the same status so that no differences can occur. Then the consistency in the CAP theorem is fulfilled.
This is what you should take with you
- The CAP theorem describes that a distributed system can never fulfill the three attributes of consistency, availability, and failure tolerance simultaneously. Only two of the named attributes can be present in a system.
- The CAP theorem is particularly interesting for NoSQL databases, as these are very often stored in a distributed manner on multiple servers.
- The CAP theorem should not be confused with the ACID properties of relational databases. These differ mainly in the different definitions of consistency.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.

What is the Bivariate Analysis?
Unlock insights with bivariate analysis. Explore types, scatterplots, correlation, and regression. Enhance your data analysis skills.
Other Articles on the Topic of CAP Theorem
IBM has written a detailed article on the CAP Theorem, available here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.