Die Abkürzung ACID (Atomicity, Consistency, Isolation, Durability) ist ein Begriff aus der Datenbanktheorie und beschreibt Regeln und Vorgehensweisen bei Datenbanktransaktionen. Wenn die Vorgaben von ACID eingehalten werden, sind die Daten in einem System verlässlich und konsistent. Im Laufe des Artikels beleuchten wir neben ACID auch die Eigenschaften des CAP Theorems, die sich nicht nur mit Datenbanken, sondern mit verteilten Systemen beschäftigen. Außerdem beleuchten wir die Vorteile, die sich ergeben, wenn die ACID Eigenschaften erfüllt sind.
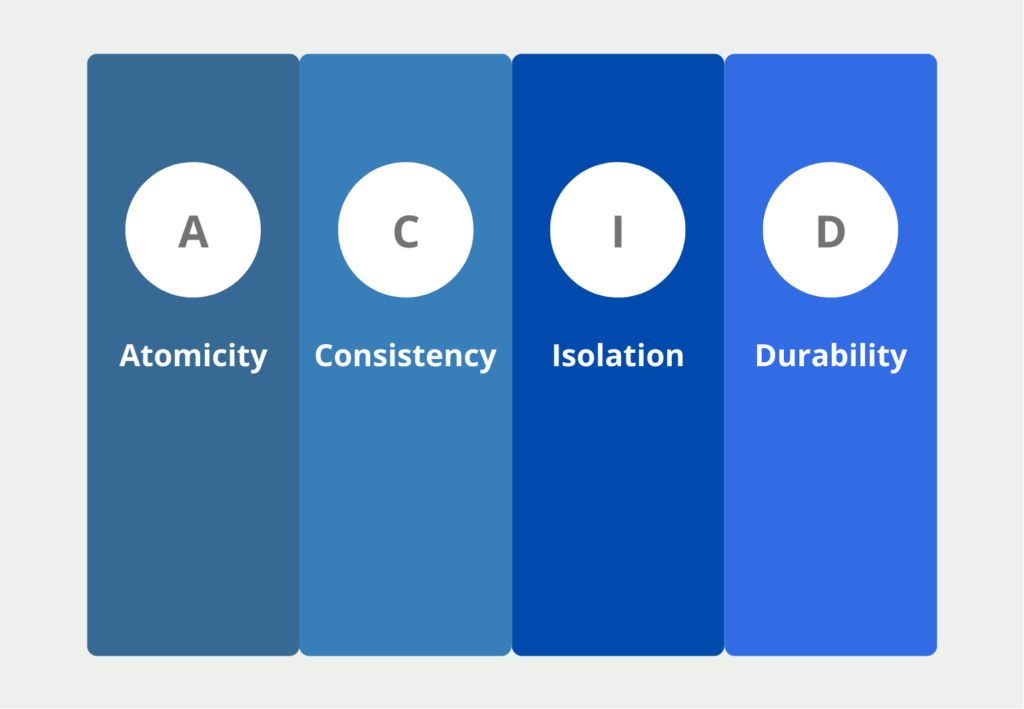
Wie lauten die A-C-I-D Grundprinzipien?
Klassische relationale Datenbanken erfüllen die vier ACID Eigenschaften. Diese besagen, dass die wichtigste Anforderung an eine Datenbank ist, den Wahrheitsgehalt und die Aussagekraft der Daten zu erhalten. In vielen Fällen werden Datenspeicher als „Single Point of Truth“ gesehen, somit wäre es fatal, wenn fehlerhafte Informationen gespeichert und weitergegeben werden. Die vier Eigenschaften umfassen die folgenden Punkte:
- Atomicity (A): Datentransaktionen, bspw. die Eintragung eines neuen Datensatzes oder das Löschen eines alten, sollen entweder ganz oder gar nicht ausgeführt werden. Für andere User ist die Transaktion erst sichtbar, wenn sie vollständig ausgeführt ist.
- Consistency (C): Diese Eigenschaft ist erfüllt, wenn jede Datentransaktion die Datenbank von einem konsistenten in einen konsistenten Zustand überführt.
- Isolation (I): Wenn mehrere Transaktionen gleichzeitig stattfinden, muss der Endzustand derselbe sein, als wenn die Transaktionen getrennt voneinander stattfinden würden. Das heißt die Datenbank sollte den Stresstest bestehen. Also nicht durch Überlastung zu falschen Datenbanktransaktionen kommen.
- Durability (D): Die Daten innerhalb der Datenbank dürfen sich nur durch eine Transaktion ändern und nicht durch äußere Einflüsse veränderbar sein. Ein Softwareupdate darf beispielsweise nicht versehentlich dazu führen, dass sich Daten ändern oder womöglich gelöscht werden.
Die Grundprinzipien am Beispiel
Das gängigste Beispiel, um die Komponenten von ACID zu veranschaulichen sind Banküberweisungen, bei denen Geld von einem Konto zum anderen transferiert wird. Das Ziel ist es natürlich, dass alle Überweisungen korrekt ablaufen und alle Kunden den Geldbetrag auf dem Konto haben, der ihnen zusteht.
Angenommen es findet eine Überweisung von Konto A auf Konto B statt. Die Atomarität beschreibt, dass Transaktionen entweder komplett ausgeführt werden oder komplett fehlschlagen. Für unser Beispiel bedeutet das, dass wenn Konto A mit dem Geldbetrag belastet wird und es dann zu einem Systemfehler kommt, das Geld dem Konto A einfach wieder gutgeschrieben wird. Würde das nicht passieren, hätten wir Geld vernichtet und das System wäre in einem falschen Zustand.
Der Konsistenz zur Folge muss nach jeder Transaktion festgestellt werden, dass die Datenbank weiterhin in einem konsistenten Zustand ist, also beispielsweise keine widersprüchlichen Daten enthält. Angenommen unsere Beispielbank führt eine Tabelle mit allen Konten und den aktuellen Guthabenbeträgen. In dieser Tabelle ist die Kontonummer ein Primärschlüssel, sodass jede Kontonummer nur einmal in der Datenbank vorkommen darf. Wenn nach einer fehlerhaften Datenbanktransaktion möglicherweise zwei Datensätze zu einer Kontonummer vorliegen, so liegt eine Inkonsistenz vor und die Transaktion muss rückgängig gemacht werden.
Die Isolation besagt, dass mehrere parallel laufende Transaktionen nicht zu anderen Ergebnissen führen darf, als wenn die Transaktionen einzeln und hintereinander stattfinden würden. Wenn also eine Bank während Peaks 100 Überweisungen gleichzeitig verarbeiten muss, dann muss sichergestellt sein, dass die Guthaben der betroffenen Konten genauso hoch sind, als wenn die Überweisungen nacheinander stattgefunden hätten.
Abschließend muss die Bank für die Dauerhaftigkeit der Daten gewährleisten können, dass der konsistente Datenbestand nicht durch äußere Einflüsse beeinträchtigt wird. Dazu gehören beispielsweise Stromausfälle, Systemabstürze oder Softwareupdates.
Welche Vorteile entstehen durch ACID?
In der Anwendung bieten Datenbanken, welche die ACID Prinzipien erfüllen viele Vorteile. Dazu zählen unter anderem:
- Durch ACID ist die Arbeit von mehreren Personen an einer Datenbank unbedenklich möglich.
- Die Nutzer und Entwickler von Datenbanken können von einem fehlerfreien Datenbestand ausgehen und müssen sich nicht mit der Fehlersuche beschäftigen.
- Die manuelle Fehlersuche ist nicht mehr notwendig, da keine Fehler auftreten.
Erfüllen NoSQL Datenbanken die ACID Eigenschaften?
NoSQL Lösungen können generell die ACID Eigenschaften nicht einhalten, obwohl es Ausnahmen gibt, wie beispielsweise die Graphdatenbanken, welche alle Konzepte erfüllen. NoSQL Datenbanken werden in vielen Fällen über mehrere Geräte und Server verteilt. Dadurch können deutlich größere Datenmengen gleichzeitig verarbeitet und gespeichert werden, was eine Hauptanforderung an diese Systeme ist. Jedoch erfüllen sie dadurch die Eigenschaft der Konsistenz nicht.
Angenommen wir haben eine NoSQL Datenbank auf zwei physischen Servern realisiert, von denen einer in Deutschland und der andere in den USA steht. Die Datenbanken enthalten die Kontostände und -transaktionen von deutschen und amerikanischen Kunden. Dabei sind die deutschen Konten in Deutschland und die amerikanischen Konten auf dem amerikanischen Server gespeichert.
Es kann nun zu Fall kommen, dass ein deutscher Kunde eine Überweisung auf ein amerikanisches Konto vornimmt. Dann werden beide Datenspeicher verändert und sind in diesem Bearbeitungszeitraum inkonsistent. Es kann beispielsweise zu dem Fall kommen, dass wir eine Datenbankabfrage starten während die Verarbeitung in Deutschland bereits abgeschlossen ist, aber die in den USA noch nicht. In diesem Zeitfenster, dem “Inconsistency Window”, stimmen die Daten in der Datenbank nicht und sind inkonsistent. So etwas würde in einer relationalen Datenbank nicht vorkommen.
Was ist das CAP Theorem?
Das CAP Theorem beschreibt insgesamt drei Eigenschaften von Datenbanken auf verteilten Systemen, die nie alle gleichzeitig erfüllt sein können. CAP steht dabei als Abkürzung für die englischen Begriffe “Consistency”, “Availability” und “Partition Tolerance” oder auf deutsch “Konsistenz”, “Verfügbarkeit” und “Partitionstoleranz”. Dieses Theorem gilt vor allem für Datenbanken, die auf mehreren Systemen verteilt sind und in den Bereich der NoSQL-Datenbanken zählen. Für klassische relationale Datenbanken hingegen findet das sogenannte ACID Prinzip Anwendung.
Im Kern besteht CAP aus den folgenden drei Eigenschaften:
- Die Konsistenz beschreibt den Umstand, dass die Daten in der Datenbank zu jedem Zeitpunkt konsistent sein müssen. Das bedeutet, dass es zu keinerlei Unregelmäßigkeiten beim Abruf der Daten kommen darf, egal welcher der Knoten angesprochen wird. Praktisch bedeutet dies beispielsweise, dass beim Einfügen eines neuen Datensatzes die Datenstände auf allen Knoten gleichzeitig stattfinden muss.
- Verfügbarkeit bedeutet, dass das verteilte System immer eine Rückantwort liefert, auch wenn möglicherweise gerade einzelne Knoten ausgefallen sind. Dies ist unabhängig davon, welchen Knoten man im System anspricht. Somit bekommt man auch eine Antwort, wenn man zufülligerweise einen ausgefallenen Knoten angesprochen hat. Das System als ganzes ist somit durchgehend verfügbar.
- Die Partitionstoleranz, oder auch Ausfalltoleranz genannt, beschreibt die Fähigkeit, dass Anfragen stets richtig und komplett bearbeitet werden, selbst wenn es während des Prozesses zu Kommunikationsausfällen gekommen ist.
Es lässt sich axiomatisch zeigen, dass diese Eigenschaften in verteilten Systemen unter keinen Umständen gleichzeitig erfüllt sein können. Deshalb bildete sich das CAP Theorem, welches besagt, dass man sich beim Aufbau von verteilten Datenbanken auf zwei der Eigenschaften beschränken muss und die dritte Eigenschaft damit auf jeden Fall missachtet werden wird.
Wo liegen die Grenzen der ACID Eigenschaften?
Obwohl die ACID Eigenschaften wichtige Garantien für Datenbanktransaktionen liefern, haben sie auch Grenzen, denen sich der Anwender bewusst sein sollte. In den folgenden Abschnitten beschäftigen wir uns mit den wichtigsten Einschränkungen.
Die strikte Einhaltung aller ACID-Eigenschaften kann dazu beitragen, dass die Leistungsfähigkeit und die Skalierbarkeit der Datenbank darunter leidet. Beispielsweise kann die Konsistenz bei Datenbanken nicht eingehalten werden, wenn diese über mehrere Server verteilt sind. Dadurch lassen sich Datenbanken, die die ACID Eigenschaften erfüllen nicht horizontal skalieren bzw. nur unter stark erschwerten Bedingungen. Selbst wenn verteilte Datenbanken die Konsistenz erfüllen hat dies in vielen Fällen eine erhöhte Netzwerklatenz zur Folge.
Die Eigenschaft der Isolation führt darüber hinaus zu Konflikten und Sperren beim Schreibvorgang. Dadurch wird es schwieriger hohe Schreibgeschwindigkeiten zu ermöglichen und es gibt gleichzeitig einen hohen Wettbewerb um gemeinsam genutzte Ressourcen.
Zusätzlich erhöht die Einhaltung der ACID Eigenschaften den Bedarf an Ressourcen, wodurch vergleichbare Datenbanken teurer werden können. Dies fällt besonders dann mehr ins Gewicht, wenn die Datenbank lange laufende Transaktionen hat oder hohe Schreibraten aufweist. Auch hieraus ergeben sich ein erhöhter Ressourcenverbrauch und möglicherweise Leistungsprobleme.
Schließlich sollte bei jeder Anwendung erstmal geprüft werden, ob die Umsetzung von ACID Transaktionen wirklich von Nöten ist, oder man nicht auf leicht abgeschwächte Eigenschaften setzen kann. Dadurch kann beispielsweise bei Systemen mit einer hohen Verfügbarkeit und Leistung Kompromisse bei der strikten Konsistenz eingegangen werden, um eine verbesserte Leistung und Skalierbarkeit zu gewährleisten.
Abschließend wird deutlich, dass die EInhaltung der ACID-Eigenschaften abhängig von der Anwendung einen hohen Preis fordert. Deshalb sollte bei jeder neuen Datenbank eingehend evaluiert werden, ob die Eigenschaften erfüllt sein müssen oder ob Kompromisse eingegangen werden können.
Wie können die ACID Eigenschaften in Datenbanken implementiert werden?
Um eine Datenbank ACID-konform gestalten zu können, wird eine Reihe von Schritten erforderlich, die umgesetzt werden müssen. Mit den folgenden Aufgaben sollte eine grundlegende Datenbank aufgebaut werden können, die die ACID Eigenschaften erfüllt.
1. Atomicity (A):
- Transaktionsmanagement: Die Transaktionen müssen so aufgesetzt werden, dass eine zusammenhänge Abfolge von SQL-Anweisungen als eine einzelne und unteilbare Einheit behandelt wird.
- Transaktionsprotokolle: Jeder Schritt in einer Transaktion sollte so protokolliert werden, dass die Datenbank im Falle eines Fehlers auf den Stand vor der Transaktion zurückgebaut werden kann.
- Rückrollmechanismus: Nachdem die Protokolle eingeführt wurden, kann ein Mechanismus aufgesetzt werden, der es ermöglicht, eine Transaktion rückgängig zu machen, wenn ein Teil der Transaktion auf einen Fehler läuft. Dadurch wird die Konsistenz der Datenbank sichergestellt.
2. Consistency (C):
- Datenvalidierung: Damit die Datenkonsistenz erhalten bleibt sollten Integritätsbedingungen definiert und aufrechterhalten werden, wie zum Beispiel die referentielle Integrität oder die Eindeutigkeit von Primärschlüsseln.
- Validierungsregeln: Vor dem Einfügen oder Aktualisieren von Daten müssen gewisse Regeln geprüft werden, die sicherstellen, dass nur gültige Daten in die Datenbank aufgenommen werden.
- Vor-Transaktionsprüfungen: Die definierten Regeln müssen auch in der Praxis so eingebaut werden, dass sie vor jeder Transaktion geprüft werden, damit es zu keinen Verstößen gegen Konsistenzregeln kommen kann.
3. Isolation (I):
- Concurrency Control: Wenn es zu gleichzeitigen Transaktionen kommt, müssen Mechanismen definiert werden, die damit umgehen. Das kann zum Beispiel eine Sperre sein oder ein Zeitstempel um die gleichzeitigen Transaktionen zu verwalten.
- Isolationslevel: In der Datenbank sollte es verschiedene Isolationslevel geben, die den Nutzern die Möglichkeit bieten das benötigte Isolationsniveau auszuwählen.
- Behandlung von Deadlocks: Deadlocks treten auf, wenn mehrere Transaktionen gegenseitig auf Ressourcen warten. Diese sollten erkannt und im besten Fall auch gelöst werden.
4. Durability (D):
- Write-Ahead-Logging: Die Durability kann sichergestellt werden, indem das sogenannte Write-Ahead-Logging (WAL) umgesetzt wird. Dadurch werden Änderungen protokolliert, bevor sie angewendet werden.
- Redo-Protokolle: In den Redo-Protokollen werden die committed Transaktionen abgelegt, damit sie nach einem Systemausfall genutzt werden können, um die Datenbank wiederherzustellen.
- Datensicherung: In regelmäßigen Abständen sollten Backups der Daten erstellt werden, damit auch nach einem katastrophalen Ausfall nur ein Teil der Daten verloren gehen.
5. Transaktionsabschluss:
- Two-Phase Commit (2PC): Mithile eines Zwei-Phasen-Commit Protokolls wird sichergestellt, dass verteilte Transaktionen entweder von allen Teilnehmern gemeinsam bestätigt oder abgebrochen werden.
- Transaktionswiederherstellung: Falls es während einer Transaktion zu einem Systemausfall kommt, muss diese entweder nach dem Ausfall abgeschlossen oder rückgängig gemacht werden. Für diesen Prozess sollten Programme gebaut werden, die ausgeführt werden, wenn die Datenbank nach einem Ausfall neu gestartet wird.
6. Prüfung und Validierung:
- Compliance-Tests: Mithilfe dieser Operationen sollte gründlich geprüft werden, ob die Datenbank alle ACID-Eigenschaften einhält, nicht nur bei normalen Operationen, sondern auch bei Fehlern oder gleichzeitigen Zugriffen.
- Validierungstools: Mithilfe von fertigen Tools lässt sich die Einhaltung der ACID-Anforderungen einfacher überprüfen.
7. Überwachung und Wartung:
- Kontinuierliche Überwachung: Neben den ACID-Eigenschaften sollte auch die Leistungsfähigkeit der Datenbank regelmäßig überprüft werden, um zum Beispiel frühzeitig auf einen vollen Speicher reagieren zu können.
- Regelmäßige Wartung: Von Zeit zu Zeit müssen gewissen Routineaufgaben durchgeführt werden, um die Einhaltung der Anforderungen aufrechtzuerhalten und beispielsweise Backups zu überprüfen,
Diese Schritte ebnen den Weg für eine Datenbank, die robust und zuverlässig ist, und ein gutes Fundament legt, um die ACID-Eigenschaften erfüllen zu können.
CAP Theorem vs. ACID
Kurz gesprochen unterscheiden sich das CAP Theorem und die ACID Eigenschaften darin, dass sich CAP mit verteilten Systemen beschäftigt wohingegen ACID Aussagen über Datenbanken trifft. Wir wollen an dieser Stelle jedoch noch mehr ins Detail gehen.
Beide Konzepte beschäftigen sich mit der Konsistenz von Daten, jedoch unterscheiden sie sich darin, welche Auswirkungen dies hat. Bei ACID ist die Datenkonsistenz im Bereich von (relationalen) Datenbanken gemeint. Das bedeutet, dass die Daten konsistent sind, sobald im System widersprüchliche Daten vorhanden sind, dann ist die Datenbank inkonsistent. Das kann beispielsweise durch fehlerhafte Dupletten vorkommen, muss es jedoch nicht. Es greift dabei viel tiefer und inkludiert darin auch die Verflechtungen zwischen Tabellen und die Logik dahinter, wie beispielsweise Fremd- und Primärschlüssel.
Im CAP Theorem hingegen bedeutet die Konsistenz, dass das verteilte System bei einer Abfrage immer dasselbe Ergebnis ausgibt. Das bedeutet, dass es Dupletten geben darf auf verschiedenen Servern, diese müssen jedoch immer denselben Stand haben, damit es zu keinen Differenzen kommen kann. Dann ist die Konsistenz im CAP Theorem erfüllt.
Das solltest Du mitnehmen
- ACID (Atomicity, Consistency, Isolation, Durability) ist ein Begriff aus der Datenbanktheorie und beschreibt Regeln und Vorgehensweisen bei Datenbanktransaktionen.
- Relationale Datenbanken erfüllen diese Eigenschaften und sind dadurch zu jeder Zeit konsistent. NoSQL Datenbanken hingegen sind zu großen Teilen nicht ACID konform.
- Durch die Einhaltung der Prinzipien ist sichergestellt, dass Datenbanken zu allen Zeitpunkten einen fehlerfreien Datenbestand haben und gleichzeitige Zugriffe unbedenklich möglich sind.
- ACID unterscheidet sich vom sogenannten CAP Theorem vor allem in der Definition der Konsistenz und darin, dass es sich bei ACID um ein Konzept für Datenbanken handelt und bei CAP um ein Konzept von verteilten Systemen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema ACID
- IBM bietet auch eine ausführliche Erklärung zu den Prinzipien von ACID.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.