Apache Airflow is an open-source platform for managing workflows in data processing and DevOps automation. With the help of so-called directed, acyclic graphs, workflows can not only be visualized but also optimized.
What is Apache Airflow?
Apache Airflow was originally developed by Airbnb when they experienced rapid growth during their early days and were overwhelmed with the mass of data. By hiring Data Engineers and Data Scientists, they were able to get a handle on the data growth. A workflow management tool was then developed to coordinate the staff and their activities.
This was included by the Apache Foundation in 2016 and has since been available as Apache Airflow open-source. The program was originally written in Python and has a clear front end with which users can monitor and coordinate individual data jobs.
How does Apache Airflow work?
Apache Airflow can be used to programmatically start, schedule and monitor data pipeline flows, or ETL flows. To better understand how it works, let’s take a closer look at the components involved in this process:
Directed Acyclic Graph (DAG)
Each workflow is represented in Airflow as a directed, acyclic graph. Directed means that the data only run in one direction and that there is a fixed, temporal specification of the processing. The graph is acyclic if no loops are allowed, i.e. no tasks are run through more than once. Within the graph, the tasks are defined, i.e. small work packages that define which operations are to be executed. These can be, for example, extractions from a data source or the preparation of data.
Three types of tasks are distinguished in Airflow:
- Operators: These are already predefined tasks in Airflow that can be used via drag-and-drop and can be easily assembled into a functioning DAG.
- Sensors: Sensor tasks also belong to the operators but do not perform any task themselves, but only wait for an external event and start a trigger as soon as the event is started.
- TaskFlow: With this, you can write your own functions in Python that go beyond the functionalities of the operators if necessary.
Scheduler
If a workflow has been defined, it is passed to the scheduler. The scheduler monitors all transferred tasks and starts the DAG as soon as the specified dependency occurs. Time specifications are mostly used as triggers, which can either be a concrete date or can be relatively linked to other workflows and start as soon as other workflows are finished.
Executor
The scheduler calls the executor as soon as the trigger for a workflow occurs. This means that no separate executor process needs to be called, because it already runs automatically in the scheduler. If desired, own executors can be written and stored in the configuration file.
In addition, two different types of executors are distinguished. By default, the scheduler uses a local executor that executes the tasks locally on a single machine. If this computing power is not sufficient, so-called remote executors can also be used, which can be distributed to several workers.
User Interface
These described processes in Apache Airflow can either be defined and called in code or operated via a user interface without code. When Airflow is started, a web server is also automatically set up through which this frontend can be accessed.

In the front end, all workflows and their statuses can be recorded, started, or ended at a glance. In addition, individual workflows can also be examined in detail, for example, to identify potential problems.
What Principles does the Apache Airflow Architecture follow?
The components described have a total of four principles that dictate how they work together.
- Dynamic: The workflows in Apache Airflow can be dynamically changed and also started using Python.
- Extensible: The various components, such as scheduler or executor, can be individualized as desired and easily extended for special applications.
- Elegant: Workflows are kept as lean as possible and existing pipelines can be easily multiplied by changing parameters.
- Scalable: Although the base installation only runs locally, the architecture of Apache Airflow can also be distributed across multiple workers, making it very easy to scale horizontally.
In which Applications can you use Airflow?
Apache Airflow is already used in many large companies, such as PayPal, Adobe, and Google, where it serves as a monitoring tool for data pipelines. The most common use cases include so-called ETL (Extract-Transform-Load) pipelines, in which data is extracted from various data sources, brought into a uniform schema, and then finally stored in another database, for example, a data warehouse.
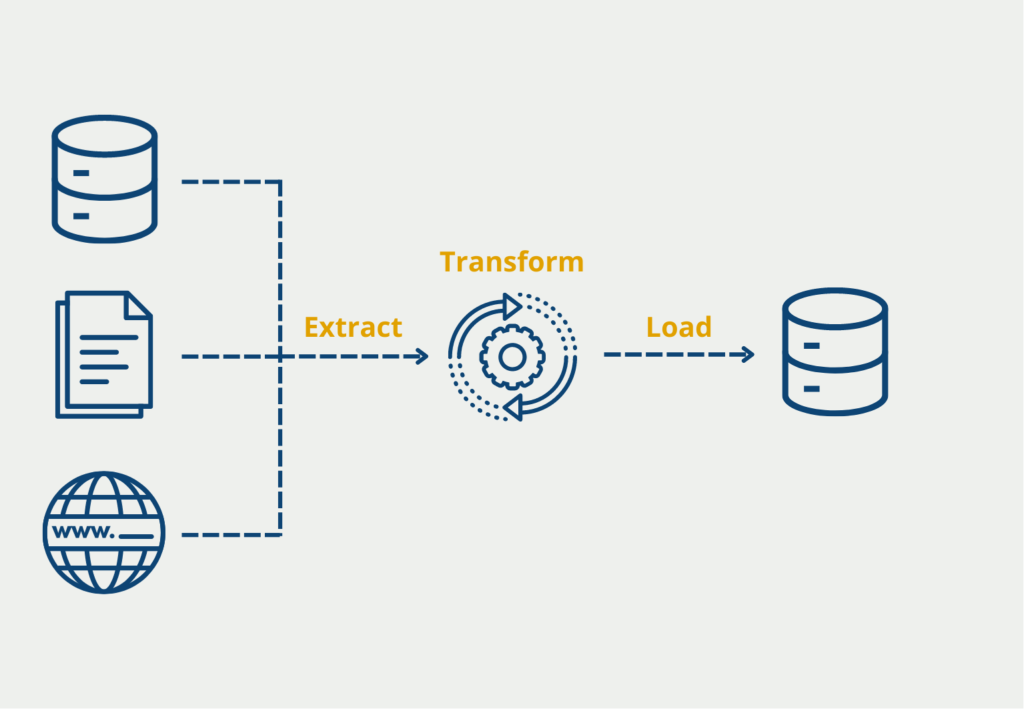
Apache Airflow is popular for these applications because it offers the ability to easily manage even a complex collection of such pipelines. This includes, for example, the option to link the start of a pipeline to the completion of previous workflows.
What are the Advantages of using Airflow?
The Apache Airflow program can be used for a wide variety of applications. It has become a standard in data processing in recent years also due to the following advantages:
- Flexibility: The program is based on Python and therefore all functionalities that can be implemented using Python can be integrated into Airflow. This allows Airflow to be customized for a wide variety of applications and circumstances.
- Extensibility: Over the years, a number of plug-ins have already been developed that can be used without further ado and can, for example, connect to cloud providers such as Amazon Web Services or Microsoft Azure.
- Simplification of complex Workflows: Visualization in a user interface makes it easy to keep track of running pipelines and also reduces complexity.
- Free of charge use: Due to its inclusion in the Apache Foundation, Airflow is now available as an open-source program and can therefore be used free of charge. In addition, the program can be easily extended.
- Community: The distribution of Airflow is relatively large, which means that there are a lot of users who share problems and their solutions with each other and help each other. This level of knowledge is publicly available and can be tapped and used in forums or similar.
- Unlimited Possibilities: Although the program was originally intended for data processing pipelines, it can be extended indefinitely through the Python interface and can thus also be used for Machine Learning pipelines, for example.
How to install Airflow in Python?
Apache Airflow can be installed as usual using “pip” in Python. In addition to the normal pip command, a so-called constraint file must be defined. This is needed because Airflow is not only a library but also an application. In this file, the dependencies to other modules are defined, so that Airflow can work properly.
!pip install "apache-airflow[celery]==2.3.4" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.3.4/constraints-3.7.txt"In some cases, the pure pip command also works for installation, but without the constraint file, there may be occasional problems. Therefore, it is easier to specify the constraint file from the beginning.
How does the integration of Apache Airflow work?
The integration and ecosystem of Apache Airflow are some of its key strengths. Apache Airflow is designed to be extensible, which means that it can be easily integrated with a wide range of data sources, destinations, and third-party tools. This allows data engineers and data scientists to build complex workflows that can seamlessly interact with their existing data infrastructure.
Some of the key integrations and ecosystem components of Apache Airflow include:
- Operators and hooks: Apache Airflow provides a range of built-in operators and hooks that can be used to interact with various data sources and destinations. These include operators and hooks for working with databases, cloud services, messaging systems, and more. Operators and hooks can also be extended with custom code to support additional data sources or destinations.
- Third-party plugins: Apache Airflow has a large and active community that has developed a wide range of third-party plugins. These plugins can be used to extend the functionality of Apache Airflow and provide additional integrations with popular data sources and destinations. Examples of popular third-party plugins include integrations with AWS services, Kubernetes, and more.
- Sensors: Apache Airflow provides sensors that can be used to wait for specific events to occur before proceeding with a workflow. For example, a sensor could be used to wait for a file to appear in a particular directory, or for a message to be received on a messaging queue.
- Executors: Apache Airflow provides a range of executors that can be used to run tasks within a workflow. These include local executors, which run tasks on the same machine as the Apache Airflow scheduler and distributed executors, which run tasks on remote machines.
- Monitoring and visualization: Apache Airflow provides a range of monitoring and visualization tools to help users track the progress of their workflows. These tools include a web interface that shows the status of running workflows, as well as metrics and logging data that can be used to diagnose issues.
Overall, the integration and ecosystem of Apache Airflow make it a powerful tool for building complex data workflows. With its wide range of integrations and extensibility, Apache Airflow can be customized to fit almost any data infrastructure. The active community and ecosystem of plugins and integrations also mean that users can take advantage of the latest technologies and best practices in data engineering and data science.
This is what you should take with you
- Apache Airflow is an open-source platform for managing workflows in data processing and DevOps automation.
- It allows data pipelines to be created as directed, acyclic graphs and easily started at specific times using the scheduler.
- Apache Airflow can be installed in Python and the individual components can be easily extended with your own functions.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Apache Airflow

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.