A data warehouse is a central data store in a company or organization that collects relational data from various sources. The information is transferred from different transactional systems or other relational databases to the data warehouse, where it is available to analysts and decision-makers.
What is the function of a Data Warehouse?
The data warehouse is used in many areas of the business environment. The database is used throughout the company to make data-driven decisions or to examine processes. Since the central data warehouse draws information from many different systems, it is seen as a single point of truth. This is to ensure that everyone in the company is talking about the same data and that decisions are based on this information.
Across departments, the data warehouse can be used for the following tasks:
- Cost and resource analysis
- Analysis of internal processes (e.g. production, hiring, etc.)
- Business Intelligence
- Calculation and provision of company-wide key performance indicators
- The data source for analyses or data mining
- Standardization of company-wide data into a fixed schema
What properties does it have?
When creating central data warehouses, one can be guided by certain characteristics that should help to better narrow down the structure and the necessary data of the warehouse.
Topic Orientation
A data warehouse contains information on a specific topic and not on individual business transactions. These topics can be, for example, sales, purchasing, or marketing.
The warehouse aims to support decision-making with the help of business intelligence and targeted KPIs. This interpretation is also supported by the fact that information that is not relevant to decision-making or used for analysis does not end up in this central database in the first place.
Integration
The warehouse integrates data from a wide variety of systems and sources. Therefore, a common schema must be created for the information to be uniform and comparable. Otherwise, central analysis and KPI creation are not possible.
Time Period Reference
The data warehouse stores data from a specific time period and is therefore related to the past. Furthermore, the data is usually transmitted in aggregated form, for example at the daily level, so that the volume of data remains limited. Thus, the granularity may not be fine enough, as one is used to the operational systems.
On the other hand, the operational systems are time-based, as they output the current information accumulating. At the same time, the information can be viewed in great detail.
Non-Volatility
Another important feature of central warehouses is the non-volatility of the data. In operational systems, information is usually only stored temporarily for a short period of time, and as soon as new data is added, old data is overwritten. In a data warehouse, on the other hand, data is stored permanently and old data persists even when newer data is added.
What are the Advantages of a Data Warehouse?
By establishing a central data repository, more people can access information more easily and use it in the decision-making process. As a result, more rational decisions are made that do not depend solely on the opinions of individuals.
Furthermore, it offers the possibility of combining information from different sources and thus creating new ways of looking at things. Previously, this was not possible due to the physical separation of the systems. It may be interesting for a company to combine data from the web tracking tool, such as Google Analytics, and sales data from the sales tool, such as Microsoft Navision, and evaluate them together. This allows the performance of the e-commerce store to be evaluated and the user journey to be viewed together with the actual purchase.
Data quality is easier to ensure with centralized storage since only one system and the data it contains need to be assessed. Fragmented data sources distributed throughout the organization, on the other hand, are very difficult to keep track of. The same is true for controlling access by individuals. When data is distributed throughout the organization and may not even have been stored in databases, it’s hard to track who has access to data they shouldn’t normally see.
Which other components belong to the Data Warehouse?
In addition to the data warehouse itself, other systems and components must be added to an architecture to enable centralized data storage. These include:
- ETL tool: To ensure querying and consolidation from various data sources, a tool is needed that queries the sources at regular intervals, consolidates the data, i.e., brings it into a uniform schema, and finally stores it in the data warehouse.
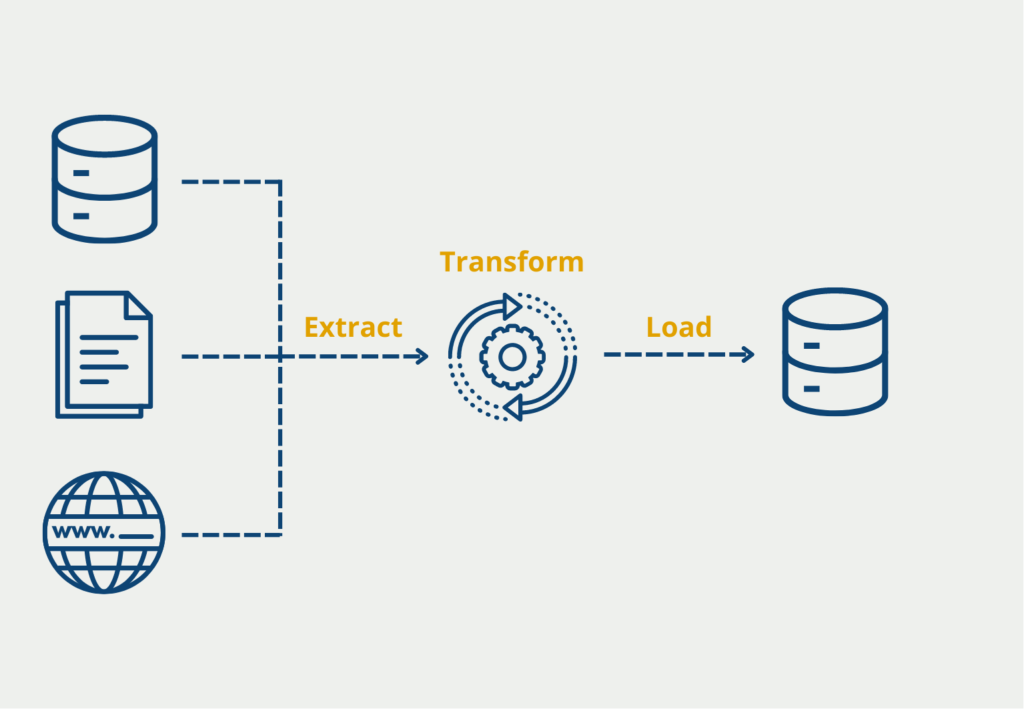
- Metadata storage: In addition to the actual data, so-called metadata must be stored. This includes, for example, user rights, which define which changes a person may make or which tables may be viewed. In addition, the data and table structure are also recorded, i.e. how the tables are related to each other.
- Further tools: The existence of the data in the data warehouse alone does not really help. In addition, other tools must be built in to use and process the information from it. Often, for example, a suitable visualization tool, such as Microsoft Power BI, is added so that data analyses can be created and aggregations performed. These ensure that knowledge can really be generated from the data.
What are the differences to the Data Lake?
This central database can additionally be supplemented by a data lake, in which unstructured raw data is stored temporarily at a low cost so that it can be used at a later date. The two concepts differ primarily in the data they store and the way the information is stored.
| Features | Data Warehouse | Data Lake |
|---|---|---|
| Data | Relational data from productive systems or other databases. | All Data Types (structured, semi-structured, unstructured). |
| Data Schema | Can be scheduled either before the data warehouse is created or only during the analysis (schema-on-write or schema-on-read) | Exclusively at the time of analysis (schema-on-read) |
| Query | With local memory very fast query results | – Decoupling of calculations and memory – Fast query results with inexpensive memory |
| Data Quality | – Pre-processed data from different sources – Unification – Single point of truth | – Raw data – Processed and unprocessed |
| Applications | Business intelligence and graphical preparation of data | Artificial Intelligence, Analytics, Business Intelligence, Big Data |
What points should be considered when implementing a data warehouse?
Implementing a data warehouse is a complex process that requires careful planning, attention to detail, and a deep understanding of the organization’s data needs. Below are some key considerations for implementing a data warehouse:
- Define the scope of the project: Clearly define the scope of the data warehouse project and determine the data sources that will be used. This will help you determine the hardware and software requirements for the project.
- Design the data warehouse: Design the schema, i.e. create a star or snowflake schema. This requires defining the fact tables, the dimension tables, and the relationships between them.
- Select an ETL tool: Choose an extraction, transformation, and loading (ETL) tool that can extract data from the source systems, transform the data to fit the data warehouse schema, and load the data into the database.
- Implement the ETL process: Implement the ETL process by configuring the ETL tool and defining the ETL workflows. This includes setting up the source-to-target mappings, transformations, and data quality checks.
- Loading the data: Load the data into the warehouse using the ETL tool. This can involve loading the data incrementally or in batches.
- Testing: Test the data warehouse to ensure that it works as expected. This is done by running queries and comparing the results to the source data.
- Tuning: Optimize the performance of the data warehouse by tuning the hardware and software components. This may mean adding more memory or disk space or optimizing database indexes.
- Train users: Train users to use the data warehouse and the business intelligence tools used to access the data warehouse.
- Maintaining: Maintain the data warehouse by monitoring its performance, troubleshooting problems that arise, and updating the schema of the data warehouse as needed.
Overall, implementing a data warehouse requires careful planning, attention to detail, and a deep understanding of the data needs of the business
This is what you should take with you
- A data warehouse stores company-wide information centrally.
- This is intended to support data-driven decisions and make business intelligence possible.
- The unstructured raw data in the data lake provides an excellent complement to the relational and processed data in the data warehouse.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Data Warehouses
- Amazon Web Services provides a good summary here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.