Hadoop is a software framework that can be used to easily process large amounts of data on distributed systems. It has mechanisms that ensure stable and fault-tolerant functionality so that the tool is ideally suited for data processing in the Big Data environment.
What are the Components of Hadoop?
The software framework itself is a compilation of a total of four components.
Hadoop Common is a collection of various modules and libraries that support the other components and enable them to work together. Among other things, the Java Archive files (JAR files) required to start Hadoop are stored here. In addition, the collection enables the provision of basic services, such as the file system.
The MapReduce algorithm origins from Google and helps to divide complex computing tasks into more manageable subprocesses and then distributes these across several systems, i.e. scale them horizontally. This significantly reduces computing time. In the end, the results of the subtasks have to be combined again into the overall result.
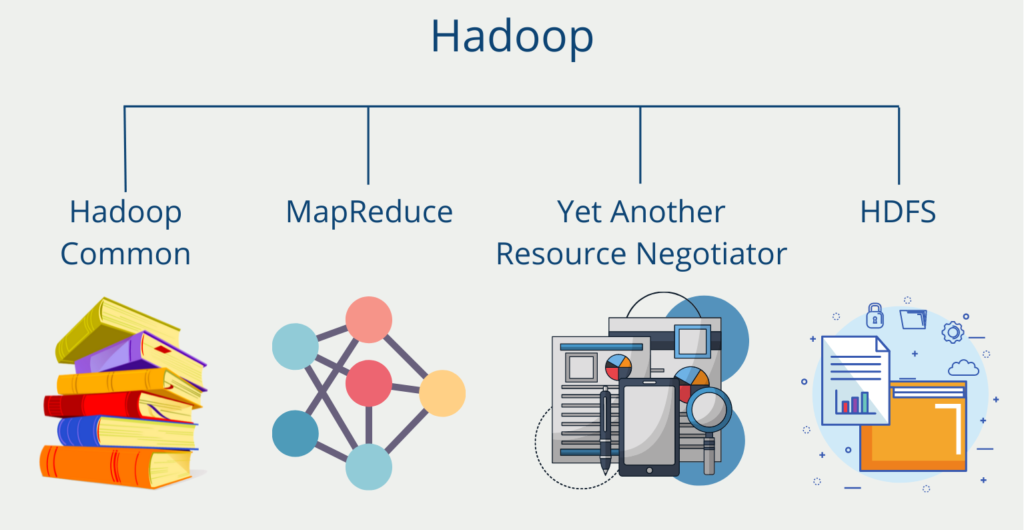
The Yet Another Resource Negotiator (YARN) supports the Map-Reduce algorithm by keeping track of the resources within a computer cluster and distributing the subtasks to individual computers. In addition, it allocates the capacities for individual processes.
The Hadoop Distributed File System (HDFS) is a scalable file system for storing intermediate or final results. Within the cluster, it is distributed across multiple computers to process large amounts of data quickly and efficiently. The idea behind this was that Big Data projects and data analysis is based on large amounts of data. Thus, there should be a system that also stores the data in batches and processes it quickly. The HDFS also ensures that duplicates of data records are stored in order to be able to cope with the failure of a computer.
How does Hadoop work?
Suppose we want to evaluate the word distribution from one million German books. This would be a daunting task for a single computer. In this example, the Map-Reduce algorithm would first divide the overall task into more manageable subprocesses. For example, this could be done by first looking at the books individually and determining the word occurrence and distribution for each book. The individual books would thus be distributed to the nodes and the result tables would be created for the individual works.
Within the computer cluster, we have a node that assumes the role of the so-called master. In our example, this node does not perform any direct calculation but merely distributes the tasks to the so-called slave nodes and coordinates the entire process. The slave nodes in turn read the books and store the word frequency and the word distribution.
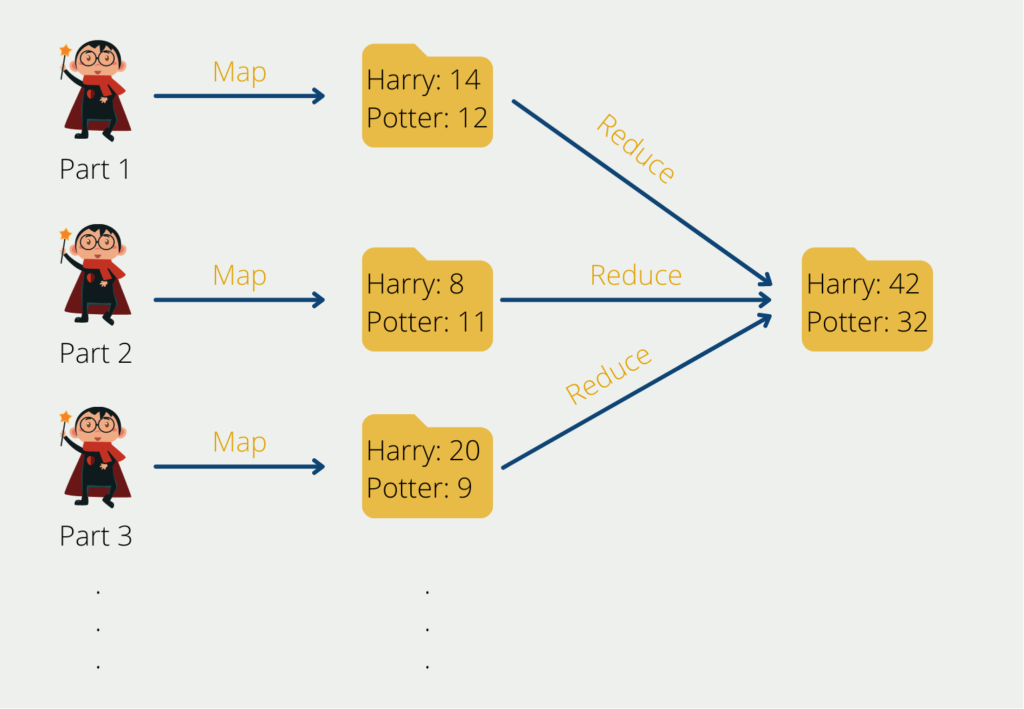
Once this step is complete, we can continue to work only with the result tables and no longer need the memory-intensive sourcebooks. The final task, i.e. aggregating the intermediate tables and calculating the final result, can then also be parallelized again or, depending on the effort involved, taken over by a single node.
What are the advantages and disadvantages of the program?
Hadoop is a powerful open-source software framework used to store and process large amounts of data in a distributed environment. It is designed to handle huge amounts of data, making it a popular choice for big data processing.
At a glance, it offers the following advantages:
- Scalability: the framework can be easily scaled to handle large amounts of data. Nodes can be added to the cluster to increase processing power, and data can be processed that exceeds the capacity of a single machine.
- Cost-effectiveness: Hadoop is open-source software, meaning it can be used and distributed for free. It also runs on commodity hardware, which is less expensive than proprietary hardware.
- Flexibility: the framework can handle a variety of data types, including structured, unstructured, and semi-structured data. It can also be integrated with a range of tools and technologies to create a customized data processing environment.
- Fault tolerance: Hadoop is fault-tolerant, meaning it can handle hardware or software failures without losing data or interrupting processing.
- High availability: it provides high availability through its distributed file system, which replicates data across multiple nodes in the cluster. This ensures that data is always available, even if one or more nodes fail.
In addition, these drawbacks should be considered.
- Complexity: The program is a complex system that requires specialized knowledge to deploy and manage. It can be difficult to set up and configure, and it may require significant investment in hardware and infrastructure.
- Latency: Hadoop is optimized for batch processing, which means it may not be suitable for applications that require low latency or real-time processing.
- Overhead: The framework introduces additional overhead due to the distributed nature of the system. This can lead to slower processing times and higher resource consumption.
- Data management: Hadoop does not include built-in tools for data management, such as data quality control or data sequence tracking. These must be implemented separately, which can increase the complexity and cost of the system.
In summary, Hadoop is a powerful tool for processing and analyzing big data. Its scalability, cost-effectiveness, flexibility, fault tolerance, and high availability make it a popular choice for big data processing. However, it also has some limitations, including complexity, latency, overhead, and lack of built-in data
What applications can be implemented with Hadoop?
The use of Hadoop is now widespread in many companies. Among them are well-known representatives such as Adobe, Facebook, Google, and Twitter. The main reason for its widespread use is the ability to process large volumes of data using clusters. These can also consist of relatively low-performance devices.
In addition, the various components can also be used to build specialized applications that are specifically adapted to the use case. In most cases, Apache Hadoop is used primarily for storing large volumes of data that are not necessarily to be stored in the data warehouse.
At Facebook, for example, copies of internal logs are stored so that they can be reused at a later time, for example, to train machine learning models. eBay, on the other hand, uses the Apache MapReduce algorithm to further optimize its website search.
What are the differences between Hadoop and a relational database?
Hadoop differs from a comparable relational database in several fundamental ways.
| Properties | Relational Database | Apache Hadoop |
| Data Types | Structured data only | all data types (structured, semi-structured, and unstructured) |
| Amount of Data | little to medium (in the range of a few GB) | large amounts of data (in the range of terabytes or petabytes) |
| Query Language | SQL | HQL (Hive Query Language) |
| Data Schema | Static Schema (Schema on Write) | Dynamic Schema (Schema on Read) |
| Costs | License costs depend on the database | free |
| Data Objects | Relational Tables | Key-Value Pair |
| Scaling Type | Vertical scaling (computer needs to get better in terms of hardware) | Horizontal scaling (more computers can be added to handle the load) |
What does the future of Hadoop look like?
The future of Hadoop is a topic that is always being discussed and debated in the industry. Here are some points to consider:
- Hadoop has been a popular big data processing technology for over a decade, but its use has declined in recent years due to the rise of cloud computing and other distributed computing technologies.
- Despite this decline, Hadoop is still used by many organizations and will likely continue to be used for some time.
- Hadoop is an open-source technology with a large community of developers, which means it will likely continue to be updated and improved over time.
- Some experts believe that Hadoop will continue to play a role in data processing and analysis, but will be used in conjunction with other technologies rather than as a standalone solution.
- As more and more data is generated and collected, the need for scalable and efficient data processing technologies will continue to grow, which could create new opportunities for Hadoop and similar technologies in the future.
This is what you should take with you
- Hadoop is a popular framework for distributed storage and processing of large amounts of data.
- Its advantages include fault tolerance, scalability, and low cost compared to traditional data storage and processing systems.
- The framework enables the parallel processing of large data sets and can handle a variety of data types and formats.
- However, Hadoop also has some drawbacks such as complexity, high hardware requirements, and a steep learning curve.
- Hadoop is used in industries such as finance, healthcare, and e-commerce for Big Data analytics, machine learning, and other data-intensive applications.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Hadoop
- Hadoop’s documentation provides insightful guidance on downloading and setting up the system.
- The table of differences between Hadoop and a relational database is based on the colleagues at datasolut.com.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.