The star schema describes the arrangement of database tables, which should be as memory-efficient and powerful as possible. As the name implies, the tables are arranged in a star shape in a so-called fact table, which is surrounded by several so-called dimension tables.
What is the structure of the scheme?
With large amounts of data stored in databases or the data warehouse quickly becomes confusing and queries are not only complicated but also take a relatively long time. Therefore, intelligent ways are needed to create tables so that memory can be saved and queries can take place more quickly.
The first approach to this is the star schema, which includes star-shaped table structures. A distinction is made between facts and dimensions:
- The facts are key figures or measured values that are to be analyzed or illustrated. They form the center of the analysis and are located in the central fact table. In addition to the key figures, this also consists of the keys that refer to the surrounding dimensions. In the business environment, facts are, for example, the sales quantity, the turnover, or the incoming orders.
- The dimensions, on the other hand, are the properties of the facts and can be used to visualize the key figures. The different levels of detail of the dimensions are then stored in these and thus memory can be saved since the details only have to be stored once in the dimension table. Dimensions in the corporate environment are, for example, customer information, the date of the order, or product information.
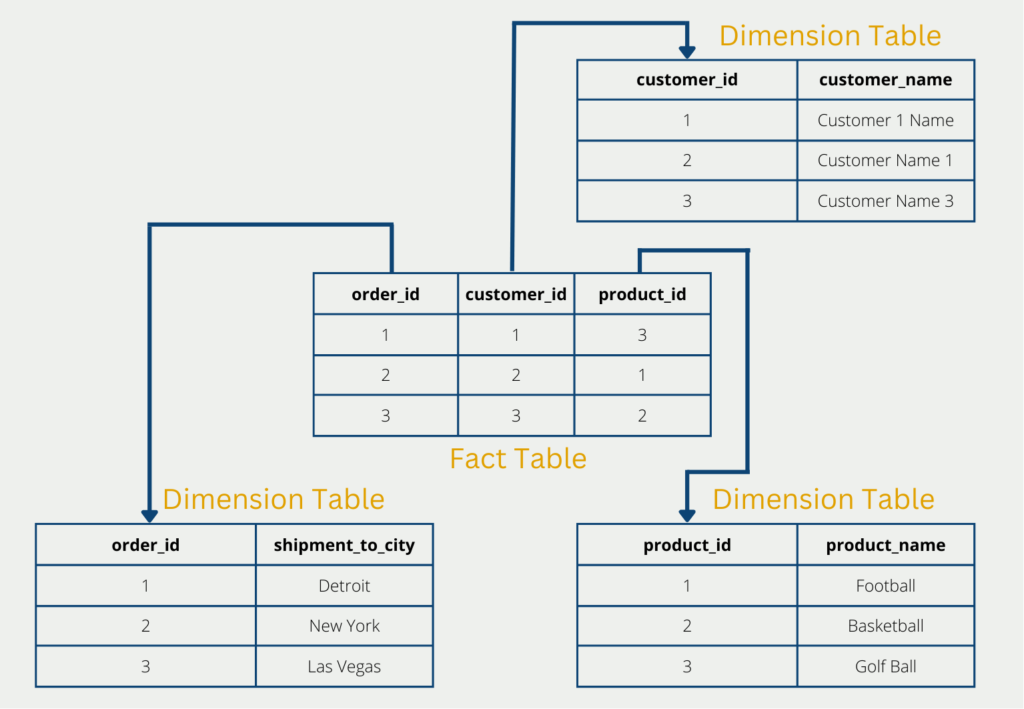
The star schema deliberately omits normalization, which is normally an important concept in database theory. The third normal form is namely violated with a star schema. On the other hand, the structure is particularly efficient and provides fast answers even for complex queries.
What is the Normalization?
When data is stored in databases, this can quickly become very confusing and redundant. Therefore, when creating a database schema, one should think about how redundant information, for example, duplicates, can be avoided.
Normalization is a sequence of different steps that are intended to prevent more and more avoidable redundancies. For this purpose, there are the so-called normal forms, which build on each other and have increasingly strict rules. For the star schema, only the first three normal forms are interesting, since a database in the star schema only fulfills the first two normal forms, but not the third:
- A database is in 1st normal form when all attributes/columns have only a single value. That is, there is no accumulation of values in any field.
- A database is in 2nd normal form when every attribute in the table is fully dependent on the primary key. This also means that all attributes that do not depend on the primary key must be swapped out to a separate database table. Of course, a database that is in 2nd normal form must also satisfy 1st normal form at the same time, since they build on each other. The same applies to the subsequent normal forms.
- A database is in 3rd normal form if no attribute that is not a primary key of the table does not refer to another non-key attribute. If this is the case, a new relation, i.e. a new table, must be created for it.
The star schema misses the third normal form in most cases because the dimension tables often contain several attributes that are not primary key attributes but nevertheless refer to each other. In the dimension table “Products”, for example, the price can be determined by the combination of the “Product name” and the “Color”, although neither the product name nor the color is a primary key attribute.
What are the advantages and disadvantages of the scheme?
Although the arrangement of tables as a star schema does not meet the requirements of normalization, since the third normal form is not given, it has some advantages that make it very popular in practical applications:
- The arrangement in the star schema is optimized for a high query load and thus offers the possibility to process even complex queries efficiently.
- Furthermore, by deliberately omitting the third normal form, unnecessary join operations are not necessary for most queries.
- By the arrangement in the star schema, a majority of the arising redundancies are avoided. This also leads to the fact that the dimension tables require comparatively little storage space and thus large amounts of data volume are saved.
- The star schema is a very understandable arrangement of relations in many applications since the division into fact and dimension tables is very intuitive and comprehensible.
However, there are also use cases in which the use of the star schema is not optimal, for example, when the dimension tables become very large and there are frequent queries on these tables. Then the query times can deteriorate significantly. In addition, as already mentioned, there may be redundancies in the data. Therefore, in addition to the star schema, a second database schema has been formed, which is intended to remedy the disadvantages.
What aspects should be considered when implementing a star schema?
The implementation of a star schema requires some considerations to ensure optimal performance and efficient querying. Some important implementation considerations are:
- Denormalization: In a star schema, the fact table is denormalized, which means that redundant data is stored in the table. This reduces the need for joins when querying the data and improves query performance.
- Data types: Choosing appropriate data types for the fact and dimension tables is important to ensure efficient storage and retrieval of data. The data types used should reflect the nature of the data being stored.
- Indexing: Creating appropriate indexes on the fact and dimension tables is crucial for fast querying. The indexes should be based on the queries that are commonly run on the data.
- Partitioning: Partitioning the fact table into smaller chunks based on time periods or other criteria can improve query performance by reducing the amount of data that needs to be scanned.
- Aggregation: Pre-aggregating data can improve query performance by reducing the amount of data that needs to be processed. Aggregation can be done at the fact or dimension level.
- Query optimization: Query optimization is important for ensuring that queries are executed efficiently. Techniques such as query rewriting materialized views, and caching can be used to improve query performance.
Overall, careful consideration of these implementation factors is critical for the successful implementation of a star schema and optimal performance when querying the data.
What is the Snowflake scheme?
The so-called snowflake scheme is a further expansion stage of the star scheme with the goal of completely normalizing the tables and thereby circumventing the disadvantages of the star scheme to a certain extent. The structure of snowflake results, in short, from the fact that the dimension tables are broken down and classified even further. The fact table, however, remains unchanged.
In our example, this could lead to the dimension table with the delivery addresses being further classified into country, state, and city. This normalizes the tables and the third normal form is also fulfilled, but this is at the expense of further branches. These are particularly disadvantageous in the case of a later query since these must be reassembled with complex joins.
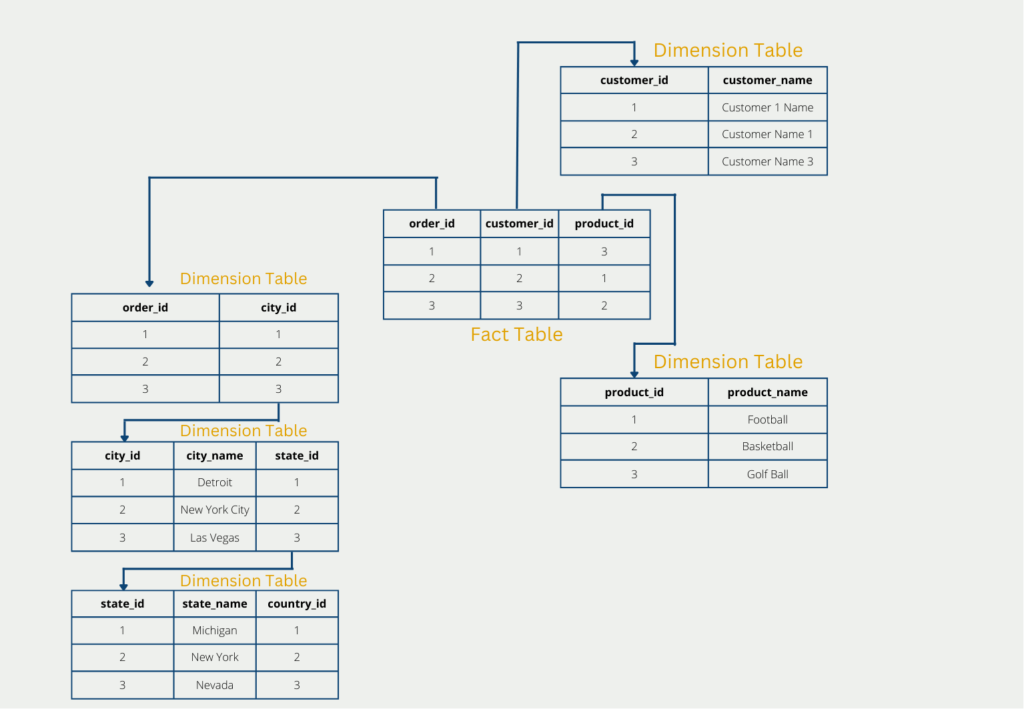
The further branching thus leads to the fact that the data is stored less redundantly and thus the amount of data is reduced again in comparison to the star schema. However, this is at the expense of performance, since the dimension tables have to be merged again during the query, which is often very time-consuming.
Starschema vs. Snowflake-Schema
The Star schema and the Snowflake schema are relatively similar in structure and are often compared with each other for this reason. In fact, the choice of a suitable database schema depends mainly on the concrete application.
In short, the goal of the star schema is to provide a good basis for frequent queries and still reduce the amount of data. This is created by splitting into fact and dimension tables. This allows many redundancies to be removed and the first two normal forms to be satisfied. The number of tables remains relatively small and thus queries with few joins and fast response times are possible. However, complete normalization of the database cannot be performed and some redundancies remain.
The snowflake schema, on the other hand, is a further development of the star schema with the aim of bringing about a normalization of the database. The fact table is retained and the dimension tables are further classified and divided into additional relations. Although this eliminates the remaining redundancies of the star schema, it makes queries slower and more time-consuming, since the dimension tables must first be merged again.
This is what you should take with you
- The star schema is a database schema that is used to enable the most efficient database queries.
- For this purpose, the original data is divided into the so-called fact table and several dimension tables.
- Although the star schema already eliminates many redundancies, some information is still stored twice. This is another reason why the star schema does not meet the requirements of normalization.
- A further development of the star schema is the so-called snowflake schema, which divides the dimension tables again into finer relations. However, this is at the expense of query performance.

SQL Tutorial for Beginners: SELECT, JOIN, GROUP BY Explained Simply
SQL Tutorial for Beginners: Why SQL Still Matters Whether you’re working through an SQL tutorial for beginners as a student or stepping into a data analyst role, SQL is the language that lets you query and analyze relational databases. Nearly every company stores structured data in a database system, and anyone who wants to make… Read More »SQL Tutorial for Beginners: SELECT, JOIN, GROUP BY Explained Simply

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.
Other Articles on the Topic of the Star Schema
Microsoft wrote a very interesting post on star schema and what it means for their business analytics platform Power BI.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.