In today’s machine learning literature, there is no way around the transformer models of the paper “Attention is all you need” (Vaswani et al. (2017)). Especially in the field of Natural Language Processing, the transformer models described in this paper for the first time (e.g. GPT-2 or BERT) are indispensable. In this paper, we want to explain the key points of this much-cited paper and show the resulting innovations.
What are Transformers?
“To the best of our knowledge, however, the Transformer is the first transduction model relying
entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution.”
Attention is all you need (Vaswani et al. (2017))
In understandable English, this means that the Transformer Model uses the so-called Self-Attention to find out for each word within a sentence the relationship to the other words in the same sentence. This does not require the use of Recurrent Neural Networks or Convolutional Neural Networks, as has been the case in the past. To understand why this is so extraordinary, we should first take a closer look at the areas in which transformers are used.
Where are transformers used?
Transformers are currently used primarily for translation tasks, such as those at www.deepl.com. In addition, these models are also suitable for other use cases within Natural Language Processing (NLP), such as answering questions, text summarization, or text classification. The GPT-2 model is an implementation of transformers whose applications and results can be tried out here.
Self-attention using the example of a translation
As we have already noted, the big novelty of the paper by Vaswani et al. (2017) was the use of the so-called self-attention mechanism for textual tasks. That this is a major component of the models as can be seen by looking at the general architecture of the transformers.
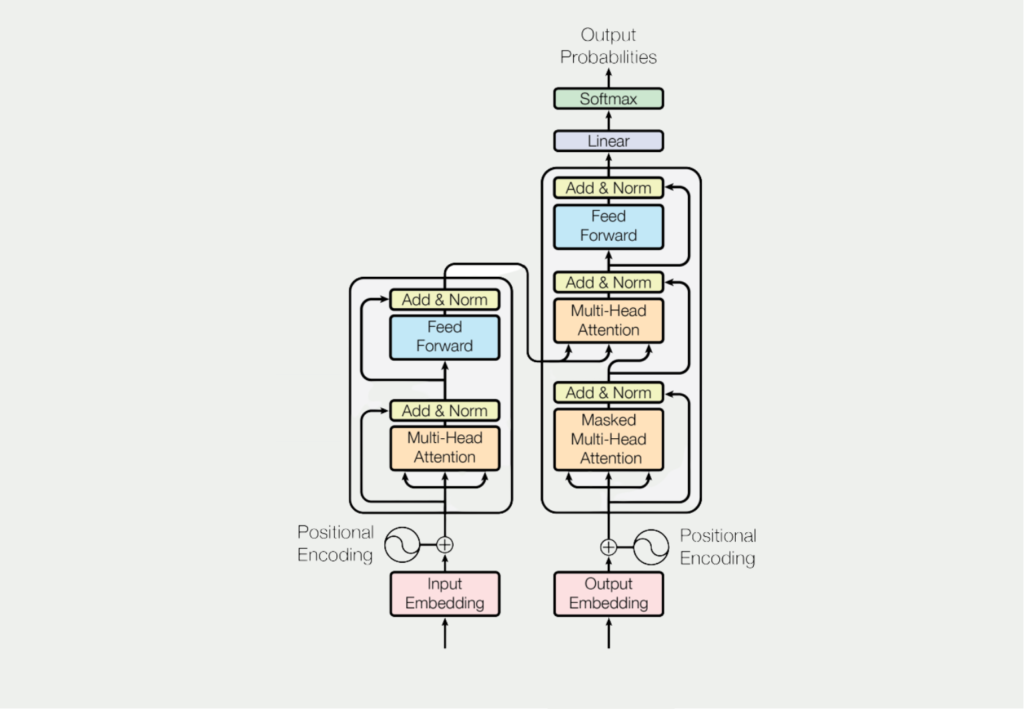
What this mechanism actually does and why it is so much better than the previous approaches becomes clear in the following example. For this purpose, the following German sentence is to be translated into English with the help of machine learning:
„Das Mädchen hat das Auto nicht gesehen, weil es zu müde war.“
Unfortunately, this task is not as easy for a computer as it is for us humans. The difficulty with this sentence is the little word “es”, which could theoretically stand for the girl or the car, although it is clear from the context that the girl is meant. And here’s the sticking point: context. How do we program an algorithm that understands the context of a sequence?
Before the publication of the paper “Attention is all you need”, so-called Recurrent Neural Networks were the state-of-the-art technology for such questions. These networks process word by word of a sentence. Until one arrives at the word “es”, all previous words must have been processed first. This leads to the fact that only a little information about the word “girl” is available in the network until the algorithm has arrived at the word “es” at all. The previous words “weil” and “gesehen” are at this time still clearly stronger in the consciousness of the algorithm. So there is the problem that dependencies within a sentence are lost if they are very far apart.
What do Transformer models do differently? These algorithms process the complete sentence simultaneously and do not proceed word by word. As soon as the algorithm wants to translate the word “es” in our example, it first runs through the so-called self-attention layer. This helps the program to recognize other words within the sentence that could help to translate the word “es”. In our example, most of the words within the sentence will have a low value for attention, and the word girl will have a high value. This way the context of the sentence is preserved in the translation.
What are the different types of Transformers?
In recent years, many examples have contributed to the popularity of transformer models in which the algorithms have produced excellent results in textual applications. These models are among the best-known types of transformers:
- Transformer encoder: This type of transformer was introduced in the paper “Attention is All You Need” by Vaswani et al. (2017). The aim is to process sequential data, such as that found in texts or time series data, by using the mechanism known as self-attention. This makes it possible to focus “attention” on different parts of the sequence. This model has achieved very good results, particularly in machine translation and sentiment analysis.
- BERT: BERT is the abbreviation for Bidirectional Encoder Representations from Transformers and was presented for the first time in the work by Devlin et al. (2018) under the name “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. The model is pre-trained on a large amount of data and learns to fill in so-called masking or gaps in the text as correctly as possible. This enables it to learn conceptual representations of words and sentences. This structure makes it very suitable for continuing text or question-answering systems.
- GPT: The Generative Pre-Trained Transformer, or GPT, is another type of transformer model that was first introduced in 2018 in the paper “Improving Language Understanding by Generative Pre-Training” by Radford et al. (2018). This model is also trained on large amounts of data, but with the difference that it pursues a generative language modeling goal to learn to generate new text that matches the input as well as possible.
- XLNet: The XLNet model is also based on the transformer architecture and was presented in the article “Generalized Autoregressive Pretraining for Language Understanding” by Yang et al. (2018). It is based on a permutation-based pre-training method that makes it possible to model all arrangements of the input sequence. This arrangement allowed it to beat the BERT model in some applications.
- T5: The T5 model (Text-to-Text Transfer Transformer) is a language model presented in 2019 by Rafael et al. in the paper “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”. It can be used for a range of tasks by simply naming the application in the input sequence. This allows a single model to be used that does not need to be fine-tuned for a specific application.
These models are the best-known types of transformers, which have also been able to deliver impressive results in practice. New architectures are also being sought in order to further improve existing models and achieve greater model efficiency.
LSTM and RNN vs. Transformer
Artificial intelligence is currently very short-lived, which means that new findings are sometimes very quickly outdated and improved. Just as LSTM has eliminated the weaknesses of Recurrent Neural Networks, so-called Transformer Models can deliver even better results than LSTM.
The transformers differ fundamentally from previous models in that they do not process texts word for word, but consider entire sections as a whole. Thus they have clear advantages to understand contexts better. Thus, the problems of short and long-term memory, which were partially solved by LSTMs, are no longer present, because if the sentence is considered as a whole anyway, there are no problems that dependencies could be forgotten.
In addition, transformers are bidirectional in computation, which means that when processing words, they can also include the immediately following and previous words in the computation. Classical RNN or LSTM models cannot do this, since they work sequentially and thus only preceding words are part of the computation. This disadvantage was tried to avoid with so-called bidirectional RNNs, however, these are more computationally expensive than transformers.
However, the bidirectional Recurrent Neural Networks still have small advantages over the transformers because the information is stored in so-called self-attention layers. With every token more to be recorded, this layer becomes harder to compute and thus increases the required computing power. This increase in effort, on the other hand, does not exist to this extent in bidirectional RNNs.
What are the limitations of a Transformer?
Although transformer models have become established in a large number of applications within natural language processing, these models also have limitations and disadvantages. On the one hand, a large amount of data is required to train a model that is as robust as possible. This can be particularly difficult in niches with very specialized vocabulary. However, transfer learning can be used in these cases and a general model can be fine-tuned for specific applications.
The biggest disadvantage of transformer models is the high computational effort required to calculate the standard model as well as for fine-tuning. Normal standard hardware is usually not sufficient for this and special servers are required that were built for machine learning applications and therefore contain several graphics cards, for example.
Transformer models are deep learning approaches that are usually difficult or impossible to interpret. As a result, the predictions resemble a black box and the output cannot be explained rationally. As a result, there is no understanding of how and why errors occur. This can lead to problems with the publicly accessible ChatGPT, for example, as it is difficult to find out what the cause of possible false statements is.
Despite the immense performance of Transformer models, there is still a need to further develop and expand them. This means that it is currently still a problem to train robust models if there is only little data available for the desired language or language domain.
Finally, with transformers, as with machine learning models in general, the question of fairness and justice arises, as the models depend very heavily on the training data and its quality. If there are conscious or unconscious biases in this data, there is a very high probability that they will be adopted by the model. In the case of language models, for example, this can mean racist or offensive statements. On the other hand, since large amounts of data are required, it is difficult to avoid such training data.
In conclusion, it can be said that although transformer models have made a great leap forward in the field of NLP, they still have some limitations. Therefore, research in this area continues to strive to find better and more efficient architectures.
This is what you should take with you
- Transformers enable new advances in the field of Natural Language Processing.
- Transformers use so-called attention layers. This means that all words in a sequence are used for the task, no matter how far apart the words are in the sequence.
- They replace Recurrent Neural Networks for such tasks.

What is Data Privacy?
Explore the essence of data privacy in our world. Uncover regulations, best practices, and the evolving landscape of personal information.

How can you create a website without hiring a developer?
In the past, building a new website usually required hiring an external service provider. Web developers still exist today, but they can be expensive. That’s why it’s great that there are also free options available. Here you can find out what they are and how you can benefit from them. What is a web developer?… Read More »How can you create a website without hiring a developer?

What is Knowledge Representation?
Explore Knowledge Representation in AI: Learn how machines store and process knowledge, powering the future of artificial intelligence.

What is Collaborative Filtering?
Unlock personalized recommendations with collaborative filtering. Discover how this powerful technique enhances user experiences. Learn more!

What is Quantum Computing?
Dive into the quantum revolution with our article of quantum computing. Uncover the future of computation and its transformative potential.

What is Anomaly Detection?
Discover effective anomaly detection techniques in data analysis. Detect outliers and unusual patterns for improved insights. Learn more now!
Other Articles on the Topic of Transformer Models
- You can find the original paper here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.