The Long Short-Term Memory (short: LSTM) model is a subtype of Recurrent Neural Networks (RNN). It is used to recognize patterns in data sequences, such as those that appear in sensor data, stock prices, or natural language. RNNs can do this because, in addition to the actual value, they also include its position in the sequence in the prediction.
What are Recurrent Neural Networks?
To understand how Recurrent Neural Networks work, we have to take another look at how regular feedforward neural networks are structured. In these, a neuron of the hidden layer is connected with the neurons from the previous layer and the neurons from the following layer. In such a network, the output of a neuron can only be passed forward, but never to a neuron on the same layer or even the previous layer, hence the name “feedforward”.
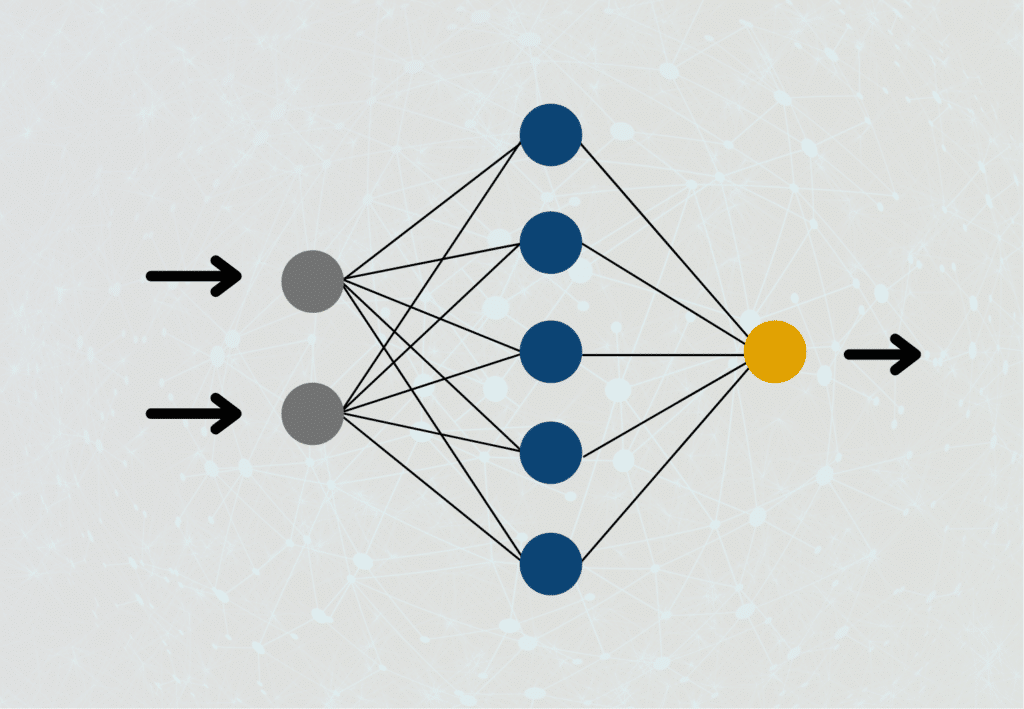
This is different for recurrent neural networks. The output of a neuron can very well be used as input for a previous layer or the current layer. This is much closer to how our brain works than how feedforward neural networks are constructed. In many applications, we also need to understand the steps computed immediately before improving the overall result.
What Problems do RNNs face?
Recurrent Neural Networks were a real breakthrough in the field of Deep Learning, as for the first time, the computations from the recent past were also included in the current computation, significantly improving the results in language processing. Nevertheless, during training, they also bring some problems that need to be taken into account.
As we have already explained in our article on the gradient method, when training neural networks with the gradient method, it can happen that the gradient either takes on very small values close to 0 or very large values close to infinity. In both cases, we cannot change the weights of the neurons during backpropagation, because the weight either does not change at all or we cannot multiply the number with such a large value. Because of the many interconnections in the recurrent neural network and the slightly modified form of the backpropagation algorithm used for it, the probability that these problems will occur is much higher than in normal feedforward networks.
Regular RNNs are very good at remembering contexts and incorporating them into predictions. For example, this allows the RNN to recognize that in the sentence “The clouds are at the ___” the word “sky” is needed to correctly complete the sentence in that context. In a longer sentence, on the other hand, it becomes much more difficult to maintain context. In the slightly modified sentence “The clouds, which partly flow into each other and hang low, are at the ___ “, it becomes much more difficult for a Recurrent Neural Network to infer the word “sky”.
How do Long Short-Term Memory Models work?
The problem with Recurrent Neural Networks is that they have a short-term memory to retain previous information in the current neuron. However, this ability decreases very quickly for longer sequences. As a remedy for this, the LSTM models were introduced to be able to retain past information even longer.
The problem with Recurrent Neural Networks is that they simply store the previous data in their “short-term memory”. Once the memory in it runs out, it simply deletes the longest retained information and replaces it with new data. The LSTM model attempts to escape this problem by retaining selected information in long-term memory. This long-term memory is stored in the so-called Cell State. In addition, there is also the hidden state, which we already know from normal neural networks and in which short-term information from the previous calculation steps is stored. The hidden state is the short-term memory of the model. This also explains the name Long Short-Term Networks.
In each computational step, the current input x(t) is used, the previous state of short-term memory c(t-1), and the previous state of hidden state h(t-1).
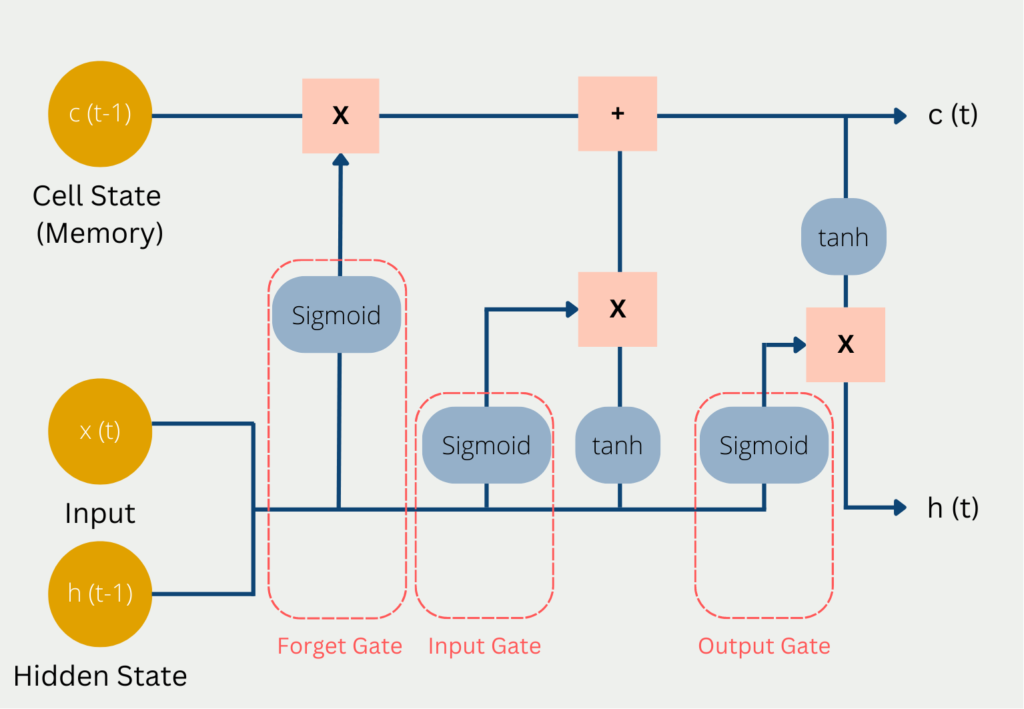
These three values pass through the following gates on their way to a new Cell State and Hidden State:
- In the so-called Forget Gate, it is decided which current and previous information is kept and which is thrown out. This includes the hidden status from the previous pass and the current input. These values are passed into a sigmoid function, which can only output values between 0 and 1. The value 0 means that previous information can be forgotten because there is possibly new, more important information. The number one means accordingly that the previous information is preserved. The results from this are multiplied by the current Cell State so that knowledge that is no longer needed is forgotten since it is multiplied by 0 and thus dropped out.
- In the Input Gate, it is decided how valuable the current input is to solve the task. For this, the current input is multiplied by the hidden state and the weight matrix of the last run. All information that appears important in the Input Gate is then added to the Cell State and forms the new Cell State c(t). This new Cell State is now the current state of the long-term memory and will be used in the next run.
- In the Output Gate, the output of the LSTM model is then calculated in the Hidden State. Depending on the application, it can be, for example, a word that complements the meaning of the sentence. To do this, the sigmoid function decides what information can come through the output gate and then the cell state is multiplied after it is activated with the tanh function.
Using our previous example, the whole thing becomes a bit more understandable. The goal of the LSTM is to fill the gap. So the model goes through word by word until it reaches the gap. In the Recurrent Neural Network, the problem here was that the model had already forgotten that the text was about clouds by the time it arrived at the gap.
As a result, no correct prediction could be made. Let us, therefore, consider how an LSTM would have behaved. The information “cloud” would very likely have simply ended up in the cell state, and thus would have been preserved throughout the entire computations. Arriving at the gap, the model would have recognized that the word “cloud” is essential to fill the gap correctly.
Which applications rely on LSTM?
For many years, LSTM Networks were the best tool in natural language processing because they could hold the context of a sentence “in memory” for a relatively long time. The following concrete programs rely on this type of neural network:
- Apple’s keyboard completion is based on an LSTM network. In addition, Siri, Apple’s voice assistant, was also based on this type of neural network.
- Google’s AlphaGo software also relied on long short-term memory and was thus able to beat real humans in the game of Go.
- Google’s translation service was based on LSTMs, among other things.
Nowadays, however, the importance of LSTMs in applications is declining somewhat, as so-called transformers are becoming more and more prevalent. However, these are very computationally intensive and have high demands on the infrastructure used. Therefore, in many cases, the higher quality must be weighed against the higher effort.
LSTM and RNN vs. Transformer
Artificial intelligence is currently very short-lived, which means that new findings are sometimes very quickly outdated and improved. Just as LSTM has eliminated the weaknesses of Recurrent Neural Networks, so-called Transformer Models can deliver even better results than LSTM.
The transformers differ fundamentally from previous models in that they do not process texts word for word, but consider entire sections as a whole. Thus they have clear advantages to understand contexts better. Thus, the problems of short and long-term memory, which were partially solved by LSTMs, are no longer present, because if the sentence is considered as a whole anyway, there are no problems that dependencies could be forgotten.
In addition, transformers are bidirectional in computation, which means that when processing words, they can also include the immediately following and previous words in the computation. Classical RNN or LSTM models cannot do this, since they work sequentially and thus only preceding words are part of the computation. This disadvantage was tried to avoid with so-called bidirectional RNNs, however, these are more computationally expensive than transformers.
However, the bidirectional Recurrent Neural Networks still have small advantages over the transformers because the information is stored in so-called self-attention layers. With every token more to be recorded, this layer becomes harder to compute and thus increases the required computing power. This increase in effort, on the other hand, does not exist to this extent in bidirectional RNNs.
This is what you should take with you
- LSTM models are a subtype of Recurrent Neural Networks.
- They are used to recognize patterns in data sequences, such as those that appear in sensor data, stock prices, or natural language.
- A special architecture allows the LSTM model to decide whether to retain previous information in short-term memory or discard it. As a result, even longer dependencies in sequences are recognized.

What is the Learning Rate?
Unlock the Power of Learning Rates in Machine Learning: Dive into Strategies, Optimization, and Fine-Tuning for Better Models.

What is Random Search?
Optimize Machine Learning Models: Learn how Random Search fine-tunes hyperparameters effectively.

What is the Lasso Regression?
Explore Lasso regression: a powerful tool for predictive modeling and feature selection in data science. Learn its applications and benefits.

What is the Omitted Variable Bias?
Understanding Omitted Variable Bias: Causes, Consequences, and Prevention in Research." Learn how to avoid this common pitfall.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.
Other Articles on the Topic of LSTM
- TensorFlow provides a tutorial on how to use LSTM layers in their models.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.