Boosting is a popular Machine Learning technique that has proven to be effective in improving the accuracy of various types of models. It is a type of ensemble learning, where multiple weak models are combined to form a strong model. Boosting algorithms have been widely used in areas such as computer vision, natural language processing, and speech recognition.
In this article, we will explore the concept of boosting in Machine Learning, how it works, and its various applications. We will also discuss the advantages and disadvantages of boosting, as well as some popular algorithms in this area.
What is Boosting?
In Machine Learning, not only individual models are used. In order to improve the performance of the entire program, several individual models are sometimes combined into a so-called ensemble. A random forest, for example, consists of many individual decision trees whose results are combined into one result.
Boosting describes the procedure of combining multiple models into an ensemble. Using the example of decision trees, the training data is used to train a tree. For all the data for which the first decision tree gives bad or wrong results, a second decision tree is formed. This is then trained using only the data that the first one misclassified. This chain is continued and the next tree in turn uses the information that led to wrong results in the first two trees.
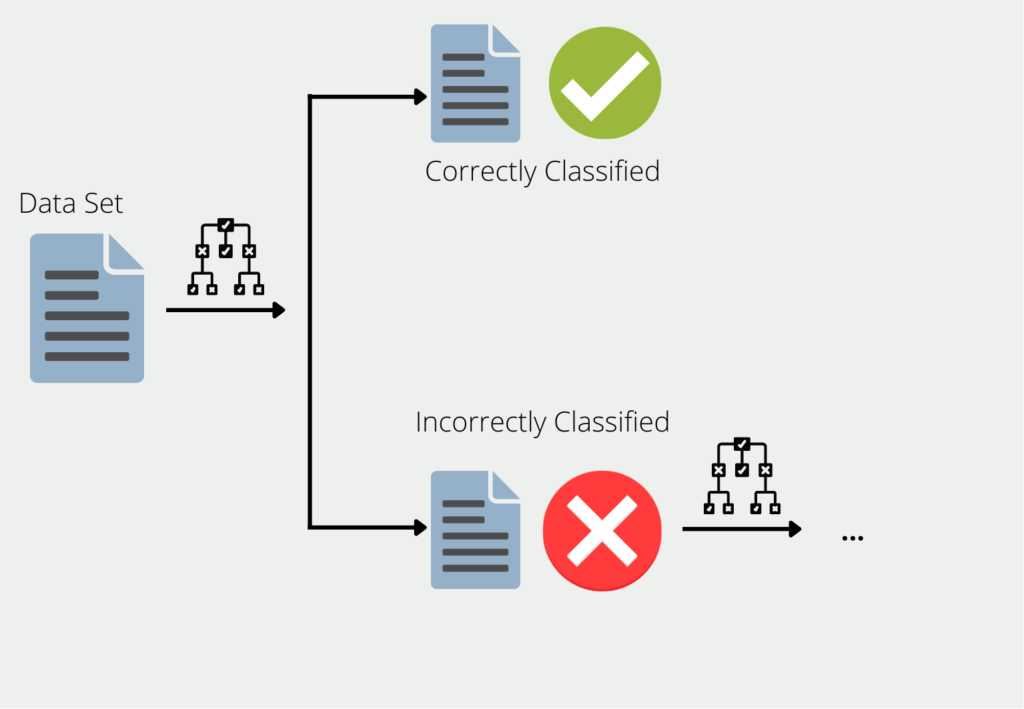
The ensemble of all these decision trees can then provide good results for the entire data set since each individual model compensates for the weaknesses of the others. This is also referred to as combining many “weak learners” into one “strong learner”.
What are the different algorithms for Boosting?
There are several popular boosting algorithms that have been developed over the years. Here are some of the most commonly used ones:
AdaBoost
Adaptive boosting, or AdaBoost for short, is a special variant of boosting. It tries to combine several weak learners into a strong model. In its basic form, Adaptive Boost works best with Decision Trees. However, we do not use the “full-grown” trees with partly several branches, but only the stumps, i.e. trees with only one branch. These are called “decision stumps”.

For our example, we want to train a classification that can predict whether a person is healthy or not. To do this, we use a total of three features: Age, weight, and the number of hours of exercise per week. In our dataset, there are a total of 20 studied individuals. The Adaptive Boost algorithm now works in several steps:
- Step 1: For each feature, a decision stump is trained with the weighted data set. In the beginning, all data points still have the same weight. In our case, this means that we have a single stump for age, weight, and sports hours, which directly classifies health based on the feature.
- Step 2: From the three Decision Stumps, we choose the model that had the best success rate. Suppose the stump with the sports lessons performed the best. Out of the 20 people, he was already able to classify 15 correctly. The five misclassified ones now get a higher weighting in the data set to ensure that they will be classified correctly in the next model.
- Step 3: The newly weighted data set is now used to train three new Decision Stumps again. With the “new” dataset”, this time the stump with the “Age” feature performed the best, misclassifying only three people.
- Step 4: Steps two and three are now repeated until either all data points have been correctly classified or the maximum number of iterations has been reached. This means that the model repeats the new weighting of the data set and the training of new decision stumps.
Now we understand where the name “Adaptive” comes from in AdaBoost. By reweighting the original data set, the ensemble “adapts” more and more to the concrete use case.
Gradient Boosting
Gradient boosting, in turn, is a subset of many, different boosting algorithms. The basic idea behind it is that the next model should be built in such a way that it further minimizes the ensemble loss function.
In the simplest cases, the loss function simply describes the difference between the model’s prediction and the actual value. Suppose we train an AI to predict a house price. The loss function could then simply be the Mean Squared Error between the actual price of the house and the predicted price of the house. Ideally, the function approaches zero over time and our model can predict correct prices.
New models are added as long as the prediction and reality no longer differ, i.e. the loss function has reached the minimum. Each new model tries to predict the error of the previous model.
Let’s go back to our example with house prices. Assume a property has a living area of 100m², four rooms, and a garage, and costs 200.000€. The gradient boosting procedure would then look like this:
Training a regression to predict the purchase price with the features living area, number of rooms, and garage. This model predicts a purchase price of 170,000 € instead of the actual 200,000 €, so the error is 30,000 €.
Training another regression that predicts the error of the previous model with the features of living space, number of rooms, and garage. This model predicts a deviation of 23,000 € instead of the actual 30,000 €. The remaining error is therefore 7,000 €.
XGBoost
XGBoost (Extreme Gradient Boosting) is a powerful implementation of the boosting algorithm that is widely used in machine learning. It was developed by Tianqi Chen and colleagues at the University of Washington and has become popular in both academia and industry due to its efficiency and accuracy.
XGBoost is a decision tree-based boosting algorithm that works by iteratively adding weak models to the ensemble to improve overall performance. It is designed to minimize loss functions while also considering the complexity of the model. It uses gradient descent to optimize the loss function and prunes the decision trees to avoid overfitting.
One of the key features of XGBoost is its ability to handle missing data. It does this by treating missing values as another feature and learning how to use them optimally. This is done by splitting the data into two groups: one with missing values and one without. The algorithm then learns how to best use the missing values by considering the patterns in the data and how they relate to the target variable.
Another important feature of XGBoost is its ability to handle large datasets with many features. It does this by using a technique called column sub-sampling, which randomly selects a subset of the features to use in each iteration. This helps to reduce overfitting and speed up the training process.
XGBoost also allows for parallel processing, which means that it can take advantage of multiple CPU cores to speed up the training process even further. Additionally, it has a variety of hyperparameters that can be tuned to improve its performance on specific tasks.
Overall, XGBoost is a powerful and flexible boosting algorithm that has become a popular choice for many Machine Learning applications. Its ability to handle missing data, large datasets, and parallel processing makes it well-suited for a wide range of tasks.
What are the advantages and disadvantages of Boosting?
The general advantage of boosting is that many weak learners are combined into one strong model. Despite a large number of small models, these boosting algorithms are usually easier to compute than comparable neural networks. However, this does not necessarily mean that they also produce worse results. In some cases, ensemble models can even beat the more complex networks in terms of accuracy. Thus, they are also interesting candidates for text or image classifications.
Furthermore, boosting algorithms, such as AdaBoost, are also less prone to overfitting. This simply means that they not only perform well with the training dataset but also classify well with new data with high accuracy. It is believed that the multilevel model computation of boosting algorithms is not as prone to dependencies as the layers in a neural network, since the models are not optimized contiguously as is the case with backpropagation in the model.
Due to the stepwise training of single models, boosting models often have a relatively slow learning rate and thus require more iterations to deliver good results. Furthermore, they require very good data sets, since the models are very sensitive to noise and this should be removed in the data preprocessing.
What are the differences between Boosting and Ensemble Learning?
Boosting and ensemble learning are two popular techniques used in Machine Learning for improving the accuracy of models. Ensemble learning refers to the process of combining multiple models to produce a final prediction. Boosting is a specific type of ensemble learning that involves sequentially adding models to the ensemble, with each new model focused on correcting the errors of the previous model.
Here are some key differences between boosting and ensemble learning:
- Sequential vs parallel: Boosting adds models sequentially, while ensemble learning combines models in parallel.
- Error correction: Boosting focuses on correcting the errors of previous models, while ensemble learning aims to combine the strengths of multiple models to achieve a better overall result.
- Model complexity: Boosting typically uses weak models, such as decision trees with a small depth, while ensemble learning can use more complex models.
- Training data: Boosting uses the same training data for each model, but adjusts the weights of misclassified samples, while ensemble learning can use different training data for each model.
- Prediction time: Boosting can be slower than ensemble learning, as each new model must be trained on the entire dataset, while ensemble learning only requires the training of multiple models in parallel.
Overall, both boosting and ensemble learning are effective techniques for improving the accuracy of machine learning models. The choice of which method to use depends on the specific problem and the available resources. Boosting is often used when there is a large amount of training data and when a high level of accuracy is required, while ensemble learning may be more appropriate when there are limited resources or when the goal is to balance accuracy and simplicity.
This is what you should take with you
- Boosting is a powerful Machine Learning technique that can improve the performance of weak learners.
- Boosting algorithms, such as AdaBoost, Gradient Boosting, and XGBoost, differ in their approaches to weight updating, feature selection, and model complexity.
- XGBoost is a widely used and powerful boosting algorithm that has won many data science competitions and is known for its speed and accuracy.
- Boosting can be compared to ensemble learning, which also combines multiple models, but boosting differs in how it iteratively updates weights and focuses on difficult examples.
- Boosting can be effective for a wide range of tasks, but can also be prone to overfitting and can require careful tuning of hyperparameters.
- Overall, boosting is a valuable technique to have in the machine learning toolkit and can greatly enhance the performance of models.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.

What is Feature Engineering?
Master the Art of Feature Engineering: Boost Model Performance and Accuracy with Data Transformations - Expert Tips and Techniques.

What are N-grams?
Unlocking NLP's Power: Explore n-grams in text analysis, language modeling, and more. Understand the significance of n-grams in NLP.

What is the No-Free-Lunch Theorem?
Unlocking No-Free-Lunch Theorem: Implications & Applications in ML & Optimization

What is Automated Data Labeling?
Unlock efficiency in machine learning with automated data labeling. Explore benefits, techniques, and tools for streamlined data preparation.
Other Articles on the Topic of Boosting
Amazon Web Services provide an interesting article on the topic.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.