![]()
When working with structured data in Python, it is almost impossible to avoid Excel and CSV files. Many external sources provide their information in this format, as it has a simple structure and is understood by many people. In addition, most users have a way of opening the files with Microsoft Office, for example, even without a programming language.
This article will show you how to Python for Excel and CSV files. This includes not only how the files can be opened, but also how existing files can be modified or new files created.
Why are CSV and Excel files important in Python?
In Python, many applications can be implemented using CSV and Excel files, which is why they are a central component in programming. For the following reasons, working with these file types in Python is advantageous:
- Data analysis and processing: Many sources provide their information in Excel or CSV files. Python offers a variety of tools to process and analyze this data. For example, Python can be used to subsequently save the data in a database or to clean it. Many of these analyses are either not possible in Excel or require significantly more time.
- Automation: In many applications, the processing of files is a recurring task. This can be easily automated with the Python programming language, saving time and resources by eliminating repetitive tasks.
- Interoperability: The ability to process Excel and CSV files in Python means that the programming language can be integrated into various workflows in which these file types are a predefined format for data transfer. This enables a seamless transition to other programs.
- Scalability: Compared to manual work with Excel and CSV files, the programming code can be easily scaled. The effort required for larger data sets remains similar and several files can be processed simultaneously. Manual work, on the other hand, would require more time or more people to be involved in the work.
There are therefore many advantages to using Python. For this reason, the following sections describe as simply as possible how to work with Excel and CSV files in Python.
Which libraries are required and how can they be installed?
Various modules and libraries are used in Python. These allow recurring and standardized functionalities to be used easily and do not have to be written from scratch each time. When working with Excel and CSV files in Python, this means that there are various libraries that already have predefined functions for opening these file types, for example. These can then be used quickly with little programming effort.
The following libraries already offer a very wide range of functionalities and cover the majority of the most common use cases. They are not included in the basic Python installation, so we will also show you how to install and use them.
- Pandas: One of the most powerful libraries for handling Excel and CSV files in Python is Pandas. It not only offers the possibility to read the information from the files, but can also be used for detailed data analysis. Pandas is very easy to install using “pip3”. The exclamation mark must be prefixed when the command is executed within a Jupyter notebook:
- Openpyxl: With the help of openpyxl, Excel files in “.xlsx” format can be read and also written. It also contains many different options for creating and editing tables.
- Xlrd and xlwt: The xlrd and xlwt libraries can be used to read and write older Excel files in “.xls” format. Xlrd is used for reading and xlwt for writing these files.
- csv: There is also a pure library for working with CSV files in Python. Although most of the functionalities can also be implemented with pandas, it can also make sense to work with csv in individual cases. In addition, csv is already included in the standard scope of Python and does not have to be installed separately like the other libraries presented.
With the help of these libraries, the majority of applications can already be implemented in Python when working with CSV or Excel files.
How can you work with CSV files in Python?
Working with CSV files in Python is very simple and can be implemented with both the Pandas and CSV library. This section shows the basic steps required to open, write and edit a CSV file.
To illustrate this, the so-called Auto-MPG data set is used, which is widely used in machine learning and specifies the average consumption for various car models in the American unit “miles per gallon”, among other things. This data set was first used in 1993 by J. Ross Quinlan in his paper “Combining instance-based and model-based learning” and can be downloaded from various platforms, such as Kaggle.
Reading CSV files in Python
In Pandas, reading CSV files is particularly easy as it only requires one line of programming code. The file can be read using “read_csv” and is automatically stored in a DataFrame, i.e. a tabular data structure.

Among other things, this function offers the option of defining the separator, which is a comma by default. However, especially in German-speaking countries, it can also happen that a semicolon (“;”) is used as a separator due to the number formatting, which can then be easily defined in Python.
In the CSV library, on the other hand, opening a CSV file requires significantly more commands. Like any other file, it is opened with “open” and then passed to the special CSV reader. This then converts each line of the file into a list of values.

In the CSV library, the delimiter can be defined using the “delimiter” parameter so that files can also be read in that do not correspond to the original formatting.
Creating CSV files in Python
Creating CSV files in Pandas is just as easy as reading in the files, provided that the information is already available in the form of a DataFrame. If this is not the case, it must first be converted so that a CSV file can be created from it.

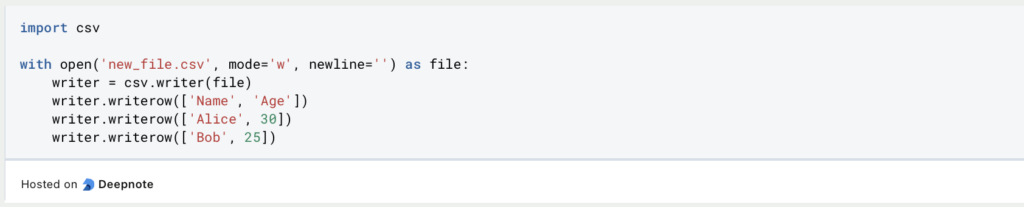
With CSV, on the other hand, the whole thing is a little more complex, as each line has to be defined individually and written to a file. If you already have a data structure for this, you can use a simple loop, but it can also happen that each line has to be written individually, as in this example:
Editing CSV files in Python
In Pandas, processing information from CSV files is relatively simple, as the underlying data structure allows a variety of changes and is intended for data analysis and processing.
For example, the lines can be filtered or sorted without further ado:

In this article you will find the most important commands that can be implemented with DataFrames and are therefore also very important for working with CSV files.
Because the CSV library does not have its own data structure, working with the imported files is also somewhat more complex. In most cases, you can work with various loops and write the results to a new file.
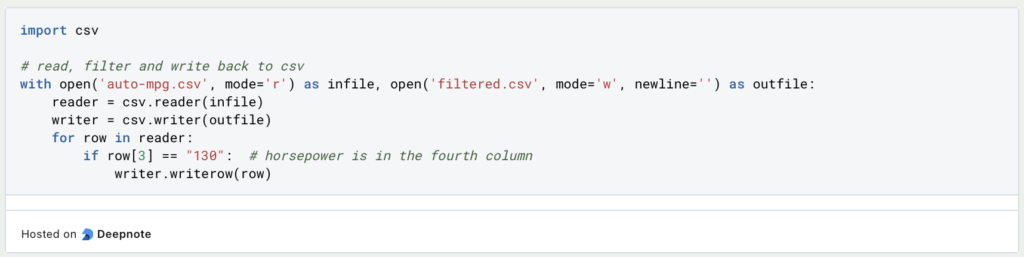
It also becomes more complex because the library recognizes the headings but cannot assign them correctly to the object. Objects must therefore be referenced via numerical indexes and cannot be addressed using their headers.
How can I work with Excel files in Python?
Python offers a variety of libraries that can be used to work with Excel files. In this section, however, we will limit ourselves to Pandas and Openpyxl, which can be used for the newer files in “.xlsx” format.
The use of the library depends primarily on the use case. Generally speaking, Pandas is the better alternative when it comes to the data contained in the file that is to be further analyzed. Openpyxl, on the other hand, can be used if the file itself is of interest and changes are to be made within the file, such as changing font colors or similar.
Reading Excel files in Python
In Pandas, Excel files can be easily read using a single line. The file can simply be defined using “read_excel” and the data is then stored in a DataFrame. As Excel files have the option of saving several spreadsheets, the name of the sheet must be explicitly mentioned when loading. If no name is stored, all spreadsheets are read in as a dictionary and the sheet names are then the keys of the dictionary.

In Openpyxl, more steps are required to read in a file. The “load_workbook” function is used here, in which the file is defined and read in. The sheet name can then also be used as a key for referencing. The data is then not available in any particular format, but can be run through and output using the “iter_rows” function.
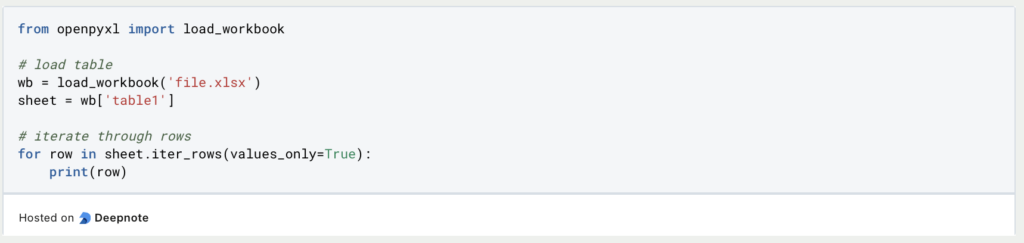
In contrast to Pandas, however, Openpyxl not only reads the pure values, but also other meta information, which will be of importance in the following sections.
Creating Excel files in Python
Saving a DataFrame in an Excel file is also possible in Pandas with just one line of code. In addition to the file name, a sheet name must also be defined. It also makes sense to set the “index” parameter to “false” to prevent the index of the DataFrame from also being stored in the file.

Of course, the data must first be converted into a DataFrame format before it can be processed in Pandas. Otherwise, saving the Excel file is much more complex.
In Openpyxl, the procedure for creating an Excel file is significantly different. The procedure is cell-by-cell and each value must be transferred to the file or spreadsheet. First a spreadsheet object is created and the headings defined. The rows and their values can then be appended in a list.
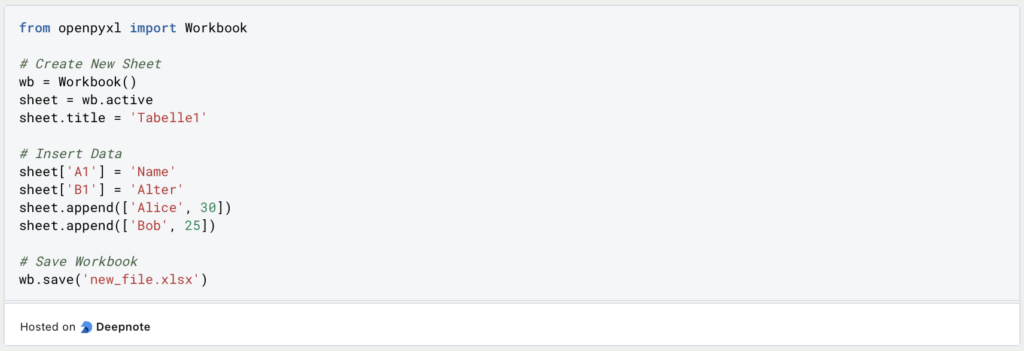
In contrast to Pandas, this is significantly more complex, but it also gives the user significantly more functionalities to choose from, as formatting, such as the font or font color, can also be defined beyond the values, for example.
Editing Excel files in Python
Editing Excel files in Pandas is similar to the options already known from the section on CSV files. In general, various adjustments can be made to the DataFrame and this can then be saved again as an Excel file.
In Openpyxl, editing the files is much more interesting, as there are a variety of options. Not only can individual cells or headings be changed, for example, but the formatting of the file can also be changed using the “styles” module. In addition to the font, colors can also be controlled here.
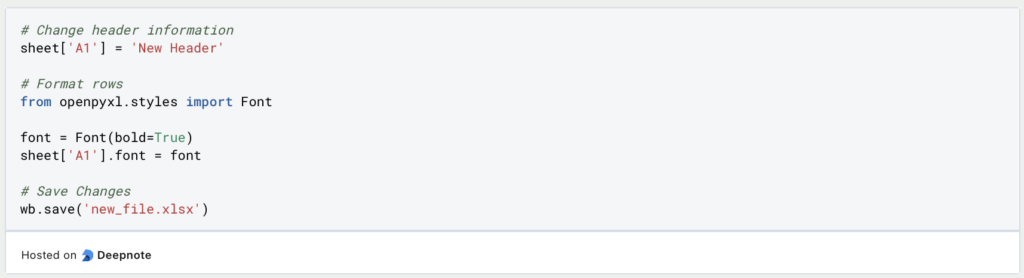
When editing Excel files in Python, you should ask yourself whether only the data should be read out and edited or whether the entire file should be changed. The appropriate library can then be selected depending on this.
This is what you should take with you
- Working with Excel and CSV files in Python is immensely important for a wide range of applications, such as data analysis or automating processes.
- With the help of pandas, many tasks can be implemented quickly and easily, especially when the information within the files is in the foreground.
- Openpyxl is a powerful library for working with Excel files in Python. It also offers the possibility to change fonts and other formatting settings.

Python Programming Basics: Learn it from scratch!
Master Python Programming Basics with our guide. Learn more about syntax, data types, control structures, and more. Start coding today!

What are Python Variables?
Dive into Python Variables: Explore data storage, dynamic typing, scoping, and best practices for efficient and readable code.

What is Jenkins?
Mastering Jenkins: Streamline DevOps with Powerful Automation. Learn CI/CD Concepts & Boost Software Delivery.

What are Conditional Statements in Python?
Learn how to use conditional statements in Python. Understand if-else, nested if, and elif statements for efficient programming.

What is XOR?
Explore XOR: The Exclusive OR operator's role in logic, encryption, math, AI, and technology.

How can you do Python Exception Handling?
Unlocking the Art of Python Exception Handling: Best Practices, Tips, and Key Differences Between Python 2 and Python 3.
Other Articles on using Python for Excel- and CSV files
In fact, you can now also use Python within Excel. Detailed information on this can be found on the Microsoft website.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.