Das Long Short-Term Memory (kurz: LSTM) Modell ist eine Unterform der Recurrent Neural Networks (RNN). Es wird genutzt, um Muster in Datensequenzen zu erkennen, wie sie beispielsweise in Sensordaten, Aktienkursen oder in der natürlichen Sprache auftauchen. Die RNN sind dazu in der Lage, weil sie neben dem tatsächlichen Wert auch dessen Position in der Sequenz in die Vorhersage mit einbeziehen.
Was sind Recurrent Neural Networks?
Um verstehen zu können, wie Recurrent Neural Networks funktionieren, müssen wir uns nochmal vor Augen führen, wie normale Feedforward Neuronale Netze aufgebaut sind. In diesen ist ein Neuron der Hidden Layer jeweils mit den Neuronen aus der vorherigen Schicht und den Neuronen aus der folgenden Schicht verbunden. Der Output eines Neurons kann in einem solchen Netzwerk immer nur nach vorne weitergereicht werden, jedoch niemals an ein Neuron auf derselben Schicht oder sogar der vorherigen Schicht, daher auch der Name „Feedforward“.
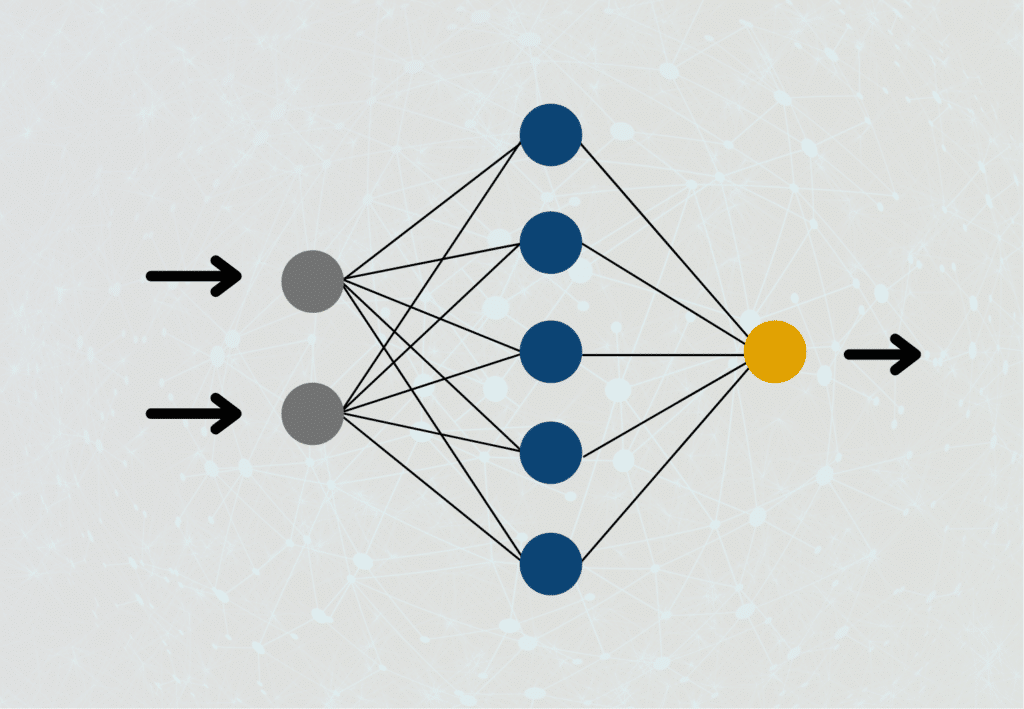
Bei Rekurrenten Neuronalen Netzwerken ist das anders. Der Output eines Neurons kann dort sehr wohl als Input einer vorherigen Schicht oder der aktuellen Schicht genutzt werden. Das kommt tatsächlich auch der Funktionsweise unseres Gehirns nochmal deutlich näher, als die Art und Weise, wie Feedforward Neuronale Netze aufgebaut sind. In vielen Anwendungen benötigen wir auch ein Verständnis für unmittelbar davor berechnete Schritte, um das Gesamtergebnis zu verbessern.
Welche Probleme haben RNNs?
Recurrent Neural Networks waren ein echter Durchbruch im Bereich des Deep Learnings, da zum ersten Mal auch die Berechnungen aus der jüngeren Vergangenheit mit in die aktuelle Berechnung mit einbezogen wurden und dadurch die Ergebnisse in der Sprachverarbeitung deutlich verbesserten. Trotzdem bringen sie während des Trainings auch einige Probleme mit sich, die es zu beachten gilt.
Wie wir in unserem Beitrag zum Gradientenverfahren bereits erläutert haben, kann es beim Training von Neuronalen Netzwerken mit dem Gradientenverfahren dazu kommen, dass der Gradient entweder sehr kleine Werte nahe 0 oder sehr große Werte in der Nähe von Unendlich annimmt. In beiden Fällen können wir die Gewichtungen der Neuronen während der Backpropagation nicht mehr abändern, da sich die Gewichtung entweder so gut wie gar nicht ändert oder wir aber die Zahl mit so einem großen Wert überhaupt nicht multiplizieren können. Aufgrund der vielen Vernetzungen im Rekurrenten Neuronalen Netzwerk und der leicht abgeänderten Form des Backpropagation Algorithmus, die dafür genutzt wird, ist die Wahrscheinlichkeit, dass es zu diesen Problemen kommen wird, deutlich höher als in normalen Feedforward Netzen.
Normale RNNs sind sehr gut dafür geeignet, sich Kontexte zu merken und in die Vorhersage mit einzubeziehen. Das ermöglicht es dem RNN beispielsweise zu erkennen, dass in dem Satz „Die Wolken sind am ___“ das Wort „Himmel“ benötigt wird, um in diesem Kontext den Satz richtig zu vervollständigen. In einem längeren Satz wird es hingegen deutlich schwieriger den Kontext aufrechtzuerhalten. Beim dem leicht veränderten Satz „Die Wolken, die teilweise fließend ineinander übergehen und tief hängen, sind am ___“ wird es für ein Recurrent Neural Network schon deutlich schwieriger auf das Wort „Himmel“ zu schließen.
Wie funktionieren Long Short-Term Memory Modelle?
Das Problem von Recurrent Neural Networks ist, dass sie zwar ein Kurzzeitgedächtnis besitzen, um vorherige Informationen im aktuellen Neuron noch vorzuhalten. Diese Fähigkeit nimmt jedoch bei längeren Sequenzen sehr schnell ab. Als Abhilfe dafür wurden die LSTM Modelle eingeführt, um vergangene Informationen noch länger vorhalten zu können.
Das Problem von Recurrent Neural Networks ist, dass sie die vorherigen Daten einfach in ihrem “Kurzzeitgedächtnis” abspeichern. Sobald der Speicher darin ausgeht, wird einfach die am längsten erhaltene Informationen gelöscht und durch die neuen Daten ersetzt. Das LSTM Modell versucht diesem Problem zu entkommen, indem es ausgewählte Informationen im Langzeitgedächtnis behält. Dieses Langzeitgedächtnis wird im sogennanten Cell State abgelegt. Zusätzlich dazu gibt es auch den Hidden State, den wir bereits von normalen Neuronalen Netzwerken kennen und in dem kurzzeitige Informationen, aus den vorherigen Berechnungsschritten abliegen. Der Hidden State ist das Kurzzeitgedächtnis des Modells. Somit erklärt sich auch der Name Long Short-Term Networks.
In jedem Berechnungsschritt wird der aktuelle Input x(t) genutzt, der vorherige Stand des Kurzzeitgedächtnis c(t-1) und der vorherige Stand des Hidden States h(t-1).
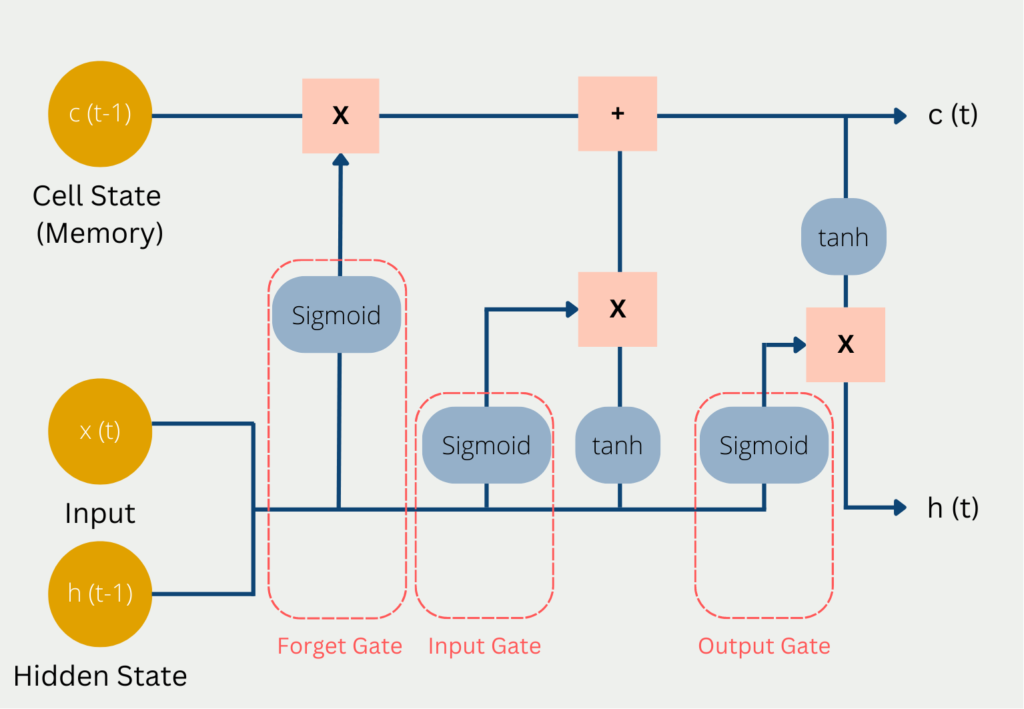
Diese drei Werte durchlaufen die folgenden Tore auf dem Weg zu einem neuen Cell State und Hidden State:
- Im sogenannten Forget Gate wird entschieden, welche aktuellen und vorherigen Informationen behalten werden und welche rausfliegen. Darin enthalten sind der Hidden Status aus dem vorherigen Durchlauf und der aktuelle Input. Diese Werte werden in eine Sigmoid Funktion gegeben, die lediglich Werte zwischen 0 und 1 ausgeben kann. Der Wert 0 bedeutet, dass eine vorherige Informationen vergessen werden kann, da es möglicherweise eine neue, wichtigere Information gibt. Die Zahl eins bedeutet entsprechend, dass die vorherigen Informationen erhalten bleibt. Die Ergebnisse hieraus werden mit dem aktuellen Cell State multipliziert, sodass Erkenntnisse, die nicht mehr gebraucht werden, vergessen werden, da sie mit 0 multipliziert werden und somit rausfallen.
- Im Input Gate wird entschieden wie wertvoll der aktuelle Input ist, um die Aufgabe zu lösen. Dazu wird der aktuelle Input mit dem Hidden State und der Weight Matrix des letzten Durchlaufs multipliziert. Alle Informationen, die im Input Gate als wichtig erscheinen, werden dann mit dem Cell State addiert und bilden den neuen Cell State c(t). Dieser neue Cell State ist nun der aktuelle Stand des Langzeitgedächtnis und wird im nächsten Durchlauf genutzt.
- Im Output Gate wird dann der Output des LSTM Modells im Hidden State berechnet. Je nach Anwendung kann es beispielsweise ein Wort sein, das die Bedeutung des Satzes komplementiert. Dazu entscheidet die Sigmoid Funktion, welche Informationen durch das Output Gate kommen können und anschließend wird der Cell State multipliziert, nachdem er mit der tanh Funktion aktiviert wurde.
Anhand unseres vorherigen Beispiels wird das ganze etwas verständlicher. Das Ziel des LSTMs ist es, die Lücke zu füllen. Das Modell durchläuft also Wort für Wort, bis es an der Lücke angelangt ist. Im Recurrent Neural Network war hierbei das Problem, dass das Modell bereits vergessen hatte, dass der Text von Wolken handelt, bis es an der Lücke angekommen ist. Dadurch konnte keine richtige Vorhersage gemacht werden. Betrachten wir deshalb, wie sich ein LSTM verhalten hätte. Die Information “Wolke” wäre sehr wahrscheinlich einfach im Cell State gelandet und dadurch die kompletten Berechnungen über erhalten geblieben. An der Lücke angekommen, hätte das Modell erkannt, dass das Wort “Wolke” essenziell ist, um die Lücke richtig füllen zu können.
Welche Anwendungen setzen auf LSTM?
Für viele Jahre waren LSTM Networks das beste Tool in der Sprachverarbeitung, da sie den Kontext eines Satzes verhältnismäßig lange “im Gedächtis” halten konnten. Die folgenden, konkreten Programme setzen auf diese Art der Neuronalen Netzwerke:
- Die Tastaturvervollständigung von Apple basiert auf einem LSTM Netzwerk. Außerdem wurde auch Siri, also der Apple Sprachassistent, auf dieser Art der Neuronalen Netzwerken basiert.
- Die AlphaGo Software von Google setzte auch auf das lange Kurzzeitgedächtnis und konnte dadurch echte Menschen im Spiel Go schlagen.
- Der Übersetzungsservice von Google basierte unter anderem auf LSTMs.
Heutzutage nimmt die Bedeutung von LSTMs in der Anwendung jedoch etwas ab, da sich die sogenannten Transformer immer mehr durchsetzen. Diese sind jedoch sehr rechenintensiv und haben hohe Ansprüche an die genutzte Infrastruktur. Deshalb muss in vielen Fällen die höhere Qualität gegen den höheren Aufwand abgewägt werden.
LSTM und RNN vs. Transformer
Die Künstliche Intelligenz ist aktuell sehr kurzlebig, was bedeutet, dass neue Erkenntnisse teilweise schon sehr schnell wieder überholt und verbessert wurden. Genaus so wie LSTM die Schwachstellen von Recurrent Neural Networks beseitigt hat, können sogenannte Transformer Modelle noch bessere Ergebnisse liefern als LSTM.
Die Transformer unterscheiden sich grundsätzlich darin zu bisheringen Modellen, dass sie Texte nicht Wort für prozessieren, sondern ganze Abschnitte als ganzes betrachten. Dadurch haben sie deutliche Vorteile Kontexte besser zu verstehen. Dadurch sind auch die Probleme des Kurz- und Langzeitgedächtnises, die mithilfe von LSTMs teilweise gelöst wurden, nicht mehr vorhanden, denn wenn man den Satz sowieso als Ganzes betrachtet, gibt es keinerlei Probleme, dass Abhängigkeiten vergessen werden könnten.
Darüber hinaus sind Transformer in der Berechnung bidirektional, was bedeutet, dass sie bei der Verarbeitung von Worten auch die unmittelbar folgenden und vorherigen Wörter in die Berechnung mit einbeziehen können. Klassische RNN oder LSTM Modelle können dies nicht, da sie sequenziell arbeiten und somit nur vorangegangene Wörter Teil der Berechnung sind. Dieser Nachteil wurde zwar versucht mit sogenannten bidirektionalen RNNs zu vermeiden, jedoch sind diese deutlich rechenaufwändiger als Transformer.
Die bidirektionalen Recurrent Neural Networks haben jedoch noch kleine Vorteile gegenüber den Transformern, da die Informationen in sogenannten Self-Attention Schichten gespeichert werden. Mit jedem Token mehr, das aufgenommen werden soll, wird diese Schicht schwerer zu berechnen und erhöht somit die benötigte Rechenleistung. Diese Erhöhung des Aufwands gibt es hingegen bei bidirektionalen RNNs nicht in diesem Ausmaß.
Das solltest Du mitnehmen
- LSTM Modelle sind eine Unterform von Recurrent Neural Networks.
- Sie werden genutzt, um Muster in Datensequenzen zu erkennen, wie sie beispielsweise in Sensordaten, Aktienkursen oder in der natürlichen Sprache auftauchen.
- Durch eine besondere Architektur kann das LSTM Modell entscheiden, ob es vorherige Informationen im Kurzzeitgedächtnis behält oder sie verwirft. Dadurch werden auch längere Abhängigkeiten in Sequenzen erkannt.

Was ist ein Elastic Net?
Entdecken Sie Elastic Net: Die vielseitige Regularisierungstechnik beim Machine Learning für bessere Modellbalance und Vorhersagen.

Was ist Adversarial Training?
Sicheres maschinelles Lernen: Erklärung von Adversarial Training, dessen Anwendungen und Probleme.

Was sind Echo State Networks?
Verstehen Sie Echo State Networks: Dynamic Time-Series Modeling, Applikationen und wie man sie in Python implementiert.

Was sind Faktorgraphen?
Entdecken Sie die Vielseitigkeit von Faktorgraphen bei der grafischen Modellierung und bei praktischen Anwendungen.

Was ist Unsupervised Domain Adaptation?
Beherrschen Sie die Unsupervised Domain Adaptation: Überbrücken Sie die Lücke zwischen Quell- und Zieldomänen für Lernmodelle.

Was ist Representation Learning?
Entdecken Sie die Leistungsfähigkeit des Representation Learnings: Erforschen Sie Anwendungen, Algorithmen und Auswirkungen.
Andere Beiträge zum Thema LSTM
- TensorFlow bietet ein Tutorial, wie man LSTM Schichten in deren Modellen nutzen kann.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.