Die Anomalieerkennung ist eine Technik zur Datenanalyse, um Datenpunkte oder Muster zu identifizieren, die nicht dem erwarteten Verhalten entsprechen oder nicht gut zum Rest des Datensatzes passen. Anomalien können auf Fehler bei der Datensammlung, der Datenverarbeitung oder den zugrunde liegenden Systemen hinweisen oder ungewöhnliche Ereignisse, Betrug oder Cyber-Angriffe darstellen.
Die Fähigkeit, Anomalien in großen Datensätzen zu erkennen, ist für Unternehmen, Organisationen und Regierungen entscheidend, um die Qualität, Sicherheit und Zuverlässigkeit ihrer Systeme und Dienste zu gewährleisten. In den letzten Jahren hat die zunehmende Verfügbarkeit von Big Data und Machine Learning-Algorithmen die Automatisierung des Anomalieerkennungsprozesses ermöglicht und die Effizienz und Genauigkeit in verschiedenen Bereichen wie Cybersicherheit, Finanzen, Gesundheit und Fertigung verbessert.
Welche Arten von Anomalien gibt es?
Die Anomalieerkennung ist der Prozess der Identifizierung von Mustern in Daten, die erheblich vom erwarteten Verhalten abweichen. Der Begriff “Anomalie” bezieht sich auf jede Beobachtung, die sich signifikant von anderen Beobachtungen in einem Datensatz unterscheidet. Anomalien können aus verschiedenen Gründen auftreten, einschließlich Messfehlern, Datenkorruption oder tatsächlich ungewöhnlichen Ereignissen. Im Allgemeinen lassen sich Anomalien in drei Typen kategorisieren:
- Punkt-Anomalien: Punkt-Anomalien beziehen sich auf einzelne Datenpunkte, die im Vergleich zu den anderen Daten als anomalous angesehen werden. Zum Beispiel könnte in einem Datensatz von Temperaturmessungen eine Punkt-Anomalie eine Messung sein, die deutlich höher oder niedriger ist als die anderen.
- Kontextuelle Anomalien: Kontextuelle Anomalien beziehen sich auf Datenpunkte, die innerhalb eines bestimmten Kontexts anomalous sind. Zum Beispiel könnte in einem Datensatz von Kreditkartentransaktionen eine Transaktion mit einem hohen Betrag im Kontext eines Kunden mit hohem Guthaben nicht als Anomalie betrachtet werden, aber für einen Kunden mit niedrigem Kreditlimit könnte sie eine Anomalie darstellen.
- Kollektive Anomalien: Kollektive Anomalien beziehen sich auf eine Gruppe von Datenpunkten, die zusammen betrachtet anomalous sind, aber einzeln nicht auffällig sein müssen. Zum Beispiel könnte in einem Datensatz von Netzwerkverkehr ein plötzlicher Anstieg des Verkehrsvolumens aus einer bestimmten Region als kollektive Anomalie betrachtet werden.
Diese Arten von Anomalien sind nützlich, um das Verhalten von Daten zu verstehen und Algorithmen zur Anomalieerkennung zu entwickeln. Anomalieerkennungsalgorithmen identifizieren in der Regel Anomalien basierend auf dem Typ der Daten und dem Kontext, in dem sie verwendet werden.
Welche Techniken werden bei der Anomalieerkennung genutzt?
Die Anomalieerkennung ist eine wichtige Aufgabe in der Datenanalyse, die darauf abzielt, ungewöhnliche Muster oder Ausreißer in den Daten zu identifizieren. Es gibt verschiedene Techniken für die Anomalieerkennung, darunter:
- Statistische Techniken: Diese Techniken basieren auf statistischen Modellen und Wahrscheinlichkeitstheorie, um Anomalien zu identifizieren. Beispielsweise werden das Z-Score-Verfahren und der Grubbs-Test häufig als statistische Techniken zur Erkennung von Ausreißern in Daten verwendet.
- Machine-Learning-Techniken: Machine-Learning-Techniken, einschließlich überwachtem und unüberwachtem Lernen, werden zur Anomalieerkennung eingesetzt. Bei überwachtem Lernen beinhaltet die Anomalieerkennung das Trainieren eines Modells mit normalen und anomalen Daten und anschließend die Verwendung des Modells zur Vorhersage von Anomalien. Im Gegensatz dazu identifizieren unüberwachte Lernmethoden Anomalien in Daten ohne vorheriges Wissen über normale und anomale Daten. Häufig verwendete Machine-Learning-Techniken für die Anomalieerkennung umfassen Clustering, Decision Trees, Support-Vector-Maschinen (SVM) und neuronale Netzwerke.

- Zeitreihentechniken: Zeitreihentechniken werden verwendet, um Anomalien in Zeitreihendaten wie Aktienkursen und Wetterdaten zu identifizieren. Diese Techniken nutzen historische Daten, um Muster zu identifizieren und Anomalien in zukünftigen Datenpunkten zu erkennen. Häufig verwendete Zeitreihentechniken zur Anomalieerkennung umfassen autoregressive integrierte Moving Average (ARIMA), saisonale Zerlegung von Zeitreihen (STL) und exponentielle Glättung.
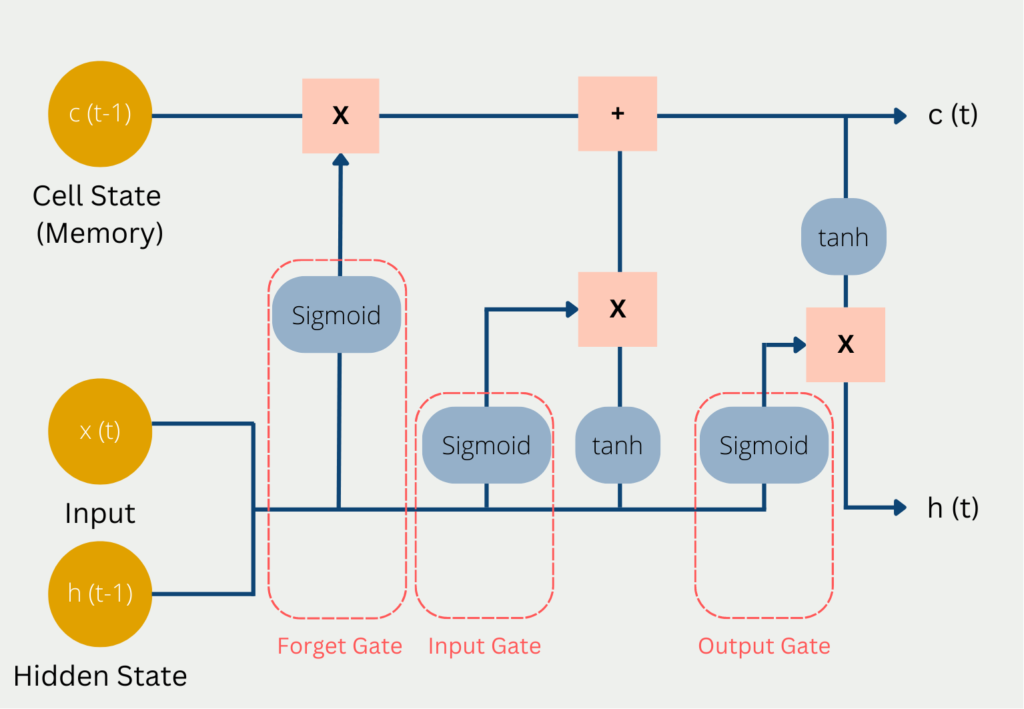
- Deep-Learning-Techniken: Deep-Learning-Techniken, einschließlich Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN) und Long Short-Term Memory (LSTM), werden zur Anomalieerkennung in Bild-, Audio- und Textdaten verwendet. Deep-Learning-Methoden können komplexe Muster identifizieren und Anomalien in Daten erkennen, die von anderen Techniken möglicherweise übersehen werden.
- Regelbasierte Techniken: Regelbasierte Techniken beinhalten das Festlegen von Regeln oder Schwellenwerten zur Erkennung von Anomalien in den Daten. Wenn sich beispielsweise ein Datenpunkt außerhalb eines vordefinierten Bereichs oder Schwellenwerts befindet, wird er als Anomalie markiert. Regelbasierte Techniken sind einfach umzusetzen und können effektiv sein, um Anomalien in bestimmten Bereichen wie Cybersicherheit und Betrugserkennung zu identifizieren.
Jede Technik hat ihre Stärken und Schwächen und ist möglicherweise für einen bestimmten Datentyp geeigneter. Die Auswahl der geeigneten Technik für die Anomalieerkennung hängt daher von der Art der Daten und den spezifischen Anforderungen der Anwendung ab.
Warum ist die Datenbereinigung bei der Anomalieerkennung wichtig?
Die Datenbereinigung ist ein entscheidender Schritt in der Anomalieerkennung, der die Genauigkeit und Effektivität der Algorithmen wesentlich beeinflusst. Sie umfasst mehrere Überlegungen zur Vorbereitung der Daten für die Analyse.
Ein wichtiger Aspekt ist die Datenbereinigung, bei der fehlende Werte, Ausreißer und inkonsistente Datenpunkte behandelt werden. Fehlende Werte können mithilfe von Techniken wie Mittelwert- oder Median-Imputation ergänzt werden. Ausreißer, die die Analyse verfälschen können, können identifiziert und angemessen entfernt oder ersetzt werden.
Eine weitere Überlegung ist das Feature Scaling, bei dem sichergestellt wird, dass die Merkmale auf einer ähnlichen Skala liegen. Dieser Schritt ist wichtig, da Anomalieerkennungsalgorithmen häufig auf Distanz- oder Ähnlichkeitsmaßen basieren. Techniken wie Min-Max-Skalierung, Standardisierung oder robustes Scaling können angewendet werden, um dies zu erreichen.
Die Dimensionsreduktion ist ebenfalls wichtig, um die Berechnungskomplexität zu reduzieren und dem Fluch der Dimensionalität entgegenzuwirken. Techniken wie die Hauptkomponentenanalyse (PCA) oder die lineare Diskriminanzanalyse (LDA) können verwendet werden, um relevante Informationen zu extrahieren und gleichzeitig die Anzahl der Merkmale zu reduzieren.
Der Umgang mit unausgeglichenen Datensätzen ist eine Herausforderung bei der Anomalieerkennung, bei der normale Instanzen möglicherweise deutlich mehr vertreten sind als anomale Instanzen. Techniken wie Over- und Undersampling oder spezialisierte Algorithmen für unausgeglichene Daten können verwendet werden, um den Datensatz auszugleichen und eine verzerrte Ergebnisbildung zu verhindern.
Die Auswahl und Entwicklung von Merkmalen spielt eine Rolle bei der Identifizierung der relevantesten Merkmale und der Erstellung neuer Merkmale. Techniken wie Korrelationsanalyse oder Schätzung der Merkmalbedeutung können bei der Auswahl aussagekräftiger Merkmale helfen. Die durch domänenspezifisches Wissen gesteuerte Merkmalsentwicklung ermöglicht die Erstellung neuer Merkmale auf der Grundlage eines tiefen Verständnisses des Problemfeldes.
Durch sorgfältige Berücksichtigung dieser Vorverarbeitungsschritte können Analysten die Genauigkeit und Zuverlässigkeit von Anomalieerkennungsmodellen verbessern. Eine effektive Datenbereinigung trägt dazu bei, bedeutungsvolle Anomalien zu erkennen und fundierte Entscheidungen auf der Grundlage der Ergebnisse zu treffen.
Wie bewertet man die Anomalieerkennung?
Die Anomalieerkennung ist eine wichtige Aufgabe in vielen Bereichen wie Finanzen, Gesundheitswesen, Cybersicherheit und industrieller Automatisierung. Es gibt mehrere Bewertungsmetriken, die häufig zur Beurteilung der Leistung von Anomalieerkennungstechniken verwendet werden, darunter:
- Genauigkeit: Dies ist die am häufigsten verwendete Metrik zur Bewertung von Anomalieerkennungstechniken. Sie misst den Prozentsatz der korrekt klassifizierten Anomalien in den Daten.
- Präzision: Die Präzision misst den Prozentsatz der korrekt klassifizierten Anomalien von allen erkannten Anomalien. Diese Metrik ist wichtig, wenn die Kosten für falsch positive Ergebnisse hoch sind.
- Recall: Der Recall misst den Prozentsatz der korrekt klassifizierten Anomalien von allen tatsächlichen Anomalien in den Daten. Diese Metrik ist wichtig, wenn die Kosten für falsch negative Ergebnisse hoch sind.
- F1-Score: Der F1-Score ist ein gewichteter harmonischer Mittelwert aus Präzision und Recall. Er ist eine gute Metrik, wenn sowohl falsch positive als auch falsch negative Ergebnisse wichtig sind.
- Fläche unter der Receiver Operating Characteristic (ROC) Curve: Die ROC-Kurve ist eine grafische Darstellung der Leistung einer Anomalieerkennungstechnik. Die Fläche unter der Kurve wird als Metrik zur Bewertung der Leistung der Technik verwendet.
- Falsch-Positiv-Rate (FPR): Die FPR misst den Prozentsatz der nicht-anomalen Datenpunkte, die als Anomalien klassifiziert wurden. Sie ist eine wichtige Metrik, wenn die Kosten für falsch positive Ergebnisse hoch sind.
- Falsch-Negativ-Rate (FNR): Die FNR misst den Prozentsatz der tatsächlichen Anomalien, die von der Technik nicht erkannt wurden. Sie ist eine wichtige Metrik, wenn die Kosten für falsch negative Ergebnisse hoch sind.
- Mean Time to Detection (MTTD): MTTD misst die Zeit, die benötigt wird, um eine Anomalie von der Technik erkannt zu werden. Diese Metrik ist wichtig, wenn eine rechtzeitige Erkennung von Anomalien entscheidend ist.
Es ist wichtig, die Bewertungsmetrik(en) sorgfältig auf der Grundlage des spezifischen Anwendungsfalls und der Anforderungen der Anwendung zu wählen. Darüber hinaus ist es wichtig, die Leistung der Technik sowohl auf Trainings- als auch auf Testdaten zu bewerten, um sicherzustellen, dass sie gut auf neuen, unbekannten Daten generalisiert.
Wie geht man mit unausgeglichenen Datensätzen bei der Anomalieerkennung um?
Ungleichgewichtete Daten stellen eine bedeutende Herausforderung für Anomalieerkennungsalgorithmen dar. Das Klassenungleichgewicht, bei dem normale Instanzen deutlich häufiger vorkommen als anormale Instanzen, kann zu verzerrten Modellen führen, die Schwierigkeiten haben, seltene Anomalien genau zu identifizieren. Die Algorithmen neigen dazu, die Mehrheitsklasse zu priorisieren, was zu einer höheren Tendenz führt, Instanzen als normal zu klassifizieren und somit zu einer höheren Falsch-Negativ-Rate führt. Das bedeutet, dass der Algorithmus möglicherweise entscheidende anomale Muster übersieht, was die Effektivität der Anomalieerkennung beeinträchtigt. Der Umgang mit unausgeglichenen Daten ist entscheidend, um sicherzustellen, dass die Algorithmen seltene Anomalien effektiv erkennen und hervorheben können, um zuverlässigere Ergebnisse für Entscheidungsfindung und Risikomanagement zu liefern.
Es gibt verschiedene Techniken und Ansätze, um dieses Ungleichgewicht zu überwinden:
- Resampling-Techniken: Sie zielen darauf ab, den Datensatz durch Oversampling der Minderheitsklasse (anomale Instanzen) oder Undersampling der Mehrheitsklasse (normale Instanzen) neu auszugleichen. Oversampling-Techniken generieren synthetische Beispiele für die Minderheitsklasse, z. B. durch Duplizierung oder durch Verwendung von Algorithmen wie der Synthetic Minority Over-sampling Technique (SMOTE). Undersampling-Techniken entfernen zufällig Instanzen aus der Mehrheitsklasse, um eine ausgewogene Verteilung zu erreichen. Ziel ist es, eine gerechtere Darstellung beider Klassen zu schaffen, damit der Anomalieerkennungsalgorithmus aus einem ausgewogenen Datensatz lernen kann.
- Algorithmische Ansätze: Spezialisierte Algorithmen wurden entwickelt, um mit unausgeglichenen Daten umzugehen und können direkt in der Anomalieerkennung eingesetzt werden. Diese Algorithmen verwenden in der Regel Techniken wie kostenempfindliches Lernen, bei dem die Kosten für Fehlklassifizierungen an das Klassenungleichgewicht angepasst werden. Sie weisen der Minderheitsklasse höhere Fehlklassifizierungsstrafen zu, um den Algorithmus dazu zu bringen, Anomalien genauer zu erkennen.
- Ensemble-Methoden: Sie kombinieren mehrere Anomalieerkennungsmodelle, um die Leistung auf unausgeglichenen Daten zu verbessern. Durch das Training mehrerer Modelle auf unterschiedlichen Teilmengen des unausgeglichenen Datensatzes und die Aggregation ihrer Vorhersagen können Ensemble-Methoden einen robusteren und ausgewogeneren Entscheidungsprozess ermöglichen. Techniken wie Bagging, Boosting oder Stacking können eingesetzt werden, um diverse Modelle zu erstellen, die gemeinsam sowohl normale als auch anomale Muster effektiv erfassen.
- Schwellenwertfestlegung für Anomaliescores: Die Anpassung des Schwellenwerts für Anomaliescores kann eine effektive Strategie zur Behandlung unausgeglichener Daten sein. Anomaliescores stellen den Grad der Abnormalität dar, der jeder Instanz durch den Erkennungsalgorithmus zugewiesen wird. Durch Festlegen eines niedrigeren Schwellenwerts für Anomalien wird der Algorithmus empfindlicher für die Erkennung der Minderheitsklasse. Diese Methode sollte jedoch sorgfältig abgestimmt werden, um eine übermäßige Anzahl von falsch positiven Ergebnissen zu vermeiden.
- Kosten-Nutzen-Analyse: Durchführen einer Kosten-Nutzen-Analyse hilft dabei, die Auswirkungen verschiedener Fehlklassifizierungsszenarien zu verstehen. Indem unterschiedliche Kosten oder Nutzen für falsch positive und falsch negative Ergebnisse zugewiesen werden, kann die Auswahl geeigneter Anomalieerkennungstechniken gesteuert werden. Zum Beispiel können in bestimmten Bereichen falsch negative Ergebnisse (übersehene Anomalien) schwerwiegende Folgen haben, während falsch positive Ergebnisse (Fehlalarme) weniger Auswirkungen haben können. Durch Berücksichtigung der spezifischen Kosten und Nutzen kann die Erkennung von Anomalien gegenüber falsch positiven Ergebnissen priorisiert oder umgekehrt werden.
Der Umgang mit unausgeglichenen Daten in der Anomalieerkennung erfordert eine sorgfältige Überlegung und maßgeschneiderte Ansätze. Die Wahl der Technik hängt von den Eigenschaften des Datensatzes, der Domäne und dem gewünschten Kompromiss zwischen Erkennungsleistung und Fehlalarmen ab. Durch Anwendung geeigneter Resampling-Techniken, algorithmischer Ansätze, Ensemble-Methoden sowie Berücksichtigung des geeigneten Anomalieschwellenwerts und der Kosten-Nutzen-Analyse können Analysten die Herausforderungen durch unausgeglichene Daten effektiv bewältigen und zu verbesserten Ergebnissen bei der Anomalieerkennung führen.
Was sind die Anwendungen der Anomalieerkennung?
Die Anomalieerkennung ist eine wichtige Aufgabe in verschiedenen Bereichen wie Finanzen, Gesundheitswesen, Sicherheit und Fertigung. Hier sind einige der häufigsten Anwendungen:
- Betrugserkennung: Die Anomalieerkennung kann verwendet werden, um betrügerische Aktivitäten in Finanztransaktionen wie Kreditkartenbetrug und Geldwäsche aufzudecken.
- Cybersicherheit: Sie kann verwendet werden, um bösartige Aktivitäten und Netzwerkeindringlinge in Computernetzwerken zu erkennen.
- Gesundheitswesen: Die Anomalieerkennung kann verwendet werden, um Anomalien in medizinischen Bildern wie CT-Scans, MRT und Röntgenaufnahmen zu erkennen, um eine frühzeitige Erkennung von Krankheiten zu unterstützen.
- Fertigung: Sie kann verwendet werden, um Anomalien in Produktionslinien zu erkennen und Ausfälle von Geräten vorherzusagen, um Ausfallzeiten zu verhindern und die Effizienz zu verbessern.
- Internet der Dinge (IoT): Die Anomalieerkennung kann verwendet werden, um Datenströme von IoT-Geräten wie Temperatursensoren und Vibrationsensoren zu überwachen und Anomalien zu erkennen.
- Energie: Die Anomalieerkennung kann verwendet werden, um Anomalien in Mustern des Energieverbrauchs zu erkennen und zukünftige Energiebedarfe vorherzusagen.
- Transportwesen: Die Anomalieerkennung kann verwendet werden, um Anomalien im Verkehrsfluss zu überwachen und zu erkennen und Verkehrsstaus vorherzusagen.
- Soziale Medien: Diese Technik kann verwendet werden, um abnormale Aktivitäten wie Falschmeldungen und Spam in sozialen Medien zu erkennen.
Insgesamt spielt die Anomalieerkennung eine wichtige Rolle bei der Identifizierung abnormen Verhaltens und der Verhinderung potenzieller Bedrohungen, was sie zu einem unverzichtbaren Werkzeug in vielen Bereichen macht.
Das solltest Du mitnehmen
- Die Erkennung von Anomalien ist eine wichtige Aufgabe in vielen Bereichen wie Cybersicherheit, Finanzen, Gesundheitswesen und Fertigung.
- Es gibt verschiedene Arten von Anomalien, darunter punktuelle Anomalien, kontextbezogene Anomalien und kollektive Anomalien.
- Techniken zur Erkennung von Anomalien können in überwachte, nicht überwachte und halbüberwachte Methoden unterteilt werden.
- Zu den gängigen Algorithmen für die Erkennung von Anomalien gehören statistische Modelle, Clustering, neuronale Netze und Entscheidungsbäume.
- Die Bewertung von Techniken zur Erkennung von Anomalien kann anhand von Metriken wie Präzision, Rückruf, F1-Score und ROC-Kurve erfolgen.
- Zu den Anwendungen für die Erkennung von Anomalien gehören die Erkennung von Betrug, Fehlern, Einbrüchen, vorausschauender Wartung und anomaliebasierter Einbruchsicherung.
- Die Wirksamkeit der Anomalieerkennung hängt von der Qualität der Daten, der Wahl des Algorithmus und der Abstimmung der Parameter ab.
- Die Erkennung von Anomalien ist ein sich schnell entwickelnder Bereich, in dem neue Algorithmen und Techniken entwickelt werden, um immer komplexere und umfangreichere Daten zu verarbeiten.

Was ist Collaborative Filtering?
Erschließen Sie Empfehlungen mit Collaborative Filtering. Entdecken Sie, wie diese leistungsstarke Technik das Nutzererlebnis verbessert.

Was ist Quantencomputing?
Tauchen Sie ein in das Quantencomputing. Entdecken Sie die Zukunft des Rechnens und sein transformatives Potenzial.

Was ist das T5-Model?
Entdecken Sie die Leistungsfähigkeit des T5-Modells für NLP-Aufgaben - lernen Sie die Implementierung in Python und Architektur kennen.


Was ist MLOps?
Entdecken Sie MLOps und erfahren Sie, wie es den Einsatz von maschinellem Lernen revolutioniert. Erkunden Sie die wichtigsten Konzepte.

Was ist ein Jupyter Notebook?
Lernen Sie, wie Sie Ihre Produktivität mit Jupyter Notebooks steigern können! Entdecken Sie Tipps und Best Practices für Data Science.
Andere Beiträge zum Thema Anomalieerkennung
Einen ausführlichen Artikel über die Erkennung von Anomalien in Scikit-Learn findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.