Der Generative Pretrained Transformer 3, kurz GPT-3, ist ein Deep Learning Modell aus dem Bereich des Natural Language Processings, das unter anderem in der Lage ist selbstständig Texte zu verfassen, Dialoge zu führen oder aus Text Programmiercode abzuleiten. Die dritte Version des Modells, genauso wie die vorherigen, wurde von OpenAI trainiert und zur Verfügung gestellt.
Was ist ein Generative Pretrained Transformer?
GPT (Generative Pre-trained Transformer) ist eine Art Sprachmodell, das mithilfe von Deep Learning eine menschenähnliche natürliche Sprache erzeugt. Das Modell wird auf einem großen Korpus von Textdaten, wie Wikipedia oder Webseiten, vortrainiert, um die Muster und Strukturen der Sprache zu lernen. Das Vortraining erfolgt durch das Trainieren eines neuronalen Transformer-Netzes zur Vorhersage des nächsten Wortes in einer Folge von Wörtern.
Wenn das Modell eine Aufforderung erhält, generiert es eine Fortsetzung dieser Aufforderung, indem es das wahrscheinlichste Wort vorhersagt, das auf den gegebenen Kontext folgt. Dieser Vorgang wird mehrfach wiederholt, um eine längere Wortfolge zu erzeugen.
GPT verwendet einen Aufmerksamkeitsmechanismus, der es dem Modell ermöglicht, sich bei der Generierung der Ausgabe auf die wichtigsten Teile der Eingabesequenz zu konzentrieren. Dies hilft dem Modell, kohärentere und aussagekräftigere Antworten zu erzeugen.
Die GPT-Modelle werden in der Regel mit einer Variante der Transformerarchitektur trainiert, die aus mehreren Encoder- und Decoderschichten besteht. Die Kodierschichten verarbeiten die Eingabesequenz und extrahieren Merkmale, die von den Dekodierschichten verwendet werden, um die Ausgabesequenz zu erzeugen.
GPT-3 ist ein sehr großes und leistungsfähiges Sprachmodell mit bis zu 175 Milliarden Parametern, was um Größenordnungen mehr ist als bei früheren GPT-Modellen. Dadurch kann es sehr komplexe und anspruchsvolle Sprache generieren, was zu einer Reihe potenzieller Anwendungen geführt hat, von Chatbots bis hin zu automatischen Schreibassistenten.
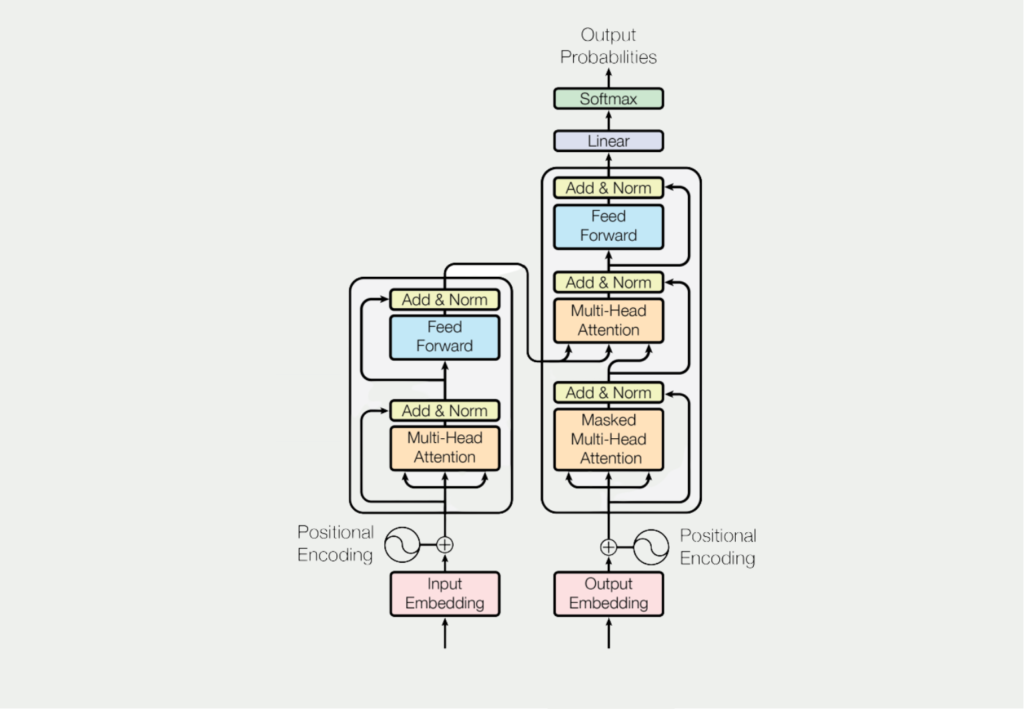
Die verschiedenen Generationen der GPT Modelle unterscheiden sich in ihrem technischen Aufbau nicht wirklich, sondern basieren auf unterschiedlichen Datensätzen mit denen sie trainiert wurden. Das GPT-3 Modell beispielsweise nutzt diese Datensätze:
- Common Crawl umfasst Daten aus zwölf Jahren Web Scraping inklusive Website Daten, Metadaten und Texten.
- WebText2 enthält Websites, die in Reddit Posts erwähnt wurden. Als Qualitätsmerkmal müssen die URLs mindestens einen Reddit Score von 3 haben.
- Books1 und Books2 sind zwei Datensätze bestehend aus Büchern, die im Internet verfügbar sind.
- Wikipedia Corpus enthält englische Wikipedia Seiten zu verschiedensten Themen.
Wofür kann man es nutzen?
Es gibt verschiedene Anwendungsfälle für den Einsatz eines GPT-3 Modells. Neben der reinen Texterstellung und -weiterführung können unter anderem auch komplette Computerprogramme erstellt werden. Hier sind einige Beispielanwendungen, die OpenAI auf ihrer Homepage nennen:
- Question-Answering System: Mithilfe eines kurzen, inhaltlichen Textes können auf verschiedenste Fragen die passenden Antworten generiert werden.
- Grammatikkorrekturen: In der englischen Sprache können grammatikalisch falsche Sätze verbessert werden.
- Zusammenfassungen: Längere Texte können in kurze, prägnante Abschnitte zusammengefasst werden. Dabei können auch die Schwierigkeitsstufen frei gewählt werden, sodass kompliziertere Texte in möglichst einfacher Sprache zusammengefasst werden.
- Umwandlung von natürlicher Sprache in Programmiercode: Das GPT-3 Modell kann sprachliche Umschreibungen von Algorithmen in konkreten Code umwandeln. Dabei werden verschiedene Sprachen und Anwendungen unterstützt, wie beispielsweise Python oder SQL.

- Marketingtext generieren: Das Modell kann auch genutzt werden, um aus einfachen und kurzen Produktbeschreibungen ansprechende Werbetexte zu generieren, die auf das Produkt angepasst sind.
Was sind die Schwächen eines GPT-3 Modells?
Obwohl das GPT-3 Modell ein breites Spektrum an Aufgaben abdeckt und in diesen auch sehr gute Ergebnisse liefert, gibt es ein paar, wenn auch sehr wenige, Schwächen des Modells. Die zwei Hauptpunkte, die in vielen Beiträgen dazu genannt werden, sind:
- Das Modell kann aktuell nur 2048 tokens (etwa 1.500 Wörter) als Input nutzen und als Output wieder zurückgeben. Aktuelle Forschungsprojekte versuchen diese Größe weiter zu erhöhen.
- Das GPT-3 Modell hat keine Art von Gedächtnis. Das bedeutet, dass jede Berechnung und jeder Task einzeln betrachtet wird, unabhängig von dem, was das Modell davor oder danach berechnet.
Wenn man die Anwendungsfälle aus unserem vorherigen Kapitel sieht, kann man schnell denken, dass dieses Modell viele menschliche Tätigkeiten bereits in naher Zukunft ersetzen kann. Obwohl die Ergebnisse in einzelnen Fällen bereits sehr beeindruckend sind, ist das Modell jedoch aktuell noch eher weit davon entfernt wirkliche Aufgaben oder Jobs zu übernehmen. Wenn wir beispielsweise Programmieren als Anwendungsfall nehmen, werden nur wenige Programme mit 1.500 “Wörtern” als Output auskommen. Selbst wenn der Code in verschiedenen Stufen berechnet und zusammengesetzt wird, ist es eher unwahrscheinlich, dass die unabhängig generierten Bausteine einwandfrei zusammenarbeiten können.
Welche Probleme können Sich durch GPT-3 ergeben?
Als Sprachmodell der künstlichen Intelligenz hat GPT-3 das Potenzial, mehrere Bereiche zu revolutionieren, darunter die Verarbeitung natürlicher Sprache, die Erstellung von Inhalten und die Automatisierung. Seine immensen Fähigkeiten werfen jedoch auch ethische Überlegungen auf, die es zu berücksichtigen gilt.
Eines der Hauptprobleme ist die Möglichkeit, dass GPT-3 zur Erstellung von Fake News, Propaganda oder Fehlinformationen verwendet wird. Das Modell kann sehr überzeugende Artikel oder Texte generieren, so dass es schwierig ist, zwischen echten und gefälschten Inhalten zu unterscheiden. Diese Fähigkeit könnte von böswilligen Akteuren missbraucht werden, um falsche Informationen zu verbreiten und die öffentliche Meinung zu manipulieren.
Ein weiteres ethisches Problem sind die möglichen Verzerrungen des GPT-3-Modells. Das Modell wird auf der Grundlage riesiger Datenmengen trainiert, von denen viele implizite Vorurteile enthalten können, die in den vom Modell erzeugten Ergebnissen verstärkt werden könnten. Diese Vorurteile könnten mit Rasse, Geschlecht, Religion oder anderen Merkmalen zusammenhängen und zur Diskriminierung oder Ausgrenzung bestimmter Gruppen führen.
Darüber hinaus besteht die Möglichkeit, dass GPT-3 zur Automatisierung bestimmter Arbeitsplätze eingesetzt wird, was zu Arbeitslosigkeit und Ungleichheit führen könnte. Die Automatisierung kann zwar die Effizienz und Produktivität steigern, könnte aber auch negative Folgen für die Gesellschaft haben, wenn sie nicht richtig umgesetzt wird.
Schließlich stellt sich die Frage, welche Rolle die KI in der Gesellschaft spielen und wie sie reguliert werden sollte, auch aus ethischer Sicht. Mit der zunehmenden Verbreitung von GPT-3 und anderen KI-Modellen müssen die politischen Entscheidungsträger überlegen, wie sie die Vorteile dieser Technologien gegen die potenziellen Risiken abwägen und sicherstellen können, dass sie ethisch und verantwortungsbewusst eingesetzt werden. Dazu gehört die Entwicklung geeigneter rechtlicher und regulatorischer Rahmenbedingungen sowie die Förderung von Transparenz und Verantwortlichkeit bei der Entwicklung und Nutzung von KI-Modellen wie GPT-3.
Was ist ChatGPT?
ChatGPT (Generative Pre-trained Transformer) ist ein Sprachmodell, das von OpenAI, einem führenden Forschungslabor für künstliche Intelligenz, entwickelt wurde. Es basiert auf der Transformer-Architektur, einer Art von tiefem neuronalem Netzwerk, das sich bei NLP-Aufgaben wie Sprachübersetzung, Textzusammenfassung und Fragenbeantwortung als außergewöhnlich leistungsfähig erwiesen hat.
ChatGPT ist ein “generatives” Modell, das heißt, es kann selbständig Text generieren, indem es das wahrscheinlichste nächste Wort in einer Sequenz vorhersagt. Es wird mit riesigen Mengen von Textdaten aus dem Internet (z. B. Wikipedia-Artikel, Bücher und Webseiten) “trainiert”, um die statistischen Muster und Strukturen der natürlichen Sprache zu lernen. Durch dieses Vortraining erwirbt es ein umfangreiches Wissen über die Sprache und die Fähigkeit, kohärente und flüssige Texte zu produzieren.
Wie könnte ChatGPT unsere Welt verändern?
ChatGPT hat das Potenzial, unsere Welt in mehrfacher Hinsicht zu verändern, da es uns ermöglicht, natürlichsprachliche Texte auf neue und innovative Weise zu verarbeiten und zu erzeugen.
- Revolutionierung der Kommunikation: Es kann zur Verbesserung der Kommunikation in verschiedenen Bereichen eingesetzt werden, z. B. im Kundenservice, im Gesundheitswesen und in der Bildung. Chatbots, die von ChatGPT unterstützt werden, können mit Kunden, Patienten oder Studenten in natürlicher Sprache interagieren und personalisierte Antworten geben, wodurch die Qualität der Kommunikation verbessert und die Arbeitsbelastung der menschlichen Mitarbeiter verringert wird.
- Verbesserte Barrierefreiheit: ChatGPT kann auch die Zugänglichkeit für Menschen mit Behinderungen verbessern, z. B. für Sehbehinderte oder Menschen mit motorischen Einschränkungen. Es kann zum Beispiel Textbeschreibungen von Bildern oder Videos generieren oder Text in Sprache umwandeln für Menschen mit Leseschwierigkeiten.
- Verbesserung des Wissensmanagements: Es kann zur Automatisierung von Wissensmanagementaufgaben wie der Erstellung von Inhalten, der Zusammenfassung und der Organisation eingesetzt werden. Sie kann dazu verwendet werden, lange Dokumente zusammenzufassen, Schlüsselinformationen zu extrahieren und prägnante Berichte oder Artikel zu erstellen, was die Effizienz und Produktivität in verschiedenen Branchen verbessert.
- Förderung von Forschung und Entwicklung: ChatGPT kann auch verwendet werden, um Forschung und Entwicklung in verschiedenen Bereichen voranzutreiben. Zum Beispiel kann es große Mengen an Textdaten generieren und analysieren und so die Geschwindigkeit und Genauigkeit von Aufgaben der natürlichen Sprachverarbeitung wie Stimmungsanalyse oder Sprachübersetzung verbessern.
Insgesamt hat ChatGPT das Potenzial, unsere Welt zu verändern, indem es die Kommunikation revolutioniert, die Zugänglichkeit erhöht, das Wissensmanagement verbessert und die Forschung und Entwicklung in verschiedenen Branchen vorantreibt. Da sich die Technologie weiter entwickelt und fortschrittlicher wird, können wir in Zukunft noch mehr innovative Anwendungen und Anwendungsfälle für ChatGPT erwarten.
Das solltest Du mitnehmen
- Der Generative Pretrained Transformer, kurz GPT-3, ist ein Modell von OpenAI, welches im Bereich des Natural Language Processings eingesetzt wird.
- Es kann unter anderem dazu genutzt werden, natürliche Sprache in Programmiercode umzuwandeln, inhaltstreue Zusammenfassungen von Texten zu erstellen oder ein Frage-Antwort System aufzubauen.
- Obwohl die Fortschritte in diesem Bereich erstaunlich sind, ist die Output Größe von 2048 Tokens oder etwa 1.500 Wörtern aktuell noch eine große Schwäche.
- Das GPT-3 Modell wurde bis vor kurzem noch in der Anwendung ChatGPT genutzt, die mittlerweile auf GPT-4 verbessert wurde.

Was ist Datenschutz?
Erforschen Sie das Wesen des Datenschutzes: Entdecken Sie Vorschriften, bewährte Praktiken und die personenbezogenen Daten.

Wie kann man eine Website erstellen, ohne einen Developer zu beauftragen?
Um eine neue Website aufzubauen, war es früher meistens notwendig, einen externen Dienstleister zu buchen. Web Developer gibt es auch heute noch. Allerdings müssen Sie dafür viel Geld bezahlen. Deshalb ist es schön, dass es auch kostenlose Möglichkeiten gibt. Hier erfahren Sie, welche das sind und wie Sie davon profitieren. Was ist ein Web Developer? Es handelt sich… Weiterlesen »Wie kann man eine Website erstellen, ohne einen Developer zu beauftragen?

Was ist Wissensrepräsentation in der KI?
Erforschen Sie die Wissensrepräsentation in der KI: Erfahren Sie, wie Maschinen Wissen speichern und verarbeiten.

Wie Daten unseren Alltag formen – von Netflix bisGoogle Maps
Daten sind längst kein abstraktes Konzept mehr, das nur in Rechenzentren oder bei IT-Teams eine Rolle spielt. Sie begegnen uns ständig – oft, ohne dass wir es merken. Vom nächsten Film, den uns Netflix vorschlägt, bis zur Stauwarnung auf dem Weg zur Arbeit: All das basiert auf Daten. Doch wie genau funktionieren diese Prozesse? Und… Weiterlesen »Wie Daten unseren Alltag formen – von Netflix bisGoogle Maps

Was ist Collaborative Filtering?
Erschließen Sie Empfehlungen mit Collaborative Filtering. Entdecken Sie, wie diese leistungsstarke Technik das Nutzererlebnis verbessert.

Was ist Quantencomputing?
Tauchen Sie ein in das Quantencomputing. Entdecken Sie die Zukunft des Rechnens und sein transformatives Potenzial.
Andere Beiträge zum Thema GPT-3
- Über die OpenAI API steht das GPT-3 Modell frei zur Verfügung und kann für eigene Anwendungen genutzt werden.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.