AdaBoost ist die Abkürzung für Adaptive Boosting und ist eine Methode aus dem Bereich des Ensemble Learnings, welche beschreibt, wie man aus mehreren, sogenannten schwachen Lernern ein starkes Modell mit guten Ergebnissen formen kann.
Was ist Ensemble Learning und Boosting im Machine Learning?
Im Machine Learning kommen nicht immer nur einzelne Modelle zum Einsatz. Um die Leistung des gesamten Programms zu verbessern, werden teilweise auch mehrere einzelne Modelle zu einem sogenannten Ensemble zusammengefasst. Ein Random Forest beispielsweise besteht aus vielen, einzelnen Decision Trees, deren Ergebnisse dann zu einem Resultat vereint werden. Die Grundidee dahinter ist die sogenannte “Wisdom of Crowds“, die besagt, dass der Erwartungswert von mehreren unabhängigen Schätzungen besser ist, als jede einzelne Schätzung. Diese Theorie wurde formuliert, nachdem auf einer mittelalterlichen Messe das Gewicht eines Ochsen von keiner Einzelperson so genau geschätzt wurde, wie vom Durchschnitt der Einzelschätzungen.
Das Boosting beschreibt die Vorgehensweise wie mehrere Modelle zu einem Ensemble zusammengefasst werden. Am Beispiel von Decision Trees, werden die Trainingsdaten genutzt, um einen Baum zu trainieren. Für alle die Daten, für die der erste Decision Tree schlechte oder falsche Ergebnisse liefert, wird ein zweiter Decision Tree gebildet. Dieser wird dann ausschließlich mit den Daten trainiert, die der erste falsch klassifiziert hat. Diese Kette wird weitergeführt und der nächste Baum wiederum nutzt die Informationen, die bei den ersten beiden Bäumen zu schlechten Ergebnissen geführt haben.
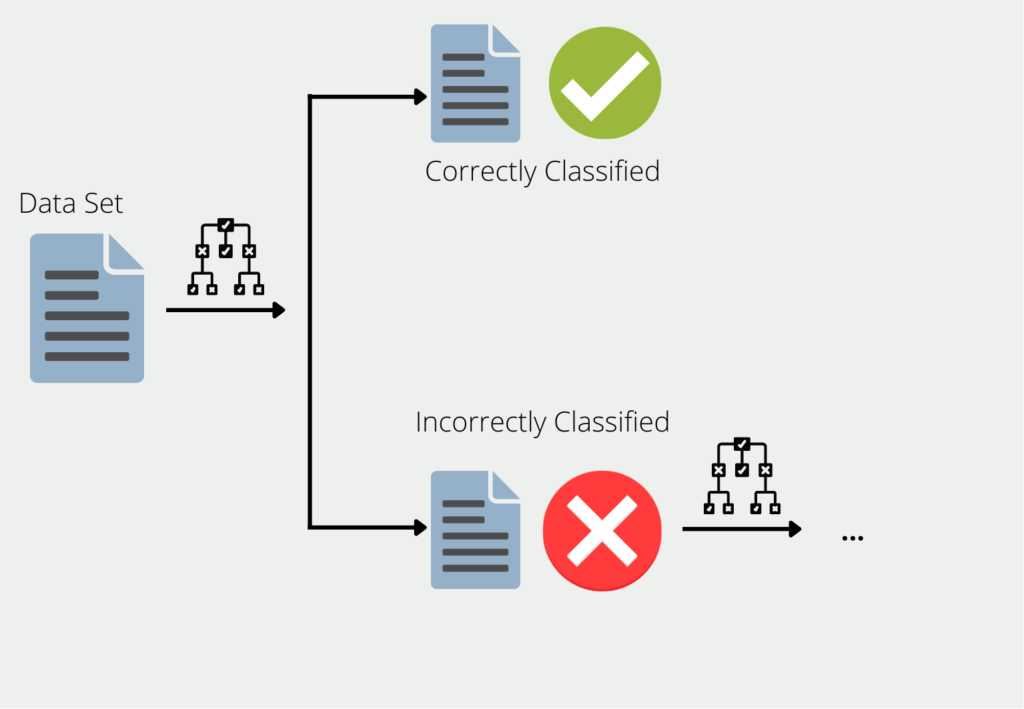
Das Ensemble aus all diesen Decision Trees kann dann für den gesamten Datensatz gute Ergebnisse liefern, da jedes einzelne Modell die Schwächen der anderen kompensiert. Man spricht auch davon, dass viele “schwache Lerner” (english: weak learners) zu einem “starken Lerner” (english: “strong learner”) zusammengefasst werden.
Man spricht von schwachen Lernern, da diese in vielen Fällen nur eher schlechte Ergebnisse liefern. Ihre Genauigkeit ist in vielen Fällen zwar besser als einfaches Raten, aber auch nicht deutlich besser. Sie bieten jedoch den Vorteil, dass sie meist einfach zu berechnen sind und dadurch sich einfach und kostengünstig kombinieren lassen.
Was ist AdaBoost?
Das Adaptive Boosting, oder kurz AdaBoost, beschreibt eine Versuchsanordnung, bei der mehrere schwache Lernmodelle trainiert und anschließend zu einem starken Modell kombiniert werden. Als Grundlage wird dafür eine spezielle Form der Entscheidungsbäume genutzt, die sogenannten Decision Stumps, also Bäume, die lediglich eine einzige Verzweigung haben, statt mehrere Ebenen. Am Ende werden die Vorhersagen von vielen dieser Stümpfe zu einem Ergebnis kombiniert.

Wie funktioniert der AdaBoost Algorithmus?
Angenommen es soll ein Modell trainiert werden, das klassifizieren kann, ob eine Person mehr oder weniger als das durchschnittliche Gehalt in dem jeweiligen Land verdient. Dazu wird ein Datensatz mit 20 verschiedenen Personen verwendet, für die insgesamt drei Merkmale bekannt sind, nämlich Alter, Anzahl der Arbeitsstunden pro Woche und ob es eine Bürotätigkeit ist oder nicht. Das Training eines Adaptive Boosting Algorithmus könnte in diesem Beispiel wie folgt aussehen:
- Schritt 1: Da der Algorithmus lediglich mit Decision Stumps arbeitet wird als erstes für jedes Eingabefeature ein eigener Decision Tree mit einer Ebene trainiert. Dabei ist wichtig, dass alle Eingabeparameter als binäres Merkmal zur Verfügung gestellt werden. In dem genannten Beispiel sind jedoch Alter und Anzahl der Wochenarbeitsstunden numerische Werte. Deshalb müssen verschiedene Grenzen eingeführt werden, um daraus ein binäres Merkmal zu machen, wie zum Beispiel „Wochenarbeitsstunden < 20 h“. Somit können im ersten Schritt nicht nur drei Decision Stumps für jedes Feature gebildet werden, sondern auch noch verschiedene Stumps mit unterschiedlichen Schwellenwerten.
- Schritt 2: Nachdem die ersten schwachen Lerner trainiert wurden, wird das Modell gewählt, das am besten die Zielvariable vorhersagen konnte. Um dies zu messen, wird die sogenannte Gini Impurity genutzt. Das Modell mit der niedrigsten Gini Impurity wird gewählt. Nach dem Training könnte sich dann beispielsweise herausstellen, dass die Anzahl der Wochenarbeitsstunden ein guter erster Klassifikator ist, denn in 16 der 20 Fälle wurde korrekterweise vorhergesagt, dass die Personen weniger als das Durchschnittsgehalt verdienen, wenn sie weniger als 20 Stunden in der Woche arbeiten. Lediglich vier Personen haben mehr als das Durchschnittsgehalt verdient, obwohl sie weniger als 20 Stunden in der Woche arbeiten. Somit ergibt sich eine Fehlerrate des ersten Modells von 4/20 = 0,2.
- Schritt 3: Die Vorhersage eines Adaptive Boosting Algorithmus setzt sich aus den gewichteten Vorhersagen der Einzelmodelle zusammen. Nachdem nun das erste Modell trainiert wurde, muss deshalb noch die Gewichtung bestimmt werden, mit dem es zum Endresultat beiträgt. Dabei gilt der Grundsatz, dass umso geringer der Fehler eines Modells, umso mehr sollte dessen Vorhersage zum endgültigen Ergebnis beitragen. Um diesen Wert zu berechnen wird die folgende Formel genutzt, wobei e für die Fehlerrate des Modells steht und \( \alpha \) für die Gewichtung:

- Schritt 4: Mit der Berechnung der Vorhersagegewichtung ist das Training des ersten schwachen Lerners abgeschlossen. Bevor jedoch mit einem neuen Decision Stump gestartet werden kann, wird der Datensatz neu gewichtet, damit sich das nachfolgende Modell vor allem auf die Datenpunkte fokussiert, die das erste Modell falsch klassifiziert hatte. Hierfür wird für jeden Datenpunkt eine Gewichtung festgelegt, die davon abhängt, ob der Punkt vom ersten Modell richtig oder falsch klassifiziert wurde. Im ersten Schritt waren alle Datenpunkte im Datensatz gleich gewichtet mit 1/20 (also eins geteilt durch die Größe des Datensatzes). Diese Größe wird nun mithilfe der folgenden Formel angepasst:
\(\)\[ \alpha = \frac{1}{2} \cdot \log{\left( \frac{1 – \varepsilon}{\varepsilon} \right)} = \frac{1}{2} \cdot \log{\left( \frac{1 – 0.2}{0.2} \right)} = 0.301
\]
Durch das ± ergeben sich daraus zwei Formeln, nämlich eine, wenn der Datenpunkt zuvor richtig klassifiziert wurde und deshalb das negative Alpha verwendet wird und der zweite Fall, wenn der Datenpunkt falsch klassifiziert wurde und deshalb das positive Alpha genutzt wird. Die Euler’sche Funktion stellt sicher, dass die alte Gewichtung vergrößert wird, wenn es zu einer falschen Klassifikation kam.
- Schritt 5: Nachdem nun der Datensatz neu gewichtet wurde, kann das Training des zweiten Modells beginnen. Dazu wird, wie in Schritt 1, wieder ein Entscheidungsstumpf für jedes Feature mit dem neuen Datensatz trainiert und anschließend das Modell behalten, welches die geringste Gini Impurity aufweist. Anschließend wiederholen sich die Schritte 2 – 4.
Dieser Vorgang wird so lange wiederholt, bis die maximale Anzahl an Trainingsiterationen oder eine festgelegte Leistungszielmarke erreicht wurde. Nun stellt sich jedoch noch die Frage, welche Vorhersage das Ensemble an schwachen Lernern trifft für einen spezifischen Datenpunkt.
Für eine Vorhersage wird das Ergebnis aller Entscheidungsstümpfe errechnet und mit ihrem jeweiligen Gewicht multipliziert. Anschließend werden die Werte für eine positive Klassifikation und für eine negative Klassifikation getrennt zusammengerechnet. Der jeweils größere Wert bestimmt dann über die endgültige Vorhersage des Ensemble Modells.
Was sind die Vor- und Nachteile von AdaBoost?
AdaBoost ist ein leistungsfähiges Modell, welches es ermöglicht, auch schwache Lerner für komplexere Aufgaben einzusetzen und daraus ein leistungsstarkes Modell zu bauen. Es kann relativ einfach genutzt werden. Durch das iterative Training der Modelle erhöht sich die Genauigkeit der Vorhersage und nachfolgende Modelle können besser auf die vorher gemachten Fehler eingehen.
Zusätzlich erfordert AdaBoost nur wenig Arbeit beim Hyperparameter Tuning, da es wenige Hyperparameter gibt und sich das Modell durch das sequenzielle Training und die Gewichtung der Fehler von selbst bereits gut an den Datensatz anpasst.
Zwar kann es auch bei AdaBoost Modellen zu Overfitting kommen, jedoch ist das Risiko für Overfitting deutlich geringer im Vergleich zu einzelnen Entscheidungsbäume. Vor allem die Entscheidungsstümpfe sind sehr einfache Modelle, die deshalb nicht sehr zum Overfitting tendieren, wie komplexere Entscheidungsbäume. Jedoch kann es vor allem bei Datensätzen mit Ausreißern oder Rauschen zu einem erhöhten Risiko für Overfitting kommen. In solchen Fällen sollte auf die angepassten Modellarchitekturen mit Regularisierungstechniken zurückgegriffen werden.
Ein weiterer Nachteil von AdaBoost ist darüber hinaus, dass es möglicherweise mehr Zeit in Anspruch nimmt als das Training eines einzelnen, komplexeren Modells. Außerdem ist es im Vergleich zu anderen Boosting Modellen, wie zum Beispiel XGBoost, langsamer. Durch die sequenzielle Natur ist es außerdem nicht möglich auf die Vorteile von Parallelisierung zurückzugreifen, wodurch es sich bei großen Datensätzen nicht oder nur sehr schwierig skalieren lässt.
Random Forest vs. AdaBoost
Der Random Forest nutzt zwar auch viele Decision Trees, wie AdaBoost, jedoch mit dem Unterschied, dass diese alle dieselben Trainingsdaten bekommen und auch dasselbe Gewicht in der schlussendlichen Vorhersage. Außerdem können die Bäume viele Entscheidungspfade enthalten und sind nicht wie bei AdaBoost lediglich auf eine Stufe limitiert. Zusätzlich wird bei AdaBoost die Gewichtungen einzelner Datenpunkte geändert, wenn diese vom vorherigen Modell nicht richtig klassifiziert wurden. Dadurch werden die einzelnen “Decision Stumps” auf leicht unterschiedlichen Datensätzen trainiert, anders als beim Random Forest.
Diese kleinen Änderungen an der Architektur haben in der Praxis jedoch mitunter große Auswirkungen:
- Trainingsgeschwindigkeit: Dadurch, dass die Decision Trees im Random Forest unabhängig voneinander sind, lässt sich das Training der Bäume parallelisieren und auf verschiedene Server verteilen. Dadurch verringert sich die Trainingszeit. Der AdaBoost Algorithmus hingegen kann aufgrund der sequenziellen Anordnung nicht parallelisiert werden, da der nächste Decision Stump erst trainiert werden kann, wenn der vorherige abgeschlossen wurde.
- Vorhersageschwindigkeit: Wenn es dann jedoch in die tatsächliche Anwendung geht, also wenn die Modelle austrainiert sind und neue Daten klassifizieren sollen, dreht sich das ganze um. Das heißt, für Inference ist AdaBoost schneller als Random Forest, da die Vorhersagen in ausgewachsenen Bäume, und das auch noch in der Vielzahl, deutlich mehr Zeit in Anspruch nehmen als bei AdaBoost.
- Overfitting: Der Decision Stump im AdaBoost, der wenige Fehler produziert, hat eine hohe Gewichtung für die schlussendliche Vorhersage, während ein anderer Stump, der viele Fehler produziert nur wenig Aussagekraft hat. Beim Random Forest hingegen ist die Aussagekraft aller Bäume identisch, unabhängig davon, wie gut oder schlecht deren Ergebnisse waren. Somit ist die Chance von Overfitting bei Random Forest deutlich geringer als bei einem AdaBoost Modell.
Gradient Boosting vs. AdaBoost
Bei AdaBoost werden viele verschiedene Decision Trees mit nur einer Entscheidungsebene, also sogenannte Decision Stumps, sequenziell mit den Fehlern der vorherigen Modelle trainiert. Beim Gradient Boosting hingegen wird versucht durch die sequenzielle Anordnung die Verlustfunktion immer weiter zu minimieren, indem nachfolgenden Modelle darauf trainiert werden das sogenannte Residual, also die Differenz zwischen Vorhersage und dem tatsächlichen Wert, weiter zu verringern.
Dadurch lassen sich mit dem Gradient Boosting Regressionen, also die Vorhersage von stetigen Werten, als auch Klassifikationen, also die Einordnung in Gruppen, vornehmen. Der AdaBoost Algorithmus hingegen kann nur für Klassifizierungen genutzt werden. Dies ist tatsächlich auch der Hauptunterschied zwischen diesen beiden Boosting Algorithmen, denn im Kerngedanken versuchen beide durch sequenzielles Lernen und die höhere Gewichtung von falschen Vorhersagen, schwache Lerner zu einem starken Modell zu kombinieren.
Wie kann man AdaBoost bei verzerrten Daten nutzen?
In vielen Klassifizierungsfällen kann es vorkommen, dass die vorherzusagenden Klassen nicht gleich verteilt sind, also dass ein Datensatz zum Beispiel weniger Menschen enthält, die an einer Krankheit leiden als gesunde Menschen. Solche unausgeglichenen Datensätze sind problematisch, da sie dazu führen können, dass sich ein Modell auf die häufigere Klasse konzentriert und dieser mehr Gewicht zuweist und dabei die seltenere Klasse vernachlässigt. Dies führt meist zu einer unzureichenden Modellleistung und zu fehlerhaften Vorhersagen.
Jedoch lässt sich in der Realität eine Ungleichverteilung der Klassen häufig nicht verhindern, da die Klassen in der Praxis nicht im gleichen Verhältnis auftreten. Vor allem in den Bereichen Medizin, Finanzen oder Gesichtserkennung stellen solche Datensätze ein großes Problem dar. Es lässt sich beispielsweise dadurch lösen, dass man auf das sogenannte Oversampling zurückgreift und leicht abgeänderte Varianten der unterrepräsentierten Klasse dem Datensatz hinzufügt, um so ein Gleichgewicht herzustellen. Dieselbe Logik wird beim Undersampling genutzt mit dem Unterschied, dass Datenpunkte aus der überrepräsentierten Klasse entfernt werden, was jedoch zu einer teilweise deutlichen Reduzierung der Datensatzgröße führen kann.
Auch die AdaBoost Modellarchitektur hat in ihrer Grundform Probleme mit unausgewogenen Datensätzen, da sie versucht die Genauigkeit zu maximieren. Dabei werden die Datenpunkte höher gewichtet, die falsch klassifiziert werden und die einen großen Einfluss auf eine maximale Genauigkeit des Modells haben. Somit spielt es dabei keine Rolle, ob es sich um eine unterrepräsentierte Klasse handelt oder nicht. Um diesem Problem entgegenzutreten haben sich verschiedene Modellarchitekturen von AdaBoost entwickelt, die speziell auf die Problematik bei unausgeglichenen Datensätzen eingehen.
Dabei wird zum Beispiel eine sogenante Kostenmatrix eingeführt, die die unterschiedlichen Kosten von Misklassifikationen in das Training mit einbezieht. Dadurch kann beispielsweise in einer medizinischen Anwendung der Fall eines fälschlicherweise negativ klassifizierten Patienten deutlich schlechter gewertet werden als die falsche Vorhersage eines positiven Patienten.
Durch diese Herangehensweise wird das Modell darauf trainiert, möglichst Fehler zu vermeiden, denen hohe Kosten zugewiesen sind, egal ob sie zur größeren oder kleineren Klasse gehören.
Wie kann man den AdaBoost Algorithmus in Python umsetzen?
AdaBoost kann einfach in Python mithilfe von verschiedenen Bibliotheken genutzt werden. Eine Möglichkeit dafür ist Scikit-Learn, welche den Algorithmus bereits als Funktion hinterlegt hat und somit einfach importiert werden kann. In diesem Abschnitt schauen wir uns ein allgemeines Beispiel an, in dem wir einfaches Modell mithilfe des IRIS Datensatzes trainineren.
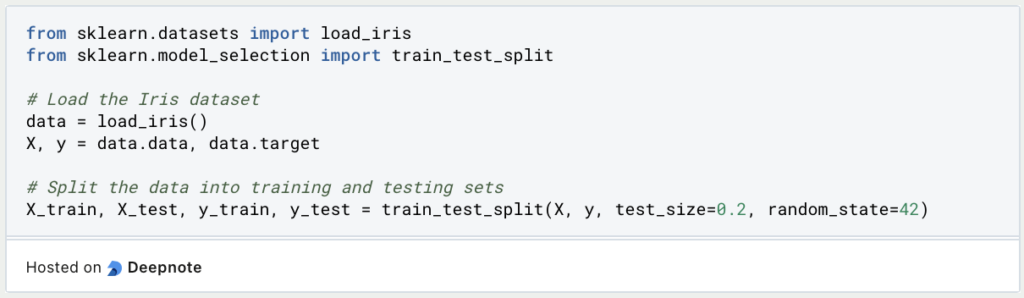
Schritt 1: Datenvorbereitung
Im ersten Schritt müssen wir die Daten so aufbereiten, dass sie für eine Klassifizierung genutzt werden können. Dazu splitten wir die vorherzusagende Variable ab, mit der wir später die Ergebnisse kontrollieren können. Außerdem teilen wir den Datensatz in die Trainings- und Testmenge auf, um später unbenutzte Daten für die Evaluierung des Modells nutzen zu können.
Schritt 2: Importieren und Initialisieren des AdaBoost-Klassifikators
Nachdem die Daten bereit sind, können wir nun das Klassifizierungsmodell aufsetzen. Dazu importieren wir sowohl den AdaBoost Classifier, als auch den Decision Tree Classifier, den wir als schwachen Lerner nutzen. Da es sich um einen Entscheidungsstumpf handelt, setzen wir die maximale Tiefe des Baum auf 1.

Schritt 3: Modelltraining und Auswertung
Unter Verwendung des Trainingsdatensatzes können wir nun den Klassifikator trainieren und anschließend die Genauigkeit des Modells mithilfe des Testdatensatzes unahängig bewerten.

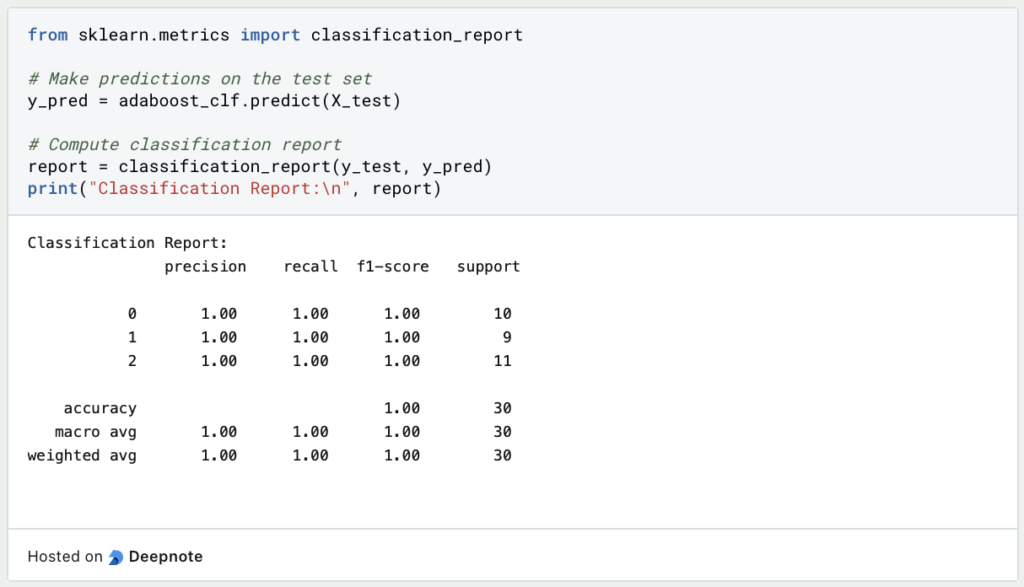
Schritt 4: Vorhersagen und Leistungsmetriken
Das fertige Modell kann schließlich dafür verwendet werden, um neue Daten zu klassifizieren. Außerdem können wir verschiedene Kennzahlen, wie die Präzision, den Recall oder den F1-Score berechnen, um die Leistungsfähigkeit bewerten zu können.
Schritt 5: Feinabstimmung des Modells (optional)
Falls die Genauigkeit des Modells noch nicht ausreichend ist, kann es nochmals mit neu abgestimmten Hyperparametern trainiert werden, um bessere Ergebnisse zu erzielen. Dazu können im Classifier verschiedene Argumente, wie zum Beispiel die Anzahl der Estimators bestimmt werden. Weitere Möglichkeiten bestehen auch darin, die Lernrate zu definieren.

Mithilfe von dieser kurzen Anleitung lassen sich bereits leistungsstarke Modelle trainieren, die für reale Anwedungen genutzt werden können. Abhängig vom Datensatz müssen die einzelnen Schritte möglicherweise noch etwas angepasst oder ausgebaut werden.
Das solltest Du mitnehmen
- AdaBoost ist die Abkürzung für Adaptive Boosting und ist eine Methode aus dem Bereich des Ensemble Learnings, welche beschreibt, wie man aus mehreren sogenannten schwachen Lernern ein starkes Modell mit guten Ergebnissen formen kann.
- Das Boosting bezeichnet allgemein die Vorgehensweise wie die verschiedenen Modelle im Ensemble Learning miteinander verknüpft werden.
- Im Kern werden dazu Decision Trees genutzt, die sequenziell trainiert werden. Das bedeutet, dass ein Baum immer mit denselben Daten wie der vorherige trainiert wird, mit dem Unterschied, dass die falsch vorhergesagten Datenpunkte des vorangegangenen Modells nun höher gewichtet werden.
- Die Vorgehensweise von AdaBoost ist zwar ähnlich zu der des Random Forest, hat jedoch die Hauptunterschiede, dass die Bäume lediglich eine Verzweigung haben und nicht parallel, sondern sequenziell, also Hintereinander, trainiert werden müssen.
- Die Hauptvorteile bei der Verwendung von AdaBoost liegen darin, dass das Risiko für Overfitting deutlich geringer als bei anderen Modellen ist und es außerdem nur wenige Hyperparameter gibt, die feinabgestimmt werden müssen.
- AdaBoost bietet verschiedene Möglichkeiten mit verzerrten Datensätzen umzugehen.

Was ist der Conjugate Gradient?
Erforschen Sie den Conjugate Gradient: Algorithmusbeschreibung, Varianten, Anwendungen und Grenzen.

Was ist ein Elastic Net?
Entdecken Sie Elastic Net: Die vielseitige Regularisierungstechnik beim Machine Learning für bessere Modellbalance und Vorhersagen.

Was ist Adversarial Training?
Sicheres maschinelles Lernen: Erklärung von Adversarial Training, dessen Anwendungen und Probleme.

Was sind Echo State Networks?
Verstehen Sie Echo State Networks: Dynamic Time-Series Modeling, Applikationen und wie man sie in Python implementiert.

Was sind Faktorgraphen?
Entdecken Sie die Vielseitigkeit von Faktorgraphen bei der grafischen Modellierung und bei praktischen Anwendungen.

Was ist Unsupervised Domain Adaptation?
Beherrschen Sie die Unsupervised Domain Adaptation: Überbrücken Sie die Lücke zwischen Quell- und Zieldomänen für Lernmodelle.
Andere Beiträge zum Thema AdaBoost
Die Scikit-Learn Dokumentation zu AdaBoost findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.