AdaBoost is the abbreviation for Adaptive Boosting and is a method from the field of Ensemble Learning, which describes how to form a strong model with good results from several, so-called weak learners.
What is Ensemble Learning and Boosting in Machine Learning?
In machine learning, it is not always just individual models that are used. To improve the performance of the entire program, several individual models are sometimes combined to form an ensemble. A random forest, for example, consists of many individual decision trees, the results of which are then combined into one result. The basic idea behind this is the so-called “wisdom of crowds”, which states that the expected value of several independent estimates is better than each estimate. This theory was formulated after the weight of an ox at a medieval fair was not estimated as accurately by any single person as by the average of the individual estimates.
Boosting describes the procedure for combining several models into an ensemble. Using the example of decision trees, the training data is used to train a tree. A second decision tree is formed for all the data for which the first decision tree delivers poor or incorrect results. This is then trained exclusively with the data that the first one classified incorrectly. This chain is continued and the next tree in turn uses the information that led to poor results in the first two trees.
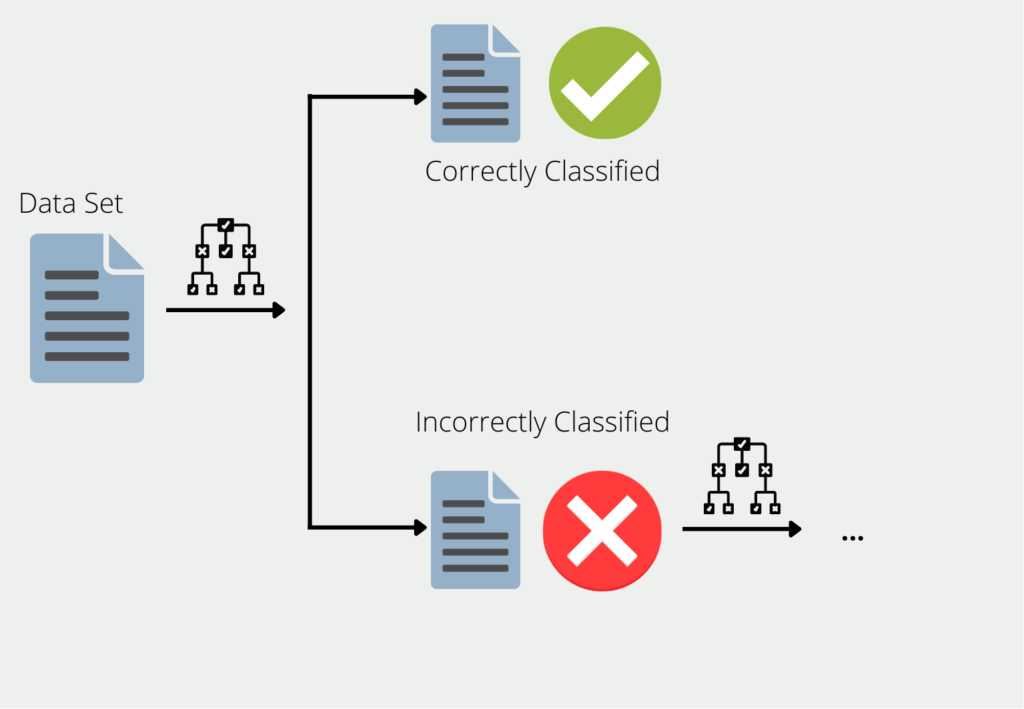
The ensemble of all these decision trees can then deliver good results for the entire data set, as each model compensates for the weaknesses of the others. It is also said that many “weak learners” are combined to form a “strong learner”.
We speak of weak learners because in many cases they only deliver rather poor results. In many cases, their accuracy is better than simple guessing, but not significantly better. However, they offer the advantage that they are usually easy to calculate and can therefore be combined easily and cost-effectively.
What is AdaBoost?
Adaptive boosting, or AdaBoost for short, describes an experimental setup in which several weak learning models are trained and then combined to form a strong model. A special form of decision tree is used as the basis for this, the so-called decision stumps, i.e. trees that only have a single branch instead of several levels. In the end, the predictions of many of these stumps are combined into one result.

How does the AdaBoost algorithm work?
Suppose a model is to be trained that can classify whether a person earns more or less than the average salary in the respective country. For this purpose, a data set with 20 different people is used, for which a total of three characteristics are known, namely age, number of working hours per week, and whether it is an office job or not. In this example, the training of an adaptive boosting algorithm could look as follows:
- Step 1: As the algorithm only works with decision stumps, the first step is to train a separate decision tree with one level for each input feature. All input parameters must be provided as binary features. In the above example, however, age and number of hours worked per week are numerical values. Therefore, various limits must be introduced to turn them into a binary feature, such as “weekly working hours < 20 h”. This means that not only three decision stumps can be created for each feature in the first step, but also different stumps with different threshold values.
- Step 2: After the first weak learners have been trained, the model that best predicts the target variable is selected. Gini impurity is used to measure this. The model with the lowest Gini impurity is selected. After training, it could then turn out, for example, that the number of hours worked per week is a good first classifier because, in 16 of the 20 cases, it was correctly predicted that people earn less than the average salary if they work less than 20 hours per week. Only four people earned more than the average salary even though they worked less than 20 hours a week. This results in an error rate of the first model of 4/20 = 0.2.
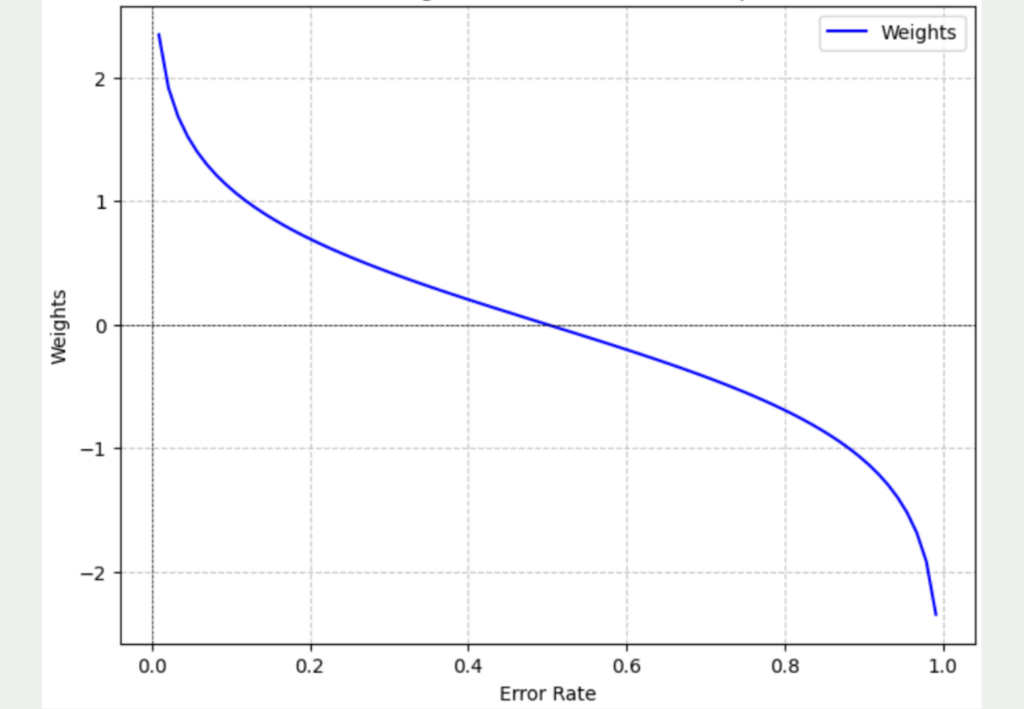
- Step 3: The prediction of an adaptive boosting algorithm is made up of the weighted predictions of the individual models. Once the first model has been trained, the weighting with which it contributes to the final result must be determined. The principle here is that the lower the error of a model, the more its prediction should contribute to the final result. To calculate this value, the following formula is used, where e stands for the error rate of the model and \( \alpha \) for the weighting:
- Step 4: With the calculation of the prediction weighting, the training of the first weak learner is complete. However, before a new decision stump can be started, the data set is reweighted so that the subsequent model focuses primarily on the data points that the first model classified incorrectly. For this purpose, a weighting is defined for each data point, which depends on whether the point was correctly or incorrectly classified by the first model. In the first step, all data points in the data set were weighted equally at 1/20 (i.e. one divided by the size of the data set). This value is now adjusted using the following formula:
\(\)\[ \alpha = \frac{1}{2} \cdot \log{\left( \frac{1 – \varepsilon}{\varepsilon} \right)} = \frac{1}{2} \cdot \log{\left( \frac{1 – 0.2}{0.2} \right)} = 0.301
\]
The ± results in two formulas, one if the data point was previously classified correctly and therefore the negative alpha is used and the second case if the data point was classified incorrectly and therefore the positive alpha is used. The Euler function ensures that the old weighting is increased if an incorrect classification is made.
- Step 5: Now that the data set has been reweighted, the training of the second model can begin. As in step 1, a decision stump is trained for each feature with the new data set and then the model with the lowest Gini impurity is retained. Steps 2 – 4 are then repeated.
This process is repeated until the maximum number of training iterations or a defined performance target has been reached. However, the question now arises as to what prediction the ensemble of weak learners makes for a specific data point.
For a prediction, the result of all decision stumps is calculated and multiplied by their respective weights. The values for a positive classification and a negative classification are then added together separately. The larger value in each case then determines the endgültige Vorhersage des Ensemble Modells.
What are the advantages and disadvantages of AdaBoost?
AdaBoost is a powerful model that makes it possible to use weak learners for more complex tasks and to build a powerful model from them. It is relatively easy to use. The iterative training of the models increases the accuracy of the prediction and subsequent models can respond better to the errors made previously.
In addition, AdaBoost requires little work for hyperparameter tuning, as there are few hyperparameters and the model adapts itself well to the data set due to the sequential training and the weighting of the errors.
Although overfitting can also occur with AdaBoost models, the risk of overfitting is significantly lower compared to individual decision trees. The decision stumps in particular are very simple models, which are therefore less prone to overfitting than more complex decision trees. However, there may be an increased risk of overfitting, especially for data sets with outliers or noise. In such cases, the adapted model architectures with regularization techniques should be used.
Another disadvantage of AdaBoost is that it may take more time than training a single, more complex model. It is also slower compared to other boosting models, such as XGBoost. Due to its sequential nature, it is also not possible to take advantage of parallelization, making it difficult or impossible to scale with large data sets.
Random Forest vs. AdaBoost
The Random Forest also uses many decision trees, like AdaBoost, but with the difference that they all receive the same training data and also the same weight in the final prediction. In addition, the trees can contain many decision paths and are not limited to just one level as with AdaBoost. In addition, AdaBoost changes the weights of individual data points if they were not correctly classified by the previous model. This means that the individual “decision stumps” are trained on slightly different data sets, unlike the random forest.
However, these small changes to the architecture sometimes have a major impact in practice:
- Training speed: Because the decision trees in the random forest are independent of each other, the training of the trees can be parallelized and distributed to different servers. This reduces the training time. The AdaBoost algorithm, on the other hand, cannot be parallelized due to the sequential arrangement, as the next decision stump can only be trained once the previous one has been completed.
- Prediction speed: However, when it comes to the actual application, i.e. when the models are trained and new data is to be classified, the whole process is reversed. This means that AdaBoost is faster than Random Forest for inference, as the predictions in full-grown trees, and in large numbers at that, take significantly longer than with AdaBoost.
- Overfitting: The decision stump in AdaBoost, which produces few errors, has a high weighting for the final prediction, while another stump, which produces many errors, has little significance. With the Random Forest, on the other hand, the significance of all trees is identical, regardless of how good or bad their results were. This means that the chance of overfitting is significantly lower with Random Forest than with an AdaBoost model.
Gradient Boosting vs. AdaBoost
With AdaBoost, many different decision trees with only one decision level, so-called decision stumps, are trained sequentially with the errors of the previous models. Gradient boosting, on the other hand, attempts to minimize the loss function further and further through the sequential arrangement by training subsequent models to further reduce the so-called residual, i.e. the difference between the prediction and the actual value.
This means that gradient boosting can be used to perform regressions, i.e. the prediction of continuous values, as well as classifications, i.e. categorization into groups. The AdaBoost algorithm, on the other hand, can only be used for classifications. This is also the main difference between these two boosting algorithms because the core idea is that both try to combine weak learners into a strong model through sequential learning and the higher weighting of incorrect predictions.
How can AdaBoost be used with distorted data?
In many classification cases, the classes to be predicted may not be equally distributed, for example, a dataset may contain fewer people suffering from a disease than healthy people. Such unbalanced datasets are problematic as they can lead to a model focusing on the more frequent class and assigning more weight to it while neglecting the rarer class. This usually leads to inadequate model performance and incorrect predictions.
In reality, however, it is often impossible to prevent an uneven distribution of classes, as the classes do not occur in equal proportions in practice. Such data sets pose a major problem, particularly in the fields of medicine, finance, or facial recognition. It can be solved, for example, by using oversampling and adding slightly modified variants of the underrepresented class to the data set to create a balance. The same logic is used for undersampling, with the difference that data points are removed from the overrepresented class, which can, however, lead to a significant reduction in the size of the data set.
In its basic form, the AdaBoost model architecture also has problems with unbalanced data sets, as it attempts to maximize accuracy. The data points that are incorrectly classified and have a major influence on the maximum accuracy of the model are weighted higher. Therefore, it does not matter whether the class is underrepresented or not. To counter this problem, AdaBoost has developed various model architectures that specifically address the problem of unbalanced data sets.
For example, a so-called cost matrix is introduced, which includes the different costs of misclassifications in the training. In a medical application, for example, the case of a patient incorrectly classified as negative can be evaluated significantly worse than the incorrect prediction of a positive patient.
This approach trains the model to avoid errors that are assigned high costs, regardless of whether they belong to the larger or smaller class.
How can the AdaBoost algorithm be implemented in Python?
AdaBoost can easily be used in Python with the help of various libraries. One possibility is Scikit-Learn, which already has the algorithm stored as a function and can therefore be easily imported. In this section, we will look at a general example where we train a simple model using the IRIS dataset.
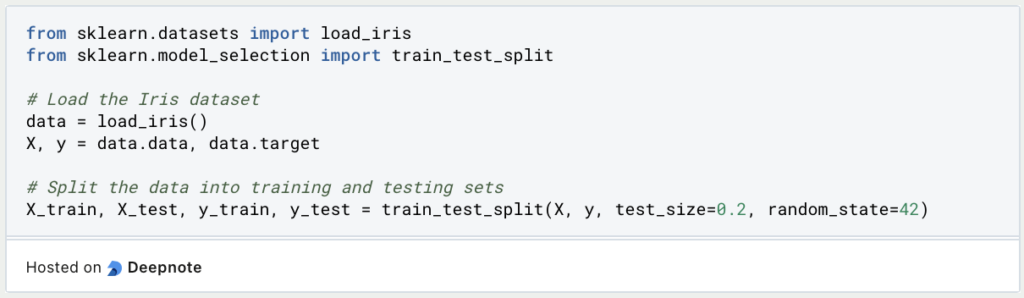
Step 1: Data preparation
The first step is to prepare the data so that it can be used for classification. To do this, we split the variable to be predicted, which we can later use to check the results. We also split the data set into the training and test set so that we can later use unused data to evaluate the model.
Step 2: Importing and initializing the AdaBoost classifier
Now that the data is ready, we can set up the classification model. To do this, we import both the AdaBoost classifier and the decision tree classifier, which we use as a weak learner. As this is a decision stump, we set the maximum depth of the tree to 1.

Step 3: Model training and evaluation
Using the training dataset, we can now train the classifier and then independently evaluate the accuracy of the model using the test dataset.

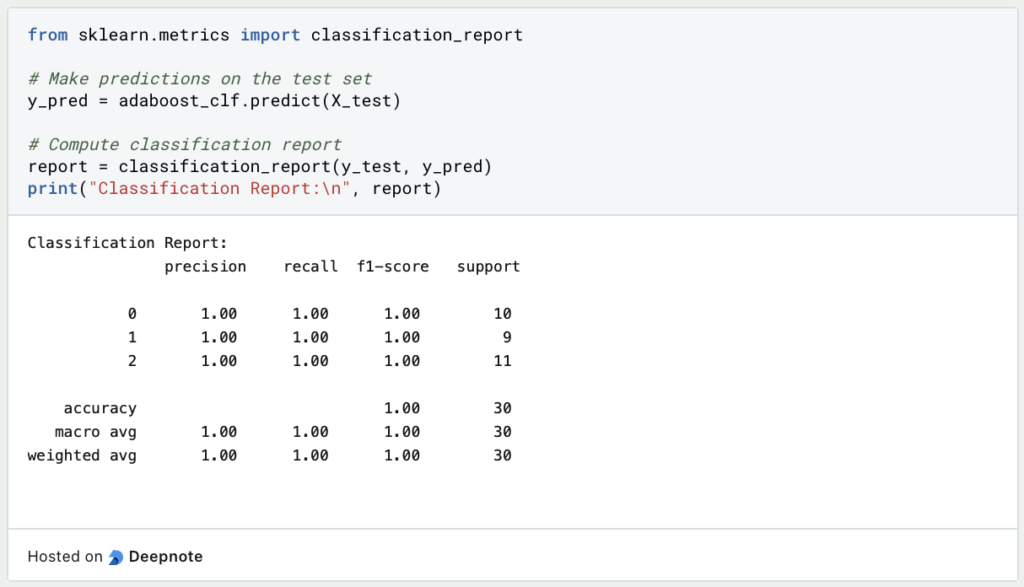
Step 4: Predictions and performance metrics
Finally, the finished model can be used to classify new data. We can also calculate various metrics such as precision, recall, or F1 score to evaluate performance.
Step 5: Fine-tuning the model (optional)
If the accuracy of the model is not yet sufficient, it can be trained again with newly tuned hyperparameters to achieve better results. Various arguments, such as the number of estimators, can be specified in the classifier for this purpose. Other options include defining the learning rate.

These brief instructions can be used to train powerful models that can be used for real applications. Depending on the data set, the individual steps may need to be adapted or expanded slightly.
This is what you should take with you
- AdaBoost is the abbreviation for Adaptive Boosting and is a method from the field of ensemble learning, which describes how to form a strong model with good results from several so-called weak learners.
- Boosting generally refers to the procedure for linking the various models in ensemble learning.
- In essence, decision trees are used for this, which are trained sequentially. This means that a tree is always trained with the same data as the previous one, with the difference that the incorrectly predicted data points of the previous model are now weighted higher.
- Although the AdaBoost approach is similar to that of the Random Forest, the main differences are that the trees only have one branch and do not have to be trained in parallel but sequentially, i.e. one after the other.
- The main advantages of using AdaBoost are that the risk of overfitting is significantly lower than with other models and there are only a few hyperparameters that need to be fine-tuned.
- AdaBoost offers various options for dealing with distorted data sets.

What is a Boltzmann Machine?
Unlocking the Power of Boltzmann Machines: From Theory to Applications in Deep Learning. Explore their role in AI.

What is the Gini Impurity?
Explore Gini impurity: A crucial metric shaping decision trees in machine learning.

What is the Hessian Matrix?
Explore the Hessian matrix: its math, applications in optimization & machine learning, and real-world significance.

What is Early Stopping?
Master the art of Early Stopping: Prevent overfitting, save resources, and optimize your machine learning models.

What is RMSprop?
Master RMSprop optimization for neural networks. Explore RMSprop, math, applications, and hyperparameters in deep learning.

What is the Conjugate Gradient?
Explore Conjugate Gradient: Algorithm Description, Variants, Applications and Limitations.
Other Articles on the Topic of AdaBoost
The Scikit-Learn documentation for AdaBoost can be found here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.