Ensemble Learning ist eine Technik des maschinellen Lernens, bei der die Vorhersagen mehrerer Einzelmodelle kombiniert werden, um die Genauigkeit und Stabilität der Gesamtvorhersage zu verbessern. Die einzelnen Modelle können unterschiedlicher Art sein, z. B. Entscheidungsbäume, neuronale Netze, Support-Vector-Maschinen und andere. Das Ensemble Learning ist in verschiedenen Anwendungen weit verbreitet, z. B. in der Bilderkennung, der Spracherkennung und der Verarbeitung natürlicher Sprache. In diesem Artikel werden wir das Ensemble-Lernen, seine Anwendungen, Vorteile und Nachteile diskutieren.
Was ist Ensemble Learning und Boosting im Machine Learning?
Beim maschinellen Lernen werden nicht nur einzelne Modelle verwendet. Um die Leistung des gesamten Programms zu verbessern, werden manchmal mehrere Einzelmodelle zu einem sogenannten Ensemble kombiniert. Ein Random Forest zum Beispiel besteht aus vielen einzelnen Entscheidungsbäumen, deren Ergebnisse dann zu einem Ergebnis zusammengefasst werden. Der Grundgedanke dahinter ist die sogenannte “Wisdom of Crowds”, die besagt, dass der Erwartungswert mehrerer unabhängiger Schätzungen besser ist als jede einzelne Schätzung. Diese Theorie wurde formuliert, nachdem das Gewicht eines Ochsen auf einem mittelalterlichen Jahrmarkt von einem Einzelnen nicht so genau geschätzt wurde wie vom Durchschnitt der einzelnen Schätzungen.
Boosting beschreibt das Verfahren der Kombination mehrerer Modelle zu einem Ensemble. Am Beispiel von Entscheidungsbäumen werden die Trainingsdaten zum Trainieren eines Baums verwendet. Für alle Daten, für die der erste Entscheidungsbaum schlechte oder falsche Ergebnisse liefert, wird ein zweiter Entscheidungsbaum gebildet. Dieser wird dann nur mit den Daten trainiert, die der erste Baum falsch klassifiziert hat. Diese Kette wird fortgesetzt, und der nächste Baum verwendet die Informationen, die in den ersten beiden Bäumen zu schlechten Ergebnissen geführt haben.
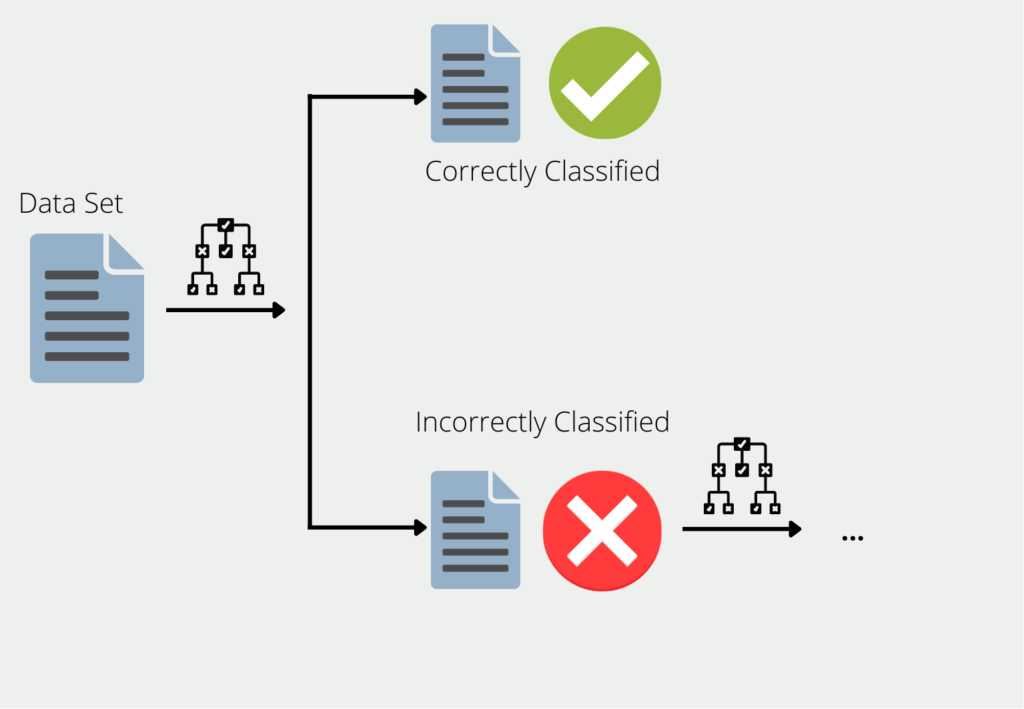
Das Ensemble aus all diesen Entscheidungsbäumen kann dann gute Ergebnisse für den gesamten Datensatz liefern, da jedes einzelne Modell die Schwächen der anderen ausgleicht. Dies wird auch als Kombination vieler “schwacher Lerner” zu einem “starken Lerner” bezeichnet.
Diese werden als “weak learners” bezeichnet, weil sie oft eher schlechte Ergebnisse liefern. Ihre Genauigkeit ist in vielen Fällen besser als einfaches Raten, aber auch nicht wesentlich besser. Sie bieten jedoch den Vorteil, dass sie in vielen Fällen leicht zu berechnen sind und daher einfach und kostengünstig kombiniert werden können.
Wofür wird es verwendet?
Ensemble Learning ist in verschiedenen Anwendungen weit verbreitet, darunter:
- Bilderkennung: Ensemble Learning wird in der Bilderkennung eingesetzt, um die Genauigkeit der Vorhersage zu verbessern. Mehrere Einzelmodelle werden auf verschiedenen Bilddatensätzen trainiert, und ihre Vorhersagen werden kombiniert, um die Gesamtvorhersagegenauigkeit zu verbessern.
- Spracherkennung: Es wird in der Spracherkennung eingesetzt, um die Genauigkeit der Vorhersage zu verbessern. Mehrere individuelle Modelle werden auf verschiedenen Teilmengen der Sprachdaten trainiert, und ihre Vorhersagen werden kombiniert, um die Gesamtvorhersagegenauigkeit zu verbessern.
- Verarbeitung natürlicher Sprache: Ensemble Learning wird bei der Verarbeitung natürlicher Sprache eingesetzt, um die Genauigkeit der Vorhersage zu verbessern. Mehrere Einzelmodelle werden auf verschiedenen Teilmengen der Textdaten trainiert, und ihre Vorhersagen werden kombiniert, um die Gesamtvorhersagegenauigkeit zu verbessern.
- Betrugserkennung: Banken verlassen sich in hohem Maße auf die Betrugserkennung, um das Geld ihrer Kunden zu schützen und böswillige Handlungen auf ihren Bankkonten zu erkennen. Mehrere individuelle Modelle werden auf verschiedenen Teilmengen der Transaktionsdaten trainiert, und ihre Vorhersagen werden kombiniert, um die Gesamtvorhersagegenauigkeit zu verbessern.
- Medizinische Diagnose: In der Medizin müssen Röntgenbilder oft klassifiziert werden. Hier kann es sinnvoll sein, viele einzelne Klassifikatoren zu kombinieren, die auf bestimmte Krankheitsbilder spezialisiert sind.
Was sind die Vor- und Nachteile des Ensemble Learnings?
Ensemble Learning ist eine leistungsstarke Technik des maschinellen Lernens, bei der die Vorhersagen mehrerer Einzelmodelle kombiniert werden, um die Vorhersagegenauigkeit insgesamt zu verbessern. Diese Technik hat mehrere Vorteile, darunter verbesserte Genauigkeit, erhöhte Stabilität, weniger Overfitting, verbesserte Robustheit und Vielseitigkeit. Durch die Kombination der Vorhersagen mehrerer Einzelmodelle kann das Ensemble Learning die Stärken der einzelnen Modelle nutzen und ihre Schwächen abmildern, was zu genaueren und stabileren Vorhersagen führt.
Darüber hinaus kann das Ensemble Learning das Risiko einer Überanpassung verringern, die auftritt, wenn ein Modell zu komplex ist und zu gut zu den Trainingsdaten passt, was zu einer schlechten Generalisierung neuer Daten führt. Darüber hinaus kann das Ensemble-Lernen die Robustheit der Vorhersage verbessern, so dass sie weniger empfindlich auf Ausreißer oder Fehler in den Daten reagiert. Schließlich kann das Ensemble Learning auf verschiedene Arten von Daten und Modellen angewendet werden, was es zu einer vielseitigen und flexiblen Technik macht.
Allerdings hat das Ensemble Learning auch einige Nachteile. Erstens kann es die Komplexität des Modells erhöhen, wodurch es schwieriger zu interpretieren ist. Durch die Verwendung mehrerer Einzelmodelle wird das Gesamtmodell komplexer und schwieriger zu verstehen, insbesondere bei großen Datensätzen. Zweitens kann das Ensemble Learning mehr Rechenressourcen erfordern. Durch die Verwendung mehrerer Einzelmodelle benötigt das Gesamtmodell mehr Rechenressourcen für Training und Vorhersage, was in ressourcenbeschränkten Umgebungen eine Herausforderung darstellen kann. Schließlich kann es beim Ensemble Learning auch zu einer Überanpassung kommen, wenn die einzelnen Modelle nicht sorgfältig ausgewählt werden oder die Ensemblegröße zu groß ist. Daher sind eine sorgfältige Modellauswahl und die Größe des Ensembles entscheidend, um eine Überanpassung zu vermeiden und die Vorteile des Ensemble-Learnings zu maximieren.
Welche Algorithmen basieren auf Ensemble Learning?
Im Bereich des maschinellen Lernens gibt es einige Algorithmen, die mehrere Modelle kombinieren und sich die Prinzipien des Ensemble-Lernens zunutze machen. Im Folgenden werden wir einige von ihnen näher betrachten.
Random Forest
Der Random Forest besteht aus einer großen Anzahl dieser Entscheidungsbäume, die als sogenanntes Ensemble zusammenarbeiten. Jeder einzelne Entscheidungsbaum macht eine Vorhersage, z. B. ein Klassifizierungsergebnis, und der Wald verwendet das von den meisten Entscheidungsbäumen unterstützte Ergebnis als Vorhersage des gesamten Ensembles.
Dies kann auf genau dieselbe Weise auf den Random Forest angewendet werden. Eine große Anzahl von Entscheidungsbäumen und deren aggregierte Vorhersage wird immer besser sein als ein einzelner Entscheidungsbaum.

Dies gilt jedoch nur, wenn die Bäume nicht miteinander korreliert sind und somit die Fehler eines einzelnen Baumes durch andere Entscheidungsbäume kompensiert werden. Der Median der Schätzungen aller 800 Personen hat nur dann eine Chance, besser zu sein als jede einzelne Person, wenn die Teilnehmer nicht miteinander übereinstimmen, d.h. nicht korreliert sind. Diskutieren die Teilnehmer jedoch vor der Schätzung miteinander und beeinflussen sich so gegenseitig, tritt die Weisheit der Vielen nicht mehr ein.
AdaBoost
Adaptive Boosting, oder kurz AdaBoost, ist eine spezielle Variante des Boosting. Es versucht, mehrere schwache Lerner zu einem starken Modell zu kombinieren. In seiner Grundform funktioniert Adaptive Boost am besten mit Entscheidungsbäumen. Allerdings verwenden wir nicht die “ausgewachsenen” Bäume mit teilweise mehreren Ästen, sondern nur die Stümpfe, d.h. Bäume mit nur einem Ast. Diese werden “Entscheidungsstümpfe” genannt.

In unserem Beispiel wollen wir eine Klassifikation trainieren, die vorhersagen kann, ob eine Person gesund ist oder nicht. Hierfür verwenden wir insgesamt drei Merkmale: Alter, Gewicht und die Anzahl der Stunden Sport pro Woche. In unserem Datensatz gibt es insgesamt 20 untersuchte Personen. Der Adaptive-Boost-Algorithmus arbeitet nun in mehreren Schritten:
- Schritt 1: Für jedes Merkmal wird ein Entscheidungsstumpf mit dem gewichteten Datensatz trainiert. Zu Beginn haben alle Datenpunkte noch das gleiche Gewicht. In unserem Fall bedeutet das, dass wir einen einzigen Stumpf für Alter, Gewicht und Sportstunden haben, der die Gesundheit direkt anhand des Merkmals klassifiziert.
- Schritt 2: Aus den drei Entscheidungsstümpfen wählen wir das Modell aus, das die beste Erfolgsquote aufweist. Nehmen wir an, der Stumpf mit den Sportstunden hat am besten abgeschnitten. Von den 20 Personen konnte er bereits 15 richtig klassifizieren. Die fünf falsch klassifizierten erhalten nun eine höhere Gewichtung im Datensatz, um sicherzustellen, dass sie im nächsten Modell auf jeden Fall richtig klassifiziert werden.
- Schritt 3: Der neu gewichtete Datensatz wird nun verwendet, um wieder drei neue Decision Stumps zu trainieren. Mit dem “neuen” Datensatz” schnitt diesmal der Stumpf mit dem Merkmal “Alter” am besten ab und klassifizierte nur drei Personen falsch.
- Schritt 4: Die Schritte zwei und drei werden nun so lange wiederholt, bis entweder alle Datenpunkte richtig klassifiziert wurden oder die maximale Anzahl der Iterationen erreicht wurde. Dies bedeutet, dass das Modell die neue Gewichtung des Datensatzes und das Training neuer Entscheidungsstümpfe wiederholt.
Jetzt verstehen wir, woher der Name “Adaptive” in AdaBoost kommt. Durch die Neugewichtung des ursprünglichen Datensatzes “passt” sich das Ensemble mehr und mehr an den konkreten Anwendungsfall an.
Gradient Boosting
Gradient Boosting wiederum ist eine Untergruppe von vielen verschiedenen Boosting-Algorithmen. Die Grundidee dahinter ist, dass das nächste Modell so aufgebaut werden sollte, dass es die Verlustfunktion des Ensembles weiter minimiert.
In den einfachsten Fällen beschreibt die Verlustfunktion einfach die Differenz zwischen der Vorhersage des Modells und dem tatsächlichen Wert. Nehmen wir an, wir trainieren eine KI für die Vorhersage eines Hauspreises. Die Verlustfunktion könnte dann einfach der mittlere quadratische Fehler zwischen dem tatsächlichen Preis des Hauses und dem vorhergesagten Preis des Hauses sein. Im Idealfall nähert sich die Funktion im Laufe der Zeit der Null, und unser Modell kann korrekte Preise vorhersagen.
Neue Modelle werden so lange hinzugefügt, bis Vorhersage und Realität nicht mehr voneinander abweichen, d. h. die Verlustfunktion das Minimum erreicht hat. Jedes neue Modell versucht, den Fehler des vorherigen Modells vorherzusagen.
Kehren wir zu unserem Beispiel mit den Hauspreisen zurück. Nehmen wir an, eine Immobilie hat eine Wohnfläche von 100 m², vier Zimmer und eine Garage und kostet 200.000 €. Der Gradient-Boosting-Prozess würde dann wie folgt aussehen:
Training einer Regression zur Vorhersage des Kaufpreises mit den Merkmalen Wohnfläche, Anzahl der Zimmer und der Garage. Dieses Modell sagt einen Kaufpreis von 170.000 € statt der tatsächlichen 200.000 € voraus, der Fehler beträgt also 30.000 €.
Training einer weiteren Regression, die den Fehler des vorherigen Modells mit den Merkmalen Wohnfläche, Anzahl der Zimmer und Garage vorhersagt. Dieses Modell sagt eine Abweichung von 23.000 € statt der tatsächlichen 30.000 € voraus. Der verbleibende Fehler beträgt also 7.000 €.
Das solltest Du mitnehmen
- Ensemble Learning ist eine Technik des maschinellen Lernens, die den Prozess der Kombination mehrerer sogenannter schwacher Lerner zu einem verbesserten Modell beschreibt.
- In vielen Anwendungsbereichen können Ensemble-Modelle sogar bessere Ergebnisse erzielen als neuronale Netze.
- Darüber hinaus haben sie weitere Vorteile gegenüber anspruchsvolleren Modellen wie ein geringeres Risiko der Überanpassung.

Was ist die Grid Search?
Optimieren Sie Ihre Modelle für maschinelles Lernen mit Grid Search. Erforschen Sie die Abstimmung von Hyperparametern mit Python.

Was ist die Lernrate?
Entfalten Sie die Kraft der Lernraten beim maschinellen Lernen: Tauchen Sie ein in Strategien, Optimierung und Feinabstimmung für Modelle.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.
Andere Beiträge zum Thema Ensemble Learning
Einen Überblick über die Ensemble-Methoden von Scikit-Learns findest Du hier.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.