Overfitting (deutsch: Überanpassung) ist ein Begriff aus dem Bereich des Data Science und beschreibt die Eigenschaft eines Modells sich zu stark auf den Trainingsdatensatz anzupassen. Dadurch performt das Modell nur sehr schlecht auf neue, ungesehene Daten. Das Ziel eines Machine Learning Modells ist jedoch eine gute Generalisierung, sodass die Vorhersage auf neue Daten möglich wird.
Was ist Overfitting?
Der Begriff Overfitting wird im Zusammenhang mit Vorhersagemodellen genutzt, die zu spezifisch auf den Trainingsdatensatz angepasst sind und dadurch die Streuung der Daten mit erlernen. Dies passiert häufig, wenn das Modell eine zu komplexe Struktur hat für die zugrundeliegenden Daten. Das Problem ist dann, dass das trainierte Modell nur sehr schlecht generalisiert, also nur unzureichende Vorhersagen für neue, ungesehene Daten liefert. Die Performance auf dem Trainingsdatensatz hingegen war sehr gut, weshalb man von einer hohen Modellgüte ausgehen könnte.
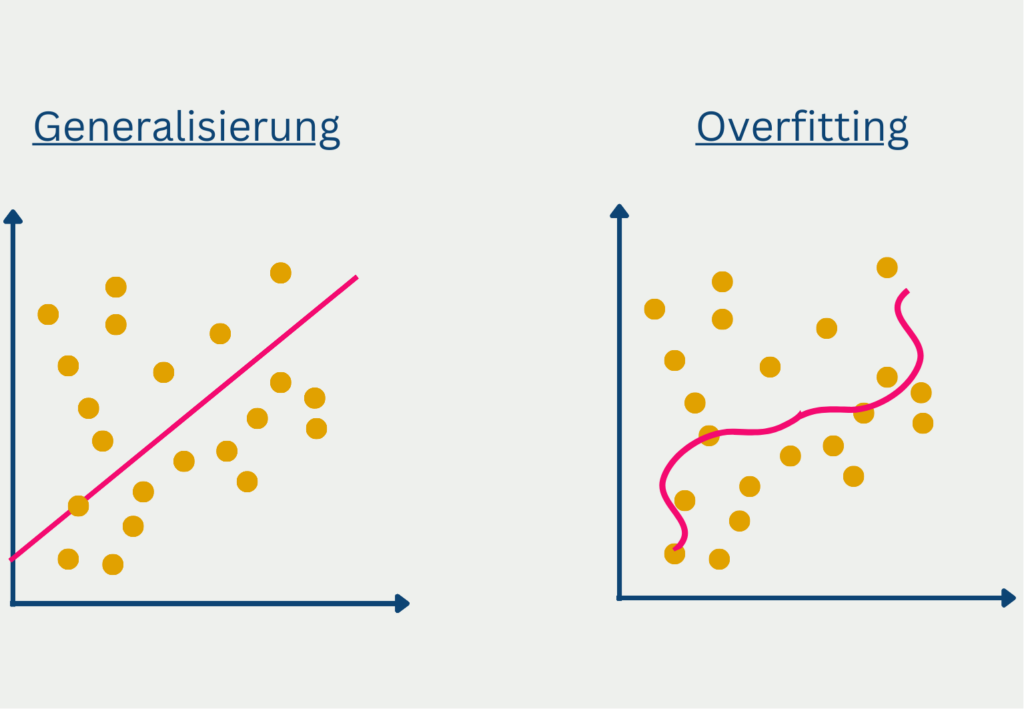
Einige Faktoren können bereits frühzeitig auf eine drohende Überanpassung hindeuten:
- Kleiner Datensatz: Wenn nur wenige einzelne Datensätze im Training vorhanden sind, ist die Wahrscheinlichkeit sehr hoch, dass diese einfach auswendig gelernt werden und viel zu wenige Informationen vorhanden sind, um eine zugrundliegende Struktur erlernen zu können. Umso problematischer wird es, umso mehr Trainingsparameter das Modell hat. Ein Neuronales Netzwerk beispielsweise besitzt auf jeder Hidden Layer eine Vielzahl von Parameter. Deshalb sollte man mit steigender Komplexität des Modell auch den Datensatz vergrößern.
- Auswahl des Trainingsdatensatzes: Wenn die Auswahl der Datensätze bereits unausgewogen ist, ist die Wahrscheinlichkeit groß, dass das Modell diese trainiert und somit eine schlechte Generalisierung hat. Das Sample aus einer Population sollte immer zufällig getroffen werden, sodass es nicht zu einem Selection Bias kommt. Um eine Hochrechnung während einer Wahl zu erstellen, sollten nicht nur die Wähler an einem Wahllokal befragt werden, da diese nicht repräsentativ für das gesamte Land sind, sondern lediglich die Meinung in diesem Wahlbezirk vertreten.
- Viele Trainingsepochen: Ein Modell trainiert mehrere Epochen und hat in jeder Epoche das Ziel, die Verlustfunktion weiter zu minimieren und dadurch die Qualität des Modells zu erhöhen. Ab einem gewissen Punkt kann es jedoch passieren, dass nur noch Verbesserungen in der Backpropagation erzielt werden können, indem sich mehr auf den Trainingsdatensatz angepasst wird.
Wie erkennt man Overfitting?
Leider gibt es keine zentrale Analyse, die mit Sicherheit ergibt, ob ein Modell overfitted oder nicht. Jedoch gibt es einige Parameter und Analysen, die Hinweise auf ein drohendes Overfitting liefern können. Die beste und einfachste Methode ist sich dazu die Fehlerkurve des Modells über die Iterations hinweg anzuschauen.
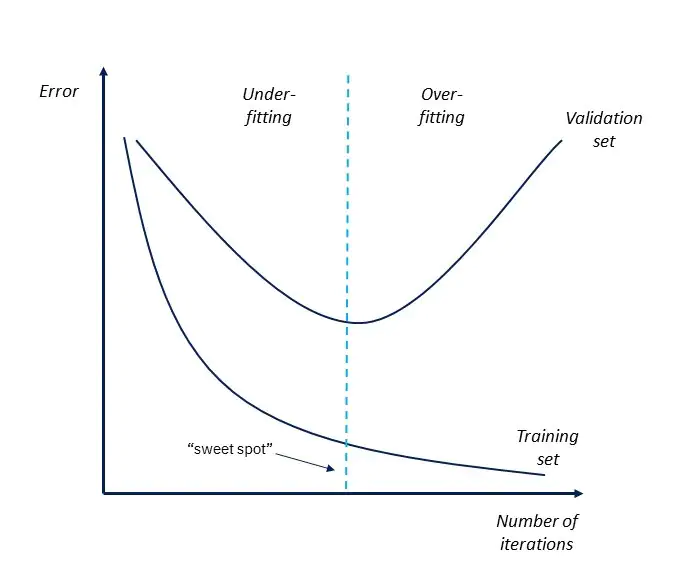
Wenn der Fehler im Trainingsdatensatz weiter sinkt, während jedoch der Fehler im Validierungsdatensatz wieder beginnt zu steigen, spricht das dafür, dass sich das Modell zu sehr an die Trainingsdaten anpasst und dadurch schlecht generalisiert. Eine gleiche Auswertung kann man auch mit dem Verlauf der Verlustfunktion machen.
Um einen solchen Grapfen aufzubauen, benötigt man das sogenannte Validation- oder Test-Set, also für das Modell ungesehene Daten. Falls der Datensatz groß genug ist, kann man dazu meist 20 – 30 % des Datensatzes abspalten und als Testdatensatz nutzen. Ansonsten gibt es auch die Möglichkeit die sogenannte k-Fold Cross-Validation zu nutzen, die etwas komplexer ist und dafür auch bei kleineren Datensätzen genutzt werden kann.
Der Datensatz wird dabei in k gleichgroße Blöcke unterteilt. Einer der Blocks wird zufällig gewählt und dient als Testdatensatz und die anderen Blöcke wiederum sind die Trainingsdaten. Im zweiten Trainingsschritt jedoch wird ein anderer Block als Testdaten definiert und der Prozess wiederholt sich.
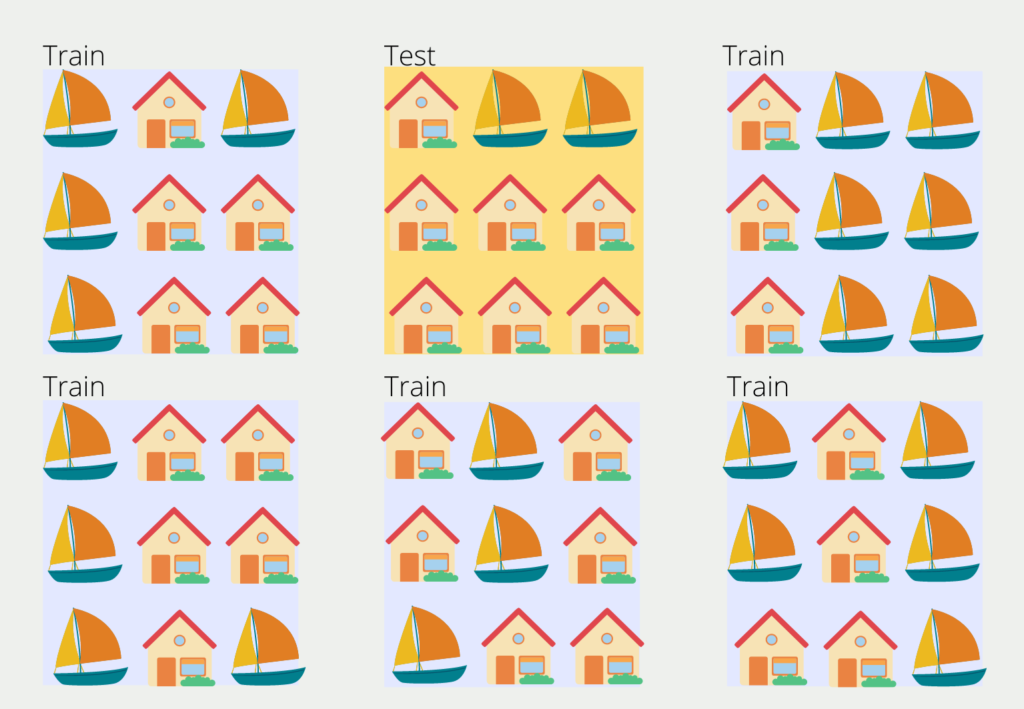
Die Anzahl der Blöcke k lässt sich beliebig wählen und in den meisten Fällen wird ein Wert zwischen 5 und 10 gewählt. Ein zu großer Wert führt zu einem weniger verzerrten Modell, jedoch steigt das Risiko des Overfittings. Ein zu kleiner k Wert führt zu einem stärker verzerrten Modell, da es dann eigentlich der Hold-Out Methode entspricht.
Wie kann man Overfitting verhindern?
Es gibt viele verschiedene Möglichkeiten, um das Overfitting zu verhindern oder zumindest die Wahrscheinlichkeit dafür zu verringern. Aus den folgenden Vorschlägen sollte in vielen Fällen bereits zwei ausreichen, um das Risiko für Overfitting gering zu halten:
- Datensatz: Der Datensatz spielt eine sehr große Rolle bei der Vermeidung von Overfitting. Er sollte dabei so groß, wie nur möglich sein, und verschiedene Daten enthalten. Des Weiteren sollte genügend Zeit in den Aufbereitungsprozess der Daten geflossen sein. Wenn nämlich falsche oder fehlende Daten zu häufig vorkommen, steigt dadurch die Komplexität und das Risiko der Überanpassung steigt entsprechend. Mit einem sauberen Datensatz hingegen tut sich das Modell einfacher, die zugrundeliegende Struktur zu erkennen.
- Data Augmentation: In vielen Anwendungen, wie beispielsweis der Bilderkennung, werden einzelne Datensätze genutzt und mit leichten Veränderungen dem Modell zusätzlich zum Trainieren gegeben. Bei diesen Änderungen kann es sich beispielsweise um eine schwarz-weiß Kopie eines Bilds handeln oder um denselben Text mit einigen Tippfehlern darin. Dadurch wird das Modell stabiler und lernt mit Datenvariationen umzugehen und unabhängiger vom ursprünglichen Trainingsdatensatz zu werden.
- Stopping Rule: Beim Start eines Modells gibt man eine maximale Anzahl von Epochen an, nach denen das Training beendet ist. Zusätzlich kann es Sinn machen, das Training bereits frühzeitig zu beenden, beispielsweise wenn es über mehrere Epochen keinen wirklichen Fortschritt mehr macht (die Verlustfunktion nicht mehr weiter abnimmt) und somit die Gefahr besteht, dass das Modell ins Overfitting läuft. In TensorFlow lässt sich dafür ein eigener Callback definieren:
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)- Featureauswahl: Ein Datensatz enthält oft eine Vielzahl von Features, die als Input an das Modell gegeben werden. Doch nicht alle werden wirklich für die Vorhersage des richtigen Ergebnisses benötigt. Manche Features können sogar untereinander korreliert sein, also in Abhängigkeit zueinander stehen. Wenn eine Vielzahl von Features vorhanden, sollte mithilfe von geeigneten Algorithmen eine Vorauswahl getroffen werden. Ansonsten nimmt die Komplexität des Modells zu und das Risiko für Overfitting ist hoch.
Overfitting vs. Underfitting
Das Overfitting und Underfitting sind zwei Problemstellungen, die beim Training eines Machine Learning Algorithmus häufig vorkommen. Beide haben einen erheblichen Einfluss auf die Generalisierungsfähigkeit des Modells, also darauf, wie gut die Vorhersagen des Modells auf neuen Daten sind. Im Falle des Overfittings ist die Modellstruktur zu komplex, was dazu führt, dass es sich zu stark an die Traningsdaten anpasst und auch das Rauschen der Trainingsdaten mit lernt. Dadurch kommt es zu falschen Vorhersagen bei den Testdaten, die dieses Rauschen möglicherweise nicht haben. Die Erkennung des Overfittings kann über die Genauigkeiten stattfinden, die auf dem Trainings- oder Validierungsset sehr hoch sind, aber auf den Testdaten nur sehr gering. Dies ist ein Indikator für Overfitting.
Beim Underfitting hingegen ist das Modell nicht komplex genug, um die zugrundeliegende Struktur in den Daten zu erkenne und zu erlernen. Dadurch ist die Modellleistung sowohl bei den Trainingsdaten als auch bei den Testdaten stark beeinträchtigt. Erkennen kann man Underfitting an der Eigenschaft, dass der Fehler auf den Trainingsdaten sehr hoch ist und auch im weiteren Trainingsverlauf auf dem hohen Niveau stagniert und nicht abnimmt. Obwohl das Underfitting deutlich seltener als Overfitting vorkommt, ist es ein ernstzunehmendes Problem in der Erstellung von Machine Learning Modellen.
Die Problematik dieser beiden Phänomene besteht darin, dass sie im Gleichgewicht zueinander stehen und es schwierig sein kann, den Punkt zu finden, an dem das Overfitting verhindert wurde, ohne dass das Modell ins Underfitting abrutscht. Es gibt verschiedene Techniken, die genutzt werden können, um dieses Gleichgewicht zu finden.
Zu den häufigsten Methoden zählen:
- Regularisierung: Bei der Regularisierung werden verschiedene Parameter der Verlustfunktion hinzugefügt, die die Anzahl der Modellparameter berücksichtigt und somit ein Hinzufügen von neuen Inputparameter, die nicht zu einer ausreichenden Verbesserung des Modells führen, bestraft. Dadurch lässt sich Overfitting bekämpfen.
- Kreuzvalidierung: Die Cross-Validation sorgt für eine dynamische Durchmischung des Trainings- und Validierungssets. Dadurch steht dem Modell eine größere Menge an Trainingsdaten bereit und die Leistung des Modells wird bereits während des Trainings unabhängiger bewertet.
- Early Stopping: Mit dieser Regel wird das Training eines Machine Learnings Modells frühzeitig gestoppt, wenn anzunehmen ist, dass in den nachfolgenden Trainingsläufen zu einer Überanpassung kommen könnte. Dabei wird untersucht, ob der Validierungsverlust über mehrere Epochen oder Iterationen hinweg zunimmt, was auf ein drohendes Overfitting hindeutet.
Die Balance zwischen Overfitting und Underfitting ist beim Training von Machine Learning Modellen eine entscheidende Thematik, die beachtet und im Training berücksichtigt werden sollte, um eine gute Generalisierung herbeizuführen.
Was sind die Konsequenzen von Overfitting in der Anwendung?
Eine Überanpassung kann in der realen Welt erhebliche Folgen haben, insbesondere bei Anwendungen, bei denen die Vorhersagen des Modells als Entscheidungsgrundlage dienen. Einige Beispiele für die Folgen einer Überanpassung sind:
- Schlechte Generalisierung: Überangepasste Modelle sind stark auf die Trainingsdaten abgestimmt und können daher oft nicht gut auf ungesehene Daten verallgemeinert werden. Das bedeutet, dass das Modell bei den Trainingsdaten gut abschneidet, bei den neuen Daten jedoch schlecht, so dass es in realen Anwendungen unbrauchbar ist.
- Verzerrungen bei der Entscheidungsfindung: Überangepasste Modelle können zu verzerrten Ergebnissen führen, die bestimmte Ergebnisse oder Datengruppen bevorzugen. Dies kann besonders bei Anwendungen zur Entscheidungsfindung problematisch sein, z. B. bei der Kreditwürdigkeitsprüfung oder der medizinischen Diagnose, wo selbst kleine Abweichungen erhebliche Folgen haben können.
- Vergeudete Ressourcen: Übermäßiges Anpassen führt häufig zur Entwicklung komplexer Modelle, deren Training und Einsatz erhebliche Rechenressourcen erfordert. Dies kann zu einer Verschwendung von Zeit, Geld und Rechenleistung führen, insbesondere wenn das resultierende Modell in der Praxis nicht nützlich ist.
- Erhöhtes Risiko: Überangepasste Modelle können den Eindruck von Genauigkeit erwecken, was zu übermäßigem Vertrauen in ihre Vorhersagen führt. Dies kann das Risiko erhöhen, auf der Grundlage fehlerhafter Modellergebnisse falsche Entscheidungen zu treffen oder unangemessene Maßnahmen zu ergreifen.
Zusammenfassend lässt sich sagen, dass eine Überanpassung schwerwiegende Folgen für die Praxis haben kann, weshalb es wichtig ist, Modelle zu entwickeln, die ein ausgewogenes Verhältnis zwischen Komplexität und Verallgemeinerung bieten.
Das solltest Du mitnehmen
- Das Overfitting (deutsch: Überanpassung) ist ein Begriff aus dem Bereich des Data Science und beschreibt die Eigenschaft eines Modells sich zu stark auf den Trainingsdatensatz anzupassen.
- Es ist meist daran erkennbar, dass der Fehler im Testdatensatz wieder zunimmt, während der Fehler im Trainingsdatensatz weiter abnimmt.
- Man kann das Overfitting unter anderem dadurch verhindern, dass eine frühzeitige Stopping Rule einfügt oder im Vorhinein Features aus dem Datensatz entfernt, die mit anderen Features korreliert sind.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.

Was ist die Bellman Gleichung?
Die Beherrschung der Bellman-Gleichung: Optimale Entscheidungsfindung in der KI. Lernen Sie ihre Anwendungen und Grenzen kennen.

Was ist die Singular Value Decomposition?
Erkenntnisse und Muster freilegen: Lernen Sie die Leistungsfähigkeit der Singular Value Decomposition (SVD) in der Datenanalyse kennen.

Was ist die Poisson Regression?
Lernen Sie die Poisson-Regression kennen, ein statistisches Modell für die Analyse von Zähldaten, inkl. einem Beispiel in Python.

Was ist blockchain-based AI?
Entdecken Sie das Potenzial der blockchain-based AI in diesem aufschlussreichen Artikel über Künstliche Intelligenz und Blockchain.
Andere Beiträge zum Thema Overfitting
- IBM bietet einen interessanten Artikel zum Thema Overfitting und wurde auch als Quelle für diesen Beitrag genutzt.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.