Als Curse of Dimensionality, oder auf deutsch “Fluch der Dimensionalität”, bezeichnet man Probleme, die entstehen, wenn man einen Datensatz mit vielen Attributen/Features hat. Im ersten Moment mag es positiv erscheinen viele Attribute und damit viel Information zu haben, jedoch ergeben sich daraus einige Probleme beim Training von Machine Learning Modellen.
Was ist der Curse of Dimensionality?
Der Curse of Dimensionality tritt bei hochdimensionalen Datensätzen auf, also solchen, die eine Vielzahl von Attributen oder Features haben. Im ersten Moment sind viele Attribute eine gute Sache, da sie sehr viel Information enthalten und die Datenpunkte gut umschreiben. Wenn wir einen Datensatz über Personen haben, können die Attribute beispielsweise Informationen, wie die Haarfarbe, Größe, Gewicht, Augenfarbe etc. sein.
Im mathematischen Sinne bedeutet jedes weitere Attribut eine neue Dimension im Raum und dadurch eine deutliche Erhöhung an Möglichkeiten. Angenommen wir wollen herausfinden, welche Kunden gewisse Produkte kaufen. Im ersten Schritt betrachten wir dafür nur das Alter der Interessenten und ob sie das Produkt gekauft haben. Das können wir noch relativ einfach in einem zweidimensionalen Diagramm abbilden.
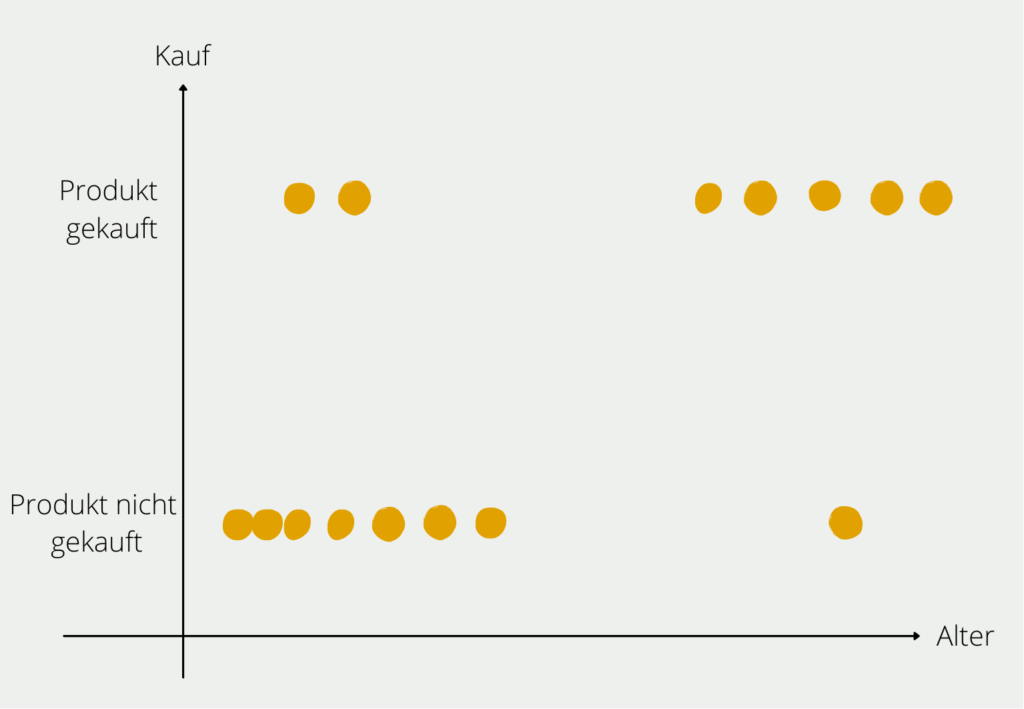
Sobald wir weitere Informationen zum Kunden hinzufügen, wird die Sache etwas komplexer. Die Information zu dem Einkommen des Kunden würde eine neue Achse bedeuten, auf der das numerische Einkommen abgebildet ist. Also wird aus dem zweidimensionalen Diagramm ein dreidimensionales. Das zusätzliche Attribut “Geschlecht” würde zu einer vierten Dimension führen und so weiter.
Welche Probleme ergeben sich bei vielen Dimensionen?
In der Arbeit mit Daten ist es eigentlich wünschenswert sehr viele Attribute und Informationen im Datensatz zu haben, um dem Modell viele Möglichkeiten zu lassen, Strukturen in den Daten zu erkennen. Jedoch kann es auch zu ernstzunehmenden Problemen führen, wie der Name Curse of Dimensionality bereits vermuten lässt.
Data Sparsity
Das aufgezeigte Beispiel illustriert ein Problem, das mit vielen Attributen auftritt. Aufgrund der großen Anzahl der Dimensionen wächst auch der sogenannte Datenraum, das heißt die Zahl der Werte, die ein Datensatz annehmen kann. Dann kann es zu einer sogenannten Data Sparsity (deutsch: Datensparsamkeit) kommen. Das bedeutet, dass der Trainingsdatensatz zum Trainieren des Modells gewisse Ausprägungen gar nicht oder nur sehr selten enthält. Dadurch liefert das Modell für diese Randfälle auch nur schlechte Ergebnisse.
Angenommen wir untersuchen in unserem Beispiel 1.000 Kunden, da es zu aufwändig wäre noch mehr Kunden zu befragen oder diese Daten einfach nicht zur Verfügung stehen. Möglicherweise sind bei diesen Kunden alle Altersklassen von jung bis alt relativ gut vertreten. Wenn jedoch noch die weitere Dimension Einkommen hinzukommt ist es eher unwahrscheinlich, dass alle Möglichkeiten von Alter und Einkommenskombinationen gleichzeitig bei den 1.000 Kunden vertreten sind.
Distance Concentration
Wenn man im Machine Learning Bereich die Ähnlichkeit von verschiedenen Datensätzen bewerten will, werden dafür oft Distanzfunktionen genutzt. Die gängigsten Clustering-Algorithmen, wie beispielsweise das k-Means Clustering, setzen darauf, die Distanz zwischen Punkten zu berechnen und sie abhängig von der Größe einem Cluster zuzuordnen oder nicht. In mehrdimensionalen Räumen kann es jedoch schnell zu dem Punkt kommen, dass alle Punkte ähnlich weit voneinander entfernt sind, sodass eine Trennung fast nicht möglich zu sein scheint.
Dieses Phänomen kennen wir teilweise auch aus dem Alltag. Wenn man ein Foto schießt von zwei Objekten, wie beispielsweise zwei Bäumen, dann können diese auf dem Bild sehr nahe zueinander aussehen, da es lediglich ein zweidimensionales Bild ist. In echt kann es aber vorkommen, dass die Bäume mehrere Meter auseinander stehen, was erst in drei Dimensionen deutlich wird.
Diese Problematiken, die im Zusammenhang mit vielen Dimensionen auftreten können, werden unter dem Begriff Curse of Dimensionality zusammengefasst.
Was kann man gegen den Curse of Dimensionality tun?
Wie man bis zu diesem Punkt wahrscheinlich bereits rauslesen konnte, liegt die Problematik an den vielen Dimensionen. Enstprechend liegt die Lösung auch auf der Hand: Wir müssen es schaffen, die Zahl der Dimensionen zu verringern und das am Besten so, dass möglichst wenig Information aus dem ursprünglichen Datensatz verloren geht.
Hierbei gibt es grundlegend zwei verschiedene Herangehensweisen:
Feature Auswahl
Die erste Lösung zur Bekämpfung des Curse of Dimensionality ist möglicherweise sehr zielstrebig: Wir wählen lediglich die Features aus, die besonders gut zur Lösung des Problems beitragen. Das bedeutet wir beschränken uns lediglich auf Dimensionen, die eine gewisse Wichtigkeit für das Problem haben. Auch hierfür gibt es verschiedene Möglichkeiten, zu den häufigsten zählen diese:
- Korrelationsanalyse: Zur Auswahl von geeigneten Attributen werden alle Korrelationen zwischen zwei Attributen berechnet. Wenn zwei Attribute eine hohe Korrelation aufweisen, kann man möglicherweise eines der Attribute entfernen, ohne viel Informationsgehalt zu verlieren.
- Multikollinearität: Dieses Vorgehen ist ähnlich zur Korrelationsanalyse mit dem Unterschied, dass nicht nur paarweise Attribute untersucht werden, sondern dass auch untersucht wird, ob sich einzelne Attribute als eine Summe, gewissermaßen als Lineare Regression von anderen Attributen darstellen lassen. Wenn dies möglich ist, können alle Attribute ausgelassen werden, die Teil der Regressionsgeraden sind.
Der Vorteil der Feature Auswahl ist, dass die Attribute in ihrer ursprünglichen Form erhalten bleiben und dadurch auch einfacher interpretiert werden können.
Feature Extraktion
Die zweite Herangehensweise zur Bekämpfung der Curse of Dimensionality geht hierbei einen anderen Weg und versucht aus den vielen Dimensionen neue, zusammengefasste Dimensionen zu bilden, sodass die Dimensionszahl reduziert wird und trotzdem ein möglichst hoher Informationsgehalt erhalten bleibt.
Ein häufig genutzer Algorithmus dafür ist die sogenannte Principal Component Analysis. Der Kerngedanke der Principal Component Analysis ist, dass möglicherweise mehrere Variablen in einem Datensatz dasselbe messen, also korreliert sind. Somit kann man die verschiedenen Dimensionen zu weniger sogenannten Hauptkomponenten zusammenfassen, ohne, dass die Aussagekraft des Datensatzes darunter leidet. Die Körpergröße beispielsweise weist eine hohe Korrelation mit der Schuhgröße auf, da große Menschen in vielen Fällen auch eine größere Schuhgrößere haben und andersrum. Wenn wir also die Schuhgröße als Variable aus unserem Datensatz streichen, nimmt der Informationsgehalt nicht wirklich ab.
Der Informationsgehalt eines Datensatzes wird in der Statistik durch die Varianz bestimmt. Diese gibt an, wie stark die Datenpunkte vom Mittelpunkt entfernt sind. Je kleiner die Varianz, desto näher liegen die Datenpunkte bei ihrem Mittelwert und andersrum. Eine kleine Varianz sagt somit aus, dass der Mittelwert bereits ein guter Schätzwert für den Datensatz ist.
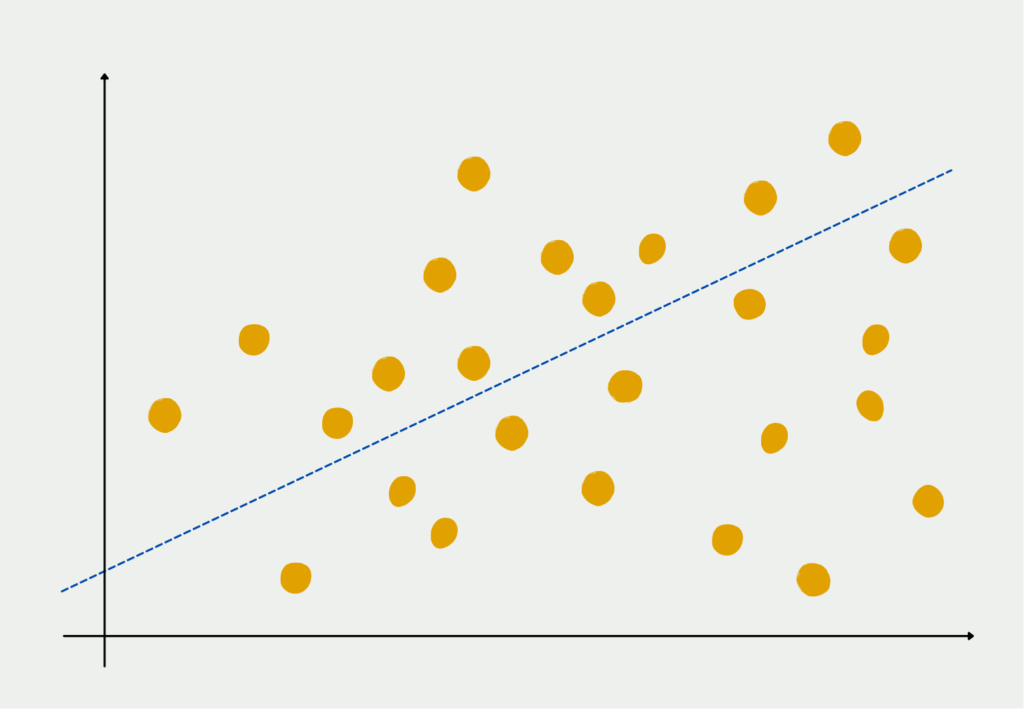
Die PCA versucht im ersten Schritt die Variable zu finden, die die erklärte Varianz des Datensatzes maximiert. Anschließend werden schrittweise mehr Variablen hinzugefügt, die den verbleibenden Teil der Varianz erklären, denn in der Varianz, also der Abweichung vom Mittelwert, steckt die meiste Information. Diese sollte erhalten bleiben, wenn wir darauf basierend ein Modell trainieren wollen.
Dieser Ansatz kann in vielen Fällen zu besseren Ergebnisse führen, als eine Feature Auswahl, jedoch werden dabei neue, künstliche Attribute erstellt, die nicht so einfach zu interpretieren sind. Die erste Hauptkomponente beispielsweise ist eine Kombination aus verschiedensten Attributen. Im Einzelfall kann man diese dann noch zu einer größeren Übergruppe zusammenfassen. Beispielsweise lassen sich Attribute wie Größe, Gewicht und Schuhgröße zu der Gruppe “körperliche Merkmale” zusammenfassen und interpretieren.
Bei welchen Anwendungen hat zeigt sich der Curse of Dimensionality?
Der Fluch der Dimensionalität hat weitreichende Folgen und kann sich auf verschiedene Bereiche auswirken. Hier sind einige Beispiele und Anwendungen:
- Maschinelles Lernen: Beim maschinellen Lernen sind hochdimensionale Daten üblich, und der Curse of Dimensionality kann die Modellgenauigkeit und -effizienz beeinträchtigen. Es kann zu einer Über- oder Unteranpassung der Daten kommen, was zu einer schlechten Leistung der Algorithmen führt.
- Recommendation Systems: Empfehlungssysteme schlagen Nutzern Produkte, Dienstleistungen oder Inhalte auf der Grundlage ihrer Präferenzen vor. In hochdimensionalen Datensätzen wird es schwierig, aussagekräftige Muster im Benutzerverhalten zu erkennen, was zu schlechten Empfehlungen führt.
- Optimierungsprobleme: Bei Optimierungsproblemen geht es oft darum, die optimale Lösung aus einer großen Menge möglicher Lösungen zu finden. In hochdimensionalen Räumen wird es immer schwieriger, die optimale Lösung zu finden, was zu erhöhter Berechnungszeit und geringerer Genauigkeit führt.
- Computergestützte Biologie: Die computergestützte Biologie befasst sich mit der Analyse großer Datensätze in der Biologie, wie z. B. genomischer Daten. In hochdimensionalen Datensätzen wird es schwierig, sinnvolle Muster und Beziehungen zu erkennen, was zu ungenauen Vorhersagen und Analysen führt.
- Finanzen: Im Finanzwesen sind hochdimensionale Daten üblich, etwa bei der Portfoliooptimierung und beim Risikomanagement. Der Curse of Dimensionality kann sich auf die Portfolioperformance und Risikomanagementstrategien auswirken und zu suboptimalen Ergebnissen führen.
Insgesamt kann sich der Curse of Dimensionality auf ein breites Spektrum von Anwendungen und Bereichen auswirken. Er unterstreicht die Bedeutung der Datenvorverarbeitung, der Merkmalsauswahl und der Techniken zur Dimensionalitätsreduzierung, um die Grenzen hochdimensionaler Daten zu überwinden.
Das solltest Du mitnehmen
- Der Curse of Dimensionality ist ein Phänomen, das beim Umgang mit hochdimensionalen Daten auftritt, bei dem die zur genauen Darstellung der Daten erforderliche Datenmenge exponentiell mit der Anzahl der Dimensionen zunimmt.
- Dies kann zu einer Reihe praktischer Herausforderungen bei verschiedenen Anwendungen führen, z. B. bei der Datenspeicherung und -verarbeitung sowie bei Modellierungs- und Vorhersageaufgaben.
- Insbesondere kann der Curse of Dimensionality zu Über- und Unteranpassungsproblemen führen, bei denen Modelle entweder zu komplex oder zu einfach werden, um die zugrunde liegenden Muster in den Daten genau zu erfassen.
- Um die Auswirkungen des Curse of Dimensionality abzuschwächen, wurden verschiedene Techniken entwickelt, z. B. Merkmalsauswahl, Dimensionalitätsreduktion und Regularisierungsmethoden.
- Für Praktiker ist es wichtig, sich des Curse of Dimensionality und seiner Auswirkungen bewusst zu sein und sorgfältig abzuwägen, welche Techniken für den Umgang mit hochdimensionalen Daten geeignet sind.

Was ist die Grid Search?
Optimieren Sie Ihre Modelle für maschinelles Lernen mit Grid Search. Erforschen Sie die Abstimmung von Hyperparametern mit Python.

Was ist die Lernrate?
Entfalten Sie die Kraft der Lernraten beim maschinellen Lernen: Tauchen Sie ein in Strategien, Optimierung und Feinabstimmung für Modelle.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.
Andere Beiträge zum Thema Curse of Dimensionality
Tony Yiu veranschaulicht die Curse of Dimensionality anhand eines sehr schönen Beispiels.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.