Underfitting ist ein häufiges Problem beim maschinellen Lernen, bei dem ein Modell aufgrund seiner Einfachheit nicht in der Lage ist, die zugrunde liegenden Muster in den Daten zu erfassen. Dies kann zu einer schlechten Leistung sowohl bei den Trainings- als auch bei den Testdaten führen.
In diesem Artikel werden wir das Konzept, seine Ursachen und die Techniken, die zur Lösung dieses Problems eingesetzt werden können, näher erläutern. Wir werden auch erörtern, wie wichtig es ist, Underfitting bei Anwendungen des maschinellen Lernens zu vermeiden.
Was ist Underfitting und welche Auswirkungen hat es?
Underfitting ist ein Konzept des maschinellen Lernens, das auftritt, wenn ein Modell nicht in der Lage ist, die zugrunde liegenden Muster und Beziehungen in den Daten zu erfassen, was zu einer schlechten Vorhersageleistung führt. Dies geschieht, wenn das Modell zu einfach ist oder nicht die notwendige Komplexität aufweist, um die wahre Natur der Daten darzustellen.
Wenn ein Modell unterdurchschnittlich abschneidet, gelingt es ihm nicht, die komplizierten Details und Nuancen im Datensatz zu erkennen. Es kann die Beziehungen zwischen den Eingangsmerkmalen und der Zielvariablen zu stark vereinfachen, was zu ungenauen Vorhersagen führt. Underfitting ist häufig durch eine hohe Verzerrung gekennzeichnet, was bedeutet, dass das Modell übermäßig verallgemeinerte Annahmen über die Daten trifft.
Eine der Hauptauswirkungen der Unteranpassung ist eine schlechte Vorhersageleistung. Das Modell kann die Komplexität der Daten nicht erfassen, was zu ungenauen Vorhersagen sowohl in den Trainings- als auch in den Testdatensätzen führt. Dieser Mangel an Genauigkeit schränkt die Nützlichkeit des Modells in realen Anwendungen ein.
Eine unzureichende Anpassung ist oft mit einer hohen Verzerrung verbunden. Das Modell trifft übermäßig vereinfachte Annahmen über die Daten, was zu konsistenten Unter- oder Überprognosen führt. Diese Verzerrung verhindert, dass das Modell die wahren Beziehungen zwischen den Eingabemerkmalen und der Zielvariablen genau wiedergibt.
Eine weitere Auswirkung der unzureichenden Anpassung ist die mangelnde Fähigkeit zur Generalisierung auf unbekannte Daten. Das Modell kämpft damit, die gesamte Bandbreite an Mustern und Variationen in den Trainingsdaten zu erfassen, was zu einer schlechten Leistung führt, wenn es auf neue, ungesehene Beispiele angewendet wird. Dieser Mangel an Generalisierung schränkt die Nützlichkeit des Modells in realen Szenarien ein.
Darüber hinaus ist die Unteranpassung durch eine begrenzte Lernkapazität gekennzeichnet. Das Modell ist zu simpel, um komplexe Beziehungen in den Daten zu lernen und zu berücksichtigen. Es nutzt die verfügbaren Informationen nicht effektiv, was dazu führt, dass Möglichkeiten für genaue Vorhersagen und wertvolle Erkenntnisse verpasst werden.
Unzureichend angepasste Modelle weisen auch eine geringere Flexibilität auf. Sie sind nicht in der Lage, sich an Variationen und Komplexitäten in den Daten anzupassen, was zu einer suboptimalen Leistung führt. Die Einfachheit des Modells hindert es daran, die gesamte Bandbreite an Mustern und Wechselwirkungen zu erfassen, was seine Fähigkeit, genaue Vorhersagen zu treffen, einschränkt.
Warum kommt es zu Underfitting?
Underfitting tritt auf, wenn ein Modell des maschinellen Lernens nicht in der Lage ist, die zugrundeliegenden Muster in den Daten zu erfassen, was zu einer schlechten Leistung sowohl in den Trainings- als auch in den Testsätzen führt. Es gibt mehrere Gründe, warum Underfitting auftreten kann, unter anderem:
- Modellkomplexität: Wenn das Modell zu einfach ist, hat es möglicherweise nicht genug Kapazität, um die Muster in den Daten zu lernen. Dies kann passieren, wenn das Modell zu wenige Parameter oder Merkmale hat.
- Unzureichendes Training: Wenn das Modell nicht lange genug oder mit nicht genügend Daten trainiert wird, ist es möglicherweise nicht in der Lage, die zugrunde liegenden Muster in den Daten zu erfassen.
- Ungeeignete Modellauswahl: Wenn das Modell nicht für die Art der verwendeten Daten geeignet ist, kann es die zugrunde liegenden Muster in den Daten möglicherweise nicht erfassen.
- Falsche Vorverarbeitung: Wenn die Daten nicht korrekt vorverarbeitet werden, können sie Rauschen oder irrelevante Merkmale enthalten, die das Modell verwirren und zu einer Unteranpassung führen können.
Insgesamt ist Underfitting ein häufiges Problem beim maschinellen Lernen, das durch eine Vielzahl von Faktoren verursacht werden kann. Die Behebung dieser Faktoren kann dazu beitragen, die Modellleistung zu verbessern und das Problem zu vermeiden.
Was sind Beispiele für Underfitting bei Modellen des maschinellen Lernens?
Underfitting tritt auf, wenn ein Modell für maschinelles Lernen zu einfach ist, um die zugrunde liegenden Muster in den Daten zu erfassen. In solchen Fällen ist das Modell nicht in der Lage, die relevanten Muster zu lernen, und infolgedessen ist die Leistung des Modells sowohl bei der Trainingsmenge als auch bei den ungesehenen Daten schlecht. Hier sind einige gängige Beispiele für Modelle des maschinellen Lernens:
- Lineare Modelle: Lineare Modelle gehen von einer linearen Beziehung zwischen den Eingangsmerkmalen und der Ausgangsvariablen aus. Wenn die tatsächliche Beziehung nicht linear ist, kann das Modell die Daten nicht richtig abbilden und eine schlechte Leistung aufweisen.
- Decision Trees: Bei Entscheidungsbäumen kann es zu einer unzureichenden Anpassung kommen, wenn sie zu oberflächlich sind oder wenn der Baum nicht komplex genug ist, um die zugrunde liegenden Muster in den Daten zu erfassen.
- Neuronale Netze: Auch bei neuronalen Netzen kann es zu einer Unteranpassung kommen, wenn sie nicht komplex genug sind. Wenn das Netz zu klein ist oder zu wenige versteckte Schichten hat, kann es die nichtlinearen Beziehungen in den Daten nicht erfassen.
- Support-Vektor-Maschinen: Support-Vektor-Maschinen können die Daten nicht richtig abbilden, wenn die verwendete Kernel-Funktion nicht für die Daten geeignet ist.
In all of these cases, the model is too simple to capture the complexity of the data, leading to underfitting.
Was ist der Unterschied zwischen Underfitting und Overfitting?
Beim maschinellen Lernen sind sowohl Underfitting als auch Overfitting häufige Probleme, die die Leistung eines Modells beeinträchtigen können. Während Underfitting auftritt, wenn ein Modell zu einfach ist und die zugrundeliegenden Muster in den Daten nicht erfasst, tritt Overfitting auf, wenn ein Modell zu komplex ist und das Rauschen in den Daten erfasst, was zu einer schlechten Generalisierungsleistung führt.
Underfitting kann als ein Modell betrachtet werden, das nicht in der Lage ist, so gut aus den Daten zu lernen, wie es könnte. Dies kann verschiedene Gründe haben, z. B. die Verwendung eines zu einfachen Modells oder die Verwendung zu weniger Trainingsbeispiele. Infolgedessen kann ein unterangepasstes Modell eine schlechte Genauigkeit bei den Trainingsdaten aufweisen und wird wahrscheinlich auch bei neuen, ungesehenen Daten schlecht abschneiden.
Andererseits kommt es zu einer Überanpassung, wenn ein Modell zu komplex wird und anfängt, sich an das Rauschen in den Trainingsdaten anzupassen, anstatt an die zugrunde liegenden Muster. Dies kann vorkommen, wenn ein Modell zu flexibel ist oder wenn es im Verhältnis zur Anzahl der Trainingsbeispiele zu viele Merkmale aufweist. Ein überangepasstes Modell kann bei den Trainingsdaten sehr gut abschneiden, wird aber bei neuen, ungesehenen Daten wahrscheinlich eine schlechte Leistung zeigen.
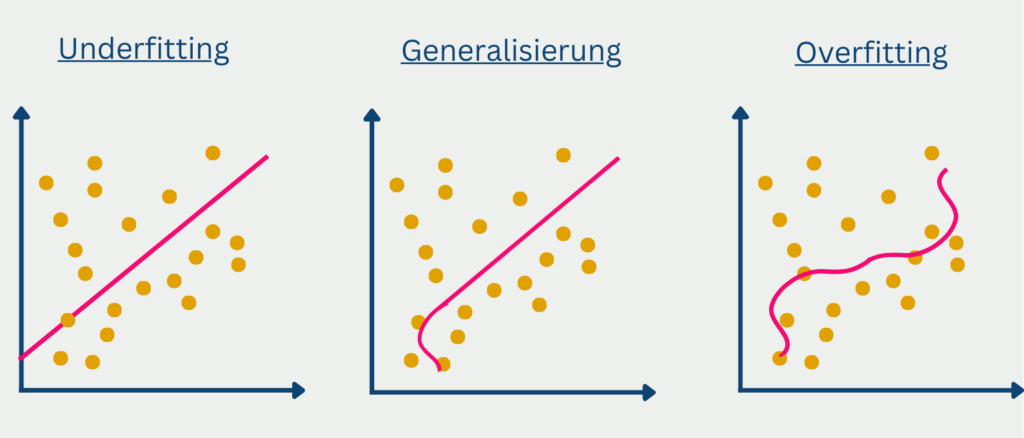
Um festzustellen, ob ein Modell unter- oder überangepasst ist, ist es wichtig, seine Leistung sowohl im Trainings- als auch im Validierungssatz zu bewerten. Wenn das Modell einen hohen Fehler in der Trainingsmenge aufweist, ist es möglicherweise unzureichend angepasst, und wenn es einen hohen Fehler in der Validierungsmenge aufweist, ist es möglicherweise überangepasst.
Um die Unteranpassung zu beheben, kann es notwendig sein, die Komplexität des Modells zu erhöhen oder ihm mehr Merkmale hinzuzufügen. Um eine Überanpassung zu vermeiden, können Regularisierungstechniken wie L1- und L2-Regularisierung verwendet werden, um große Gewichte zu bestrafen und die Komplexität des Modells zu reduzieren. Auch andere Techniken wie frühzeitiges Stoppen, Dropout und Pruning können eingesetzt werden, um eine Überanpassung zu verhindern.
Zusammenfassend lässt sich sagen, dass Underfitting und Overfitting häufige Probleme beim maschinellen Lernen sind, die die Leistung eines Modells beeinträchtigen können. Während Underfitting auftritt, wenn ein Modell zu einfach ist und die zugrunde liegenden Muster in den Daten nicht erfassen kann, tritt Overfitting auf, wenn ein Modell zu komplex ist und Rauschen in den Daten erfasst. Um diese Probleme zu lösen, ist es wichtig, die Leistung des Modells sowohl für die Trainings- als auch für die Validierungsdaten sorgfältig zu bewerten und geeignete Techniken wie die Regularisierung einzusetzen, um die Komplexität des Modells anzupassen.
Wie kann man eine unzureichende Anpassung von Modellen erkennen?
Die Erkennung von unzureichender Anpassung in Modellen des maschinellen Lernens ist für die Verbesserung der Leistung des Modells von entscheidender Bedeutung. Eine der einfachsten Möglichkeiten, dies festzustellen, besteht darin, die Leistung des Modells in der Trainingsmenge und der Validierungsmenge zu beobachten. Wenn das Modell in beiden Gruppen schlecht abschneidet, ist es wahrscheinlich, dass das Modell die Daten nicht richtig erfasst. Im Folgenden werden einige der üblichen Methoden zur Erkennung von Underfitting in Modellen beschrieben:
- Leistungsmetriken: Leistungsmetriken wie Genauigkeit, Präzision, Rückruf, F1-Score und die AUC-ROC-Kurve können zur Bewertung der Modellleistung verwendet werden. Wenn die Leistungskennzahlen niedrig sind, kann dies darauf hindeuten, dass das Modell die Daten nicht ausreichend anpasst.

- Lernkurven: Lernkurven sind Diagramme, die die Leistung des Modells in den Trainings- und Validierungssätzen mit zunehmendem Stichprobenumfang zeigen. Wenn sich das Modell nicht richtig anpasst, konvergieren die Lernkurven zu einem niedrigen Wert für beide Gruppen.
- Residualdiagramme: Residualdiagramme werden verwendet, um die Differenz zwischen den tatsächlichen und den vorhergesagten Werten der abhängigen Variable zu visualisieren. Wenn die Residualdarstellung eine zufällige Streuung um den Nullpunkt zeigt, deutet dies darauf hin, dass das Modell gut passt. Wenn jedoch ein Muster in der Residualdarstellung zu erkennen ist, kann dies darauf hinweisen, dass sich das Modell nicht gut anpasst.
- Feature Importance: Die Merkmalsbedeutung misst den Beitrag der einzelnen Merkmale im Modell. Wenn einige Merkmale eine sehr geringe Bedeutung haben, kann dies ein Hinweis darauf sein, dass das Modell unzureichend angepasst ist und die wichtigen Merkmale in den Daten nicht erfasst.
Die Erkennung einer unzureichenden Modellanpassung ist wichtig, da sie hilft, die Bereiche zu identifizieren, in denen das Modell verbessert werden muss. Sobald dies erkannt ist, kann das Modell durch Hinzufügen weiterer Merkmale, Erhöhung der Modellkomplexität oder Verwendung eines anderen Algorithmus zur Verbesserung der Modellleistung feinabgestimmt werden.
Welche Techniken gibt es, um Underfitting zu verhindern?
Um Underfitting zu verhindern, muss die Komplexität des Modells erhöht werden. Hier sind einige Techniken, um dies zu verhindern:
- Hinzufügen weiterer Merkmale: Das Hinzufügen weiterer relevanter Merkmale zum Modell kann die Komplexität des Modells erhöhen und dem Modell mehr Informationen für seine Vorhersagen liefern.
- Erhöhung der Modellkomplexität: Wenn das Modell zu einfach ist und die Muster in den Daten nicht erfassen kann, kann eine Erhöhung der Modellkomplexität helfen, ein Underfitting zu verhindern. Dies kann durch die Erhöhung der Anzahl der Schichten in einem neuronalen Netz, die Erhöhung der Anzahl der Entscheidungsbäume in einem Random Forest oder die Erhöhung des Grades der Polynomfunktionen bei der linearen Regression geschehen.
- Verringern der Regularisierung: Regularisierungstechniken wie L1 und L2 können eine Überanpassung verhindern, indem sie der Verlustfunktion einen Strafterm hinzufügen. In einigen Fällen kann eine zu starke Regularisierung jedoch zu einer Unteranpassung führen. Eine Verringerung der Regularisierungsstärke oder die vollständige Entfernung der Regularisierung kann helfen, dieses Problem zu vermeiden.
- Vergrößerung der Trainingsdatenmenge: Eine Vergrößerung der Trainingsdatenmenge kann helfen, Underfitting zu verhindern, indem dem Modell mehr Informationen zur Verfügung gestellt werden. Mit mehr Daten kann das Modell die zugrunde liegenden Muster in den Daten besser erfassen.
- Ensembling: Die Kombination mehrerer Modelle kann helfen, eine unzureichende Anpassung zu verhindern. Ensemble-Techniken wie Bagging, Boosting und Stacking können verwendet werden, um die Vorhersagen mehrerer Modelle zu kombinieren. Dies kann dazu beitragen, die Komplexität des Modells zu erhöhen.
Insgesamt ist es wichtig, ein Gleichgewicht zwischen Modellkomplexität und Überanpassung zu finden. Mit den richtigen Techniken und einer sorgfältigen Abstimmung der Hyperparameter kann eine Unteranpassung bei Modellen des maschinellen Lernens verhindert werden.
Das solltest Du mitnehmen
- Underfitting liegt vor, wenn ein Modell für maschinelles Lernen zu einfach ist und die Komplexität der Daten nicht erfassen kann, was zu einer schlechten Leistung sowohl bei Trainings- als auch bei Testdaten führt.
- Dies kann durch verschiedene Faktoren verursacht werden, z. B. durch einen Mangel an Merkmalen, eine zu vereinfachte Modellarchitektur oder eine unzureichende Trainingszeit.
- Dieses Problem lässt sich erkennen, indem man die Leistung des Modells bei den Trainings- und Testdaten beobachtet und mit der erwarteten Leistung vergleicht.
- Um eine unzureichende Anpassung zu verhindern, können verschiedene Techniken eingesetzt werden, z. B. die Erhöhung der Komplexität des Modells, das Hinzufügen weiterer Merkmale, die Verwendung einer leistungsfähigeren Modellarchitektur oder die Verlängerung der Trainingszeit.
- Es ist jedoch zu beachten, dass die Erhöhung der Modellkomplexität vorsichtig erfolgen sollte, da sie zu einer Überanpassung führen kann, die ein weiteres Problem beim maschinellen Lernen darstellt.
- Die Komplexität des Modells mit den verfügbaren Daten und der gewünschten Leistung in Einklang zu bringen, ist ein wichtiger Aspekt des maschinellen Lernens, und das Verständnis der Unteranpassung ist ein wichtiger Schritt, um dieses Gleichgewicht zu erreichen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.

Was ist der Conjugate Gradient?
Erforschen Sie den Conjugate Gradient: Algorithmusbeschreibung, Varianten, Anwendungen und Grenzen.

Was ist ein Elastic Net?
Entdecken Sie Elastic Net: Die vielseitige Regularisierungstechnik beim Machine Learning für bessere Modellbalance und Vorhersagen.

Was ist Adversarial Training?
Sicheres maschinelles Lernen: Erklärung von Adversarial Training, dessen Anwendungen und Probleme.
Andere Beiträge zum Thema Underfitting
Scikit-Learn hat einen interessanten Artikel über die Unterschiede zwischen Overfitting und Underfitting.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.