Das CAP Theorem beschreibt insgesamt drei Eigenschaften von Datenbanken auf verteilten Systemen, die nie alle gleichzeitig erfüllt sein können. CAP steht dabei als Abkürzung für die englischen Begriffe “Consistency”, “Availability” und “Partition Tolerance” oder auf deutsch “Konsistenz”, “Verfügbarkeit” und “Partitionstoleranz”. Dieses Theorem gilt vor allem für Datenbanken, die auf mehreren Systemen verteilt sind und in den Bereich der NoSQL-Datenbanken zählen. Für klassische relationale Datenbanken hingegen findet das sogenannte ACID Prinzip Anwendung.
Was sind NoSQL Datenbanken?
NoSQL (“Not Only SQL”) beschreibt Datenbanken, welche im Gegensatz zu SQL nicht-relational sind, also unter anderem nicht in Tabellen organisiert werden können. Diese Ansätze lassen sich auch über verschiedene Computersysteme verteilen und sind dadurch höchst skalierbar. NoSQL Lösungen sind deshalb sehr interessant für viele Big Data Anwendungen.
Die Datenbanken zeichnen sich vor allem durch zwei Kriterien aus, die sehr weit gefasst sind. Zum einen werden Daten nicht in Tabellen gespeichert und zum anderen ist die Abfragesprache nicht SQL, was auch durch den Namen “Not Only SQL” deutlich wird.
NoSQL Lösungen lassen sich in eine der vier Kategorien einteilen:
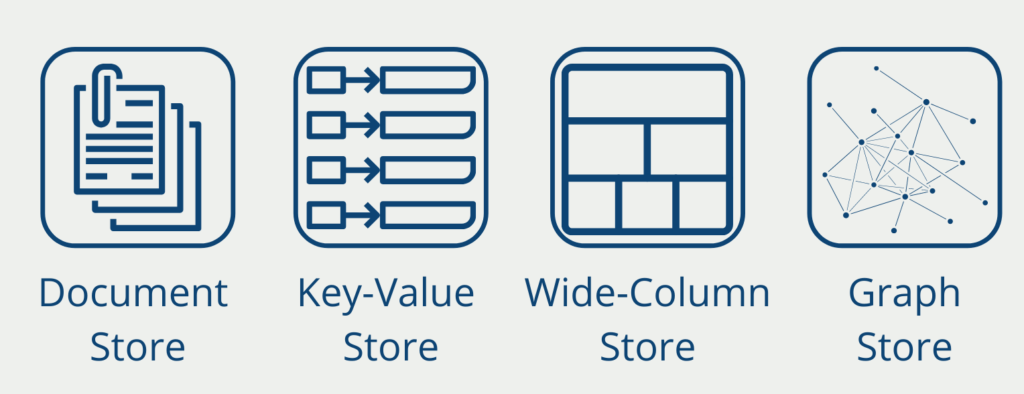
- Document Stores speichern eine Vielzahl von Informationen innerhalb eines Dokumentes. Ein Dokument könnte beispielsweise alle Daten eines Tages enthalten.
- Key-Value Store sind eine sehr einfach Datenstruktur in der jeder Datensatz als Wert mit einem einzigartigen Schlüssel abgespeichert ist. Über diesen Schlüssel können die Informationen gezielt abgefragt werden.
- Wide-Column Store speichern einen Datensatz in einer Spalte ab und nicht wie sonst in einer Zeile. Sie sind dafür optimiert worden schnell Daten in großen Datensätzen zu finden.
- Graphdatenbanken speichern Informationen in sogenannten Knoten und Kanten ab. Dadurch lassen sich beispielsweise soziale Netzwerke sehr gut darstellen, in denen die Personen einzelne Knoten sind und die Beziehung untereinander als Kante dargestellt werden.
Was bedeuten die Eigenschaften des CAP Theorems?
Im Kern besteht CAP aus den folgenden drei Eigenschaften:
- Die Konsistenz beschreibt den Umstand, dass die Daten in der Datenbank zu jedem Zeitpunkt konsistent sein müssen. Das bedeutet, dass es zu keinerlei Unregelmäßigkeiten beim Abruf der Daten kommen darf, egal welcher der Knoten angesprochen wird. Praktisch bedeutet dies beispielsweise, dass beim Einfügen eines neuen Datensatzes die Datenstände auf allen Knoten gleichzeitig stattfinden muss.
- Verfügbarkeit bedeutet, dass das verteilte System immer eine Rückantwort liefert, auch wenn möglicherweise gerade einzelne Knoten ausgefallen sind. Dies ist unabhängig davon, welchen Knoten man im System anspricht. Somit bekommt man auch eine Antwort, wenn man zufülligerweise einen ausgefallenen Knoten angesprochen hat. Das System als ganzes ist somit durchgehend verfügbar.
- Die Partitionstoleranz, oder auch Ausfalltoleranz genannt, beschreibt die Fähigkeit, dass Anfragen stets richtig und komplett bearbeitet werden, selbst wenn es während des Prozesses zu Kommunikationsausfällen gekommen ist.
Es lässt sich axiomatisch zeigen, dass diese Eigenschaften in verteilten Systemen unter keinen Umständen gleichzeitig erfüllt sein können. Deshalb bildete sich das CAP Theorem, welches besagt, dass man sich beim Aufbau von verteilten Datenbanken auf zwei der Eigenschaften beschränken muss und die dritte Eigenschaft damit auf jeden Fall missachtet werden wird.
Was bedeutet das CAP Theorem in der Praxis?
Das CAP Theorem besagt, dass man sich beim Aufbau von verteilten Systemen auf zwei der drei genannten Eigenschaften beschränken muss. In der Praxis bedeutet dies, dass es insgesamt drei Möglichkeiten gibt, welche Eigenschaften gleichzeitig erfüllt sind. Diese werden wir uns im folgenden genauer anschauen.
CA – System
Die Relationalen Datenbanken stellen ein klassisches Beispiel für Systeme dar, die zwar konsistent und verfügbar, jedoch nicht partitionstolerant sind. Sie können nämlich nicht über mehrere Knoten verteilt werden, da ansonsten die Konsistenz der Daten nicht mehr gegeben wäre.
Falls man jedoch die Relationale Datenbank auf mehrere Systeme verteilen will bekommt man schnell Probleme mit der Konsistenz. Damit man die Daten zu jedem Zeitpunkt abfragen kann, könnte man die Daten auch teilweise duplizieren und sie auf mehreren Servern ablegen. Wenn sich jedoch an den duplizierten Daten etwas ändert, dann ist technisch nur sehr schwer möglich, die beiden Datensätze genau zum gleichen Zeitpunkt zu ändern. In dem kurzen Moment der Änderung herrscht dann also eine Inkonsistenz.
AP – System
Bei einem AP – System wird sichergestellt, dass die Datenbank immer erreichbar und ausfalltolerant ist. Ein bekanntes Beispiel dafür ist der sogenannte Domain Name Server. Die Websites, die wir im Internet ansprechen, werden eigentlich durch IP-Adressen definiert. Da dies für den Menschen jedoch nicht so einfach zu merken ist, verwendet man die Alias-Namen, die wir beispielsweise als “www.databasecamp.de” kennen. Im Domain Name Server ist die Übersetzung von IP-Adresse in die URL gespeichert.
Da wir weltweit auf das Internet zugreifen, ist das DNS System auch auf tausenden Servern verteilt. Bei einer Änderung der URL kann es sogar mehrere Tagen dauern, bis die Änderung auf allen weltweiten Servern vorgenommen wurde. In dieser Zeit ist das System inkonsistent, denn es kann passieren, dass bei Abfrage eines Servers noch die alte URL ausgegeben wird, während ein anderer Server bereits die neue URL ausgibt. Das ist eindeutig eine Inkonsistenz.
CP – System
In der Praxis ist die Verfügbarkeit ein sehr wichtiger Faktor, der nur ungern eingetauscht wird. Man stelle sich nur vor bei jeder dritten Seite, die man im Internet aufruft, würde der Domain Name Server nicht funktionieren. Das ist ein Szenario, welches es zu verhindern gilt. Deshalb sind in der Praxis Systeme, die konsistent und ausfallsicher sein müssen, eher selten.
Für einzelne Anwendungen sind diese Eigenschaften jedoch unverzichtbar. Im Finanz- und Bankenbereich beispielsweise ist die Konsistenz und die Ausfallsicherheit von immenser Bedeutung, damit keine fehlerhaften Überweisungen stattfinden und die Guthaben auch immer richtig sind. Die Verfügbarkeit spielt dabei eine eher untergeordnete Rolle, da man schließlich einfach die Transaktion nochmals wiederholen kann, falls das System beim ersten Versuch nicht verfügbar war.
Was ist ACID?
Im Bereich von Data Science werden die Akronyme CAP Theorem und ACID häufig durcheinander gebracht, vor allem weil sich beide mit der Konsistenz beschäftigen. Bevor wir uns jedoch der Unterscheidung zuwenden können, sollten wir uns zuerst genauer mit ACID beschäftigen.
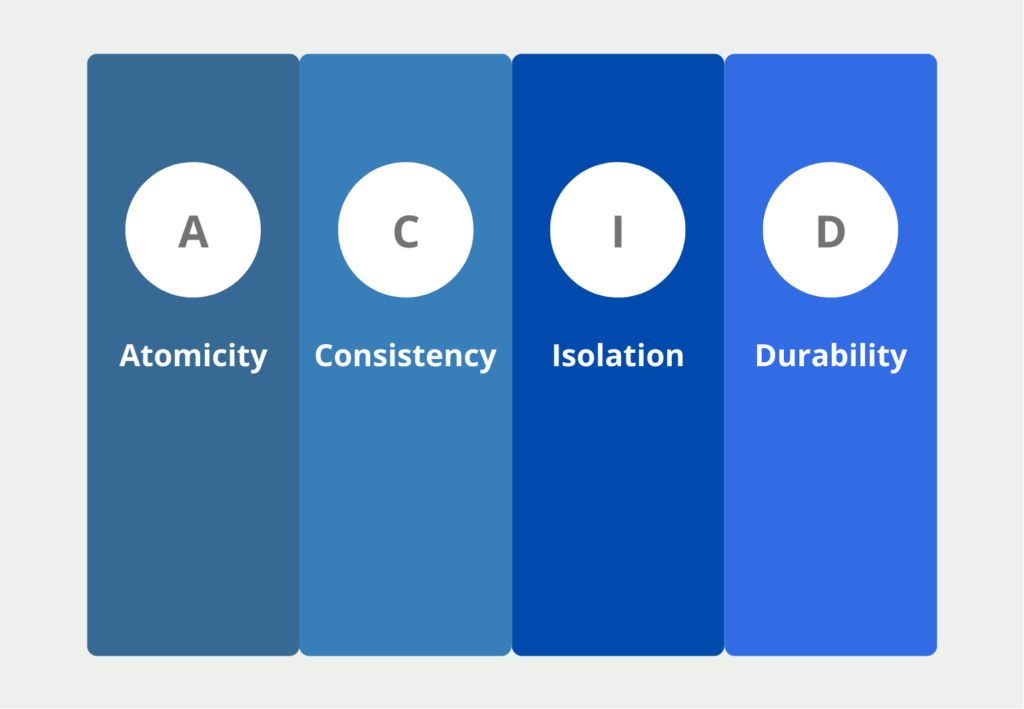
Klassische relationale Datenbanken erfüllen die vier ACID Eigenschaften. Diese besagen, dass die wichtigste Anforderung an eine Datenbank ist, den Wahrheitsgehalt und die Aussagekraft der Daten zu erhalten. In vielen Fällen werden Datenspeicher als „Single Point of Truth“ gesehen, somit wäre es fatal, wenn fehlerhafte Informationen gespeichert und weitergegeben werden. Die vier Eigenschaften umfassen die folgenden Punkte:
- Atomicity (A): Datentransaktionen, bspw. die Eintragung eines neuen Datensatzes oder das Löschen eines alten, sollen entweder ganz oder gar nicht ausgeführt werden. Für andere User ist die Transaktion erst sichtbar, wenn sie vollständig ausgeführt ist.
- Consistency (C): Diese Eigenschaft ist erfüllt, wenn jede Datentransaktion die Datenbank von einem konsistenten in einen konsistenten Zustand überführt.
- Isolation (I): Wenn mehrere Transaktionen gleichzeitig stattfinden, muss der Endzustand derselbe sein, als wenn die Transaktionen getrennt voneinander stattfinden würden. Das heißt die Datenbank sollte den Stresstest bestehen. Also nicht durch Überlastung zu falschen Datenbanktransaktionen kommen.
- Durability (D): Die Daten innerhalb der Datenbank dürfen sich nur durch eine Transaktion ändern und nicht durch äußere Einflüsse veränderbar sein. Ein Softwareupdate darf beispielsweise nicht versehentlich dazu führen, dass sich Daten ändern oder womöglich gelöscht werden.
CAP Theorem vs. ACID
Kurz gesprochen unterscheiden sich das CAP Theorem und die ACID Eigenschaften darin, dass sich CAP mit verteilten Systemen beschäftigt, wohingegen ACID Aussagen über Datenbanken trifft. Wir wollen an dieser Stelle jedoch noch mehr ins Detail gehen.
Beide Konzepte beschäftigen sich mit der Konsistenz von Daten, jedoch unterscheiden sie sich darin, welche Auswirkungen diese hat. Bei ACID ist die Datenkonsistenz im Bereich von (relationalen) Datenbanken gemeint. Das bedeutet, dass die Daten konsistent sind, sobald im System jedoch widersprüchliche Daten vorhanden sind, ist die Datenbank inkonsistent. Das kann beispielsweise durch fehlerhafte Dupletten vorkommen, muss es jedoch nicht. Es greift dabei viel tiefer und inkludiert darin auch die Verflechtungen zwischen Tabellen und die Logik dahinter, wie beispielsweise Fremd- und Primärschlüssel.
Im CAP Theorem hingegen bedeutet die Konsistenz, dass das verteilte System bei einer Abfrage immer dasselbe Ergebnis ausgibt. Das bedeutet, dass es Dupletten geben darf auf verschiedenen Servern, diese müssen jedoch immer denselben Stand haben, damit es zu keinen Differenzen kommen kann. Dann ist die Konsistenz im CAP Theorem erfüllt.
Das solltest Du mitnehmen
- Das CAP Theorem beschreibt, dass ein verteiltes System niemals die drei Eigenschaften Konsistenz, Verfügbarkeit und Ausfalltoleranz gleichzeitig erfüllen kann. Es können lediglich zwei der genannten Attribute in einem System vorhanden sein.
- Das CAP Theorem ist vor allem für NoSQL Datenbanken interessant, da diese sehr oft auf mehreren Servern verteilt abgespeichert werden.
- Das CAP Theorem sollte nicht mit den ACID Eigenschaften von relationalen Datenbanken verwechselt werden. Diese unterscheiden sich vor allem in der unterschiedlichen Definition von Konsistenz.

Vector Database einfach erklärt: Embeddings, semantische Suche und RAG
Warum eine normale Suche oft am richtigen Dokument vorbeiläuft Stell dir vor, in deinem Unternehmen gibt es ein internes Support-Wiki mit FAQ-Artikeln. Ein Kollege tippt in die Suche: „Wie kann ich mein Passwort zurücksetzen?“ Die Suche liefert null Treffer. Dabei gibt es genau den passenden Artikel – er trägt nur den Titel „Zugangsdaten erneuern“. Genau… Weiterlesen »Vector Database einfach erklärt: Embeddings, semantische Suche und RAG
SQL Tutorial für Anfänger: SELECT, JOIN, GROUP BY einfach erklärt
SQL Tutorial Deutsch: Warum SQL noch immer unverzichtbar ist Ob im sql tutorial deutsch für Studierende oder im Berufsalltag von Data Analysts – SQL ist die Sprache, mit der du relationale Datenbanken abfragst und auswertest. Fast jedes Unternehmen speichert strukturierte Daten in Datenbanken, und wer diese Daten verstehen will, kommt an SQL nicht vorbei. In… Weiterlesen »SQL Tutorial für Anfänger: SELECT, JOIN, GROUP BY einfach erklärt

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.
Andere Beiträge zum Thema CAP Theorem
IBM hat einen ausführlichen Artikel zum Thema CAP Theorem geschrieben, der hier verfügbar ist.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.