MongoDB is an open-source, non-relational database solution that is categorized as a NoSQL system and can be used for Big Data applications. MongoDB was first introduced in 2009 and works with so-called collections and documents, which in turn contain various key-value pairs that ultimately store the data.
What are NoSQL Databases?
The principle of NoSQL (“Not only SQL”) first appeared at the end of the 2000s and generally refers to all databases that do not store data in relational tables and whose query language is not SQL. The best-known examples of NoSQL databases, besides MongoDB, are Apache Cassandra, Redis or Neo4j.
NoSQL databases can scale significantly higher than conventional SQL solutions due to their structure, as they can also be distributed across different systems and computers. In addition, most solutions are open-source and enable database queries that relational systems could not cover.
NoSQL solutions fall into one of four categories:
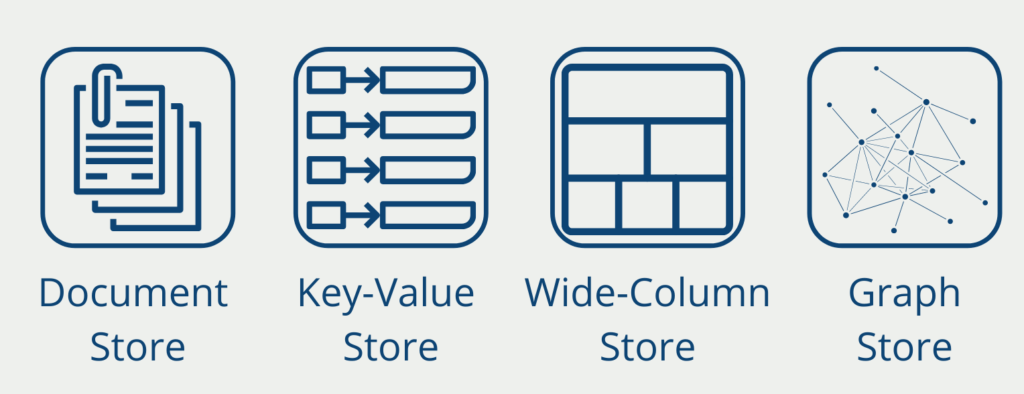
- Document Stores store a variety of information within a document. For example, a document could contain all the data for one day.
- Key-value Stores are very simple data structures in which each record is stored as a value with a unique key. This key can be used to retrieve specific information.
- Wide-Column Stores store a data record in a column and not as usual in a row. They have been optimized to quickly find data in large data sets.
- Graph Databases store information in so-called nodes and edges. This makes it very easy to represent social networks, for example, in which people are individual nodes and the relationship between them is represented as an edge.
Structure of MongoDB Databases
MongoDB contains many so-called collections, which are comparable to the tables of relational databases. In a collection, there can be several so-called documents, which in turn correspond to the records in a table to stay with this analogy. The really exciting and new thing happens in the documents themselves. That’s why we’ll take a closer look at them.
The documents contain several key-value pairs that store the actual data. The values can contain different data types (string, integer, float, etc.) and at the same time, a key can have two different data types in two different documents. In the relational database data model, this would not be possible in two rows of one column.
In the current implementation, MongoDB only allows 8MB data size per document. After subtracting the storage space for the file overhead, there is not too much storage space left for the dataset. However, MongoDB uses a binary data format built on JSON, which makes it much more memory-friendly than text-based file formats. By its name, BSON, this data format is based on its origin (“Binary JSON”).
What is the MongoDB File Format?
BSON is the binary file format of JSON and optimizes it in some aspects. Original file formats, like CSV, XML, or also JSON, are so-called text-based formats. They store data in plain text. This makes them easy to understand for us humans, but requires a comparatively large amount of storage space. As Big Data projects have become more prominent in recent years, binary data formats have become more interesting.
These store parts or even all of the data in binary notation, making them unreadable to us humans for the time stored. This means that opening and saving such files takes a little more time, since the information first has to be processed, but the storage space is smaller and queries are sometimes more performant. BSON files store the keys as binary values. The values, however, are still kept as text, while the metadata is stored in binary and thus can be read faster than text keys. Here is an example of a simple JSON dictionary and the corresponding BSON file:
{"hello": "world"} →
x16x00x00x00 // total document size
x02 // 0x02 = type String
hellox00 // field name
x06x00x00x00worldx00 // field value
x00 // 0x00 = type EOO ('end of object')As we can see, the BSON file adds some additional metadata to the original format, such as the data type. This may look much more elaborate for small files, but it proves its worth for very large files by reducing the reading speed.
Which NoSQL Category does MongoDB belong to?
MongoDB belongs to the so-called document stores, which is a subtype of NoSQL databases. They are non-relational, as the data is not stored in rows and columns but in the documents. Document stores are among the most popular subcategory of NoSQL compared to traditional relational databases. The advantages of the application include:
- Easy applicability for developers also due to the understandable data model.
- Flexible data schema, which can be easily changed even after the initial creation of the database.
- Horizontal scalability of the database with increasing data volume or accesses.
What are the Advantages of MongoDB?
MongoDB, like other NoSQL solutions, delivers many advantages over classic relational databases for large data sets:
- Load balancing: These databases can be distributed across different virtual machines and thus still remain relatively performant even with a large number of simultaneous queries or with large data volumes. Relational databases, on the other hand, cannot be distributed across multiple machines due to their fundamental properties (ACID). As a result, a machine must be made more powerful if it has to process any queries. In most cases, this is more expensive and more complex than spreading the load over one system.
- Flexible data formats: As we have already highlighted, MongoDB can store much more flexible data schemas than relational databases. Each key can theoretically have its own data format.
- Support in many programming languages: MongoDB has now been developed and supported for many programming languages, such as Python, PHP, Ruby, Node.js, C++, Scala, JavaScript, and many more. This makes it easy to integrate the database for a wide variety of application projects and in their programming language without having to switch to another language.
How does MongoDB store data?
MongoDB databases can actually be used for almost all application areas in which one could store data in a JSON format. These can then be relatively easily “translated” into the BSON format and stored in a MongoDB. The structure of the BSON file does not specify any structure of the data and flexible schemas can be stored.
If we want to draw the analogy to relational databases, the individual documents are the rows in a relational database, i.e. records. The fields within the BSON file contain data of a certain data type and are thus best compared with the columns in a table. Finally, documents with similar information content and structure are stored in so-called collections, which can be thought of as tables in relational databases.
A classic example of this is user movement data on a website. Each user journey is different from the other and therefore does not offer a fixed data schema. For example, a user on an e-commerce site places an order and logs into the system. The next user, on the other hand, finds out about the latest job offers in the company’s career section. In a JSON file, this can be mapped relatively easily via the keys and thus also stored in MongoDB. In a relational database, the same use case would not be so easy to map.
Other conceivable areas of application include backend data from app applications, a content management system for websites, or even a company’s complete data warehouse.
Is MongoDB suitable for Big Data Applications?
The term Big Data is on everyone’s lips these days when trying to describe the phenomenon that companies and public organizations in particular have an ever-increasing amount of data at their disposal, which is pushing traditional databases in particular to their limits.
MongoDB is definitely a possible system to realize Big Data applications. In this context, it impresses above all with the aforementioned horizontal scalability and the flexible data schema. Furthermore, it has a storage engine that handles the memory very efficiently and compresses the documents, for example.
However, the main advantage is that MongoDB supports dynamic querying. In short, this means that the data query statements are not created until the query has already been started. This offers the advantage of writing flexible programs that react to the current situation. Imagine you run an online store and a customer is just about to log in. Only after the customer has entered his credentials and pressed the login button, the program can decide in which document the information about the customer has to be searched.
Thus, MongoDB is particularly well suited in the area of Big Data when the data still needs to be changed between storage and query, i.e. aggregated, for example.
This is what you should take with you
- MongoDB is an application of a NoSQL database.
- It stores so-called collections, which in turn contain documents with the actual data as key-value pairs.
- MongoDB is especially suitable for applications that need to be highly scalable, have a flexible data schema, and store large amounts of data.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of MongoDB
- You can find the documentation of MongoDB here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.