Normalization refers to a concept from database design to eliminate redundancies, i.e. duplications in the database. This saves storage space and also prevents anomalies from occurring.
What is a relational database?
In a database, large amounts of data, usually structured, are stored and made available for query. It is almost always an electronic system. Theoretically, however, analog information collections, such as a library, are also databases. As early as the 1960s, the need for central data storage arose because things such as access authorization to data or data checking should not be done within an application, but separately from it.
The most intuitive way to store this information is in tabular form, with rows and columns. For many data, such as in accounting, this representation is also suitable, since the data always have a fixed form. Such databases in tabular form are called relational databases, derived from the mathematical concept of relations.
What are the goals of normalizing the database?
Normalization of a database is intended to achieve the following goals:
- Elimination of redundancies: Normalization allows duplicate data to be deleted without the database itself losing information content. This saves storage resources and thus also leads to faster queries. It also reduces the potential for errors, since all redundant records would always have to be changed when a change is made.
- Data model: Normalization often also automatically results in a clear and uniform data model. This is because a large table is often divided into several, manageable tables, resulting in familiar schemas such as the star schema or snowflake schema.
What are the normal forms?
In practice, three normal forms are of particular importance. Because often, if these are fulfilled, the database is performant, and only relatively little work had to be invested. Thus, the cost-benefit ratio is comparatively high up to the third normal form. In theory, however, there are up to five normal forms, but in this article, we will limit ourselves to the first three.
Here it is also important that the normal forms build on each other. This means that a high normal form is only fulfilled if all (!) preceding normal forms are also fulfilled.
1. Normal Form (1NF)
The 1st normal form is achieved when all records are atomic. This means that each data field may contain only one value. It should also be ensured that each column contains only values of the same data type (numeric, text, etc.). The following examples would have to be modified accordingly to have a database in 1st normal form:
- Address: “Main Street 1, 12345 Berlin” –> Street: “Main Street”, House number: “1”, Zip code: “12345”, City: “Berlin”.
- Invoice amount: “128,45 €” –> Amount: “128,45”, Currency: “€”.
2. Normal Form (2NF)
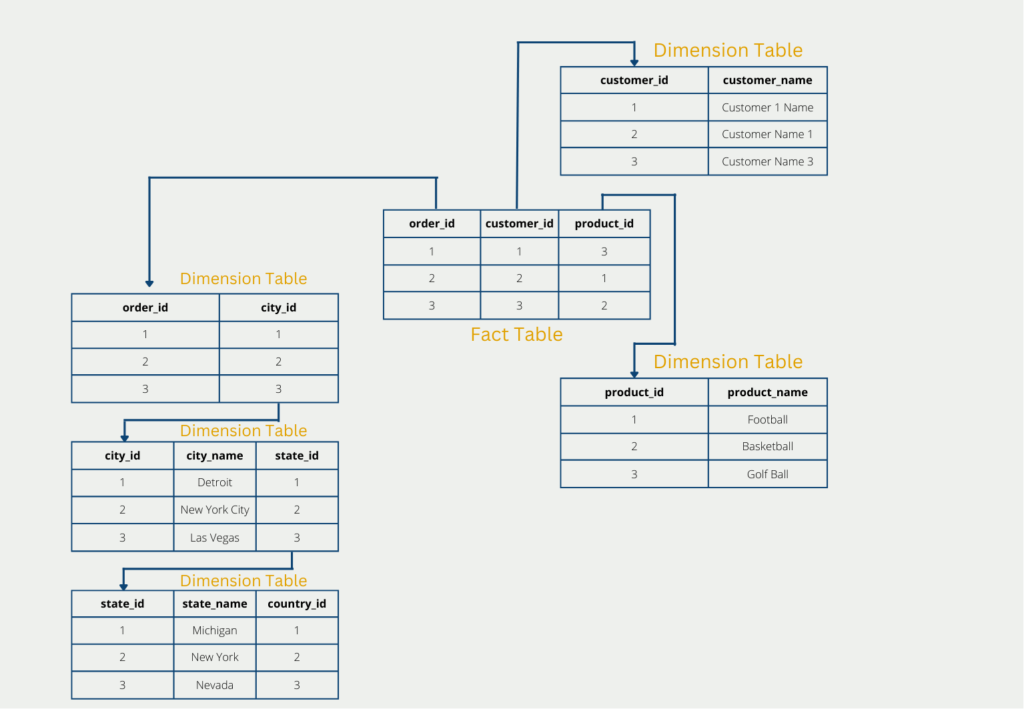
The 2nd normal form is satisfied if the first normal form is satisfied, and also each column in a row is fully functionally dependent on the primary key. The primary key denotes an attribute that can be used to uniquely identify a database row. This includes, for example, the invoice number to identify an invoice or the ID number to identify a person.
In concrete terms, this means that all characteristics that are not exclusively dependent on the primary key must be outsourced. In practice, this often leads to a so-called star schema.
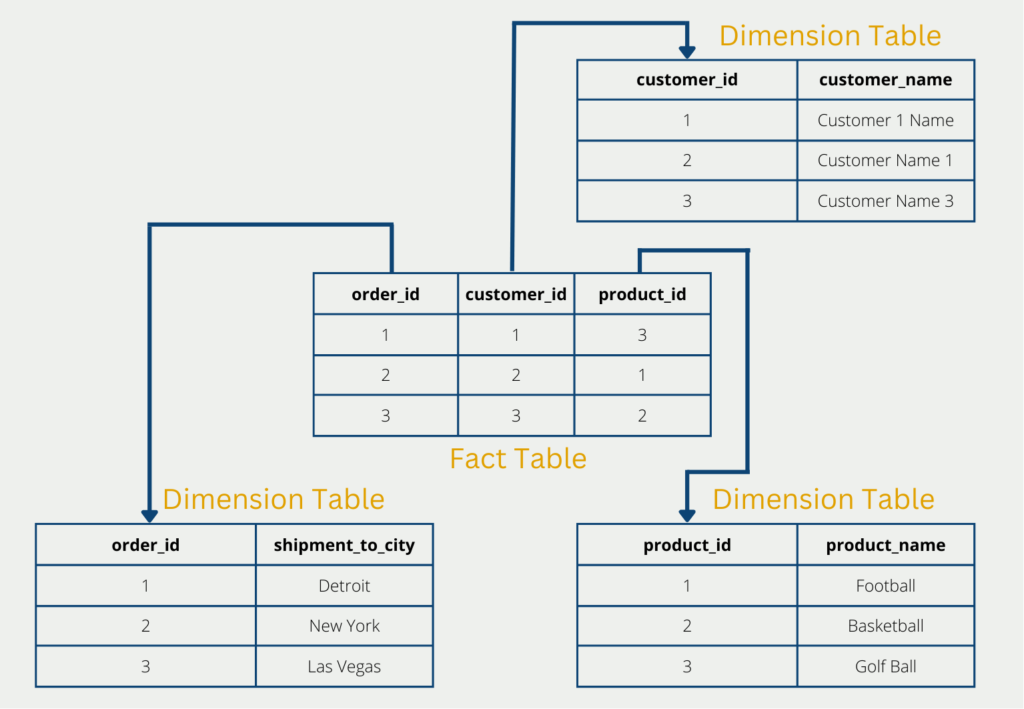
In our example, the customer name does not depend on the primary key “order_id” of the original table. Therefore, the customer name must be swapped out in a new table. Only the foreign key “customer_id” then references the new table, so no information is lost.
3. Normal Form (3NF)
The third normal form is present, if the two preceding normal forms are fulfilled, and there are additionally no so-called transitive dependencies. A transitive dependency exists if an attribute that is not a primary key not only depends on it but also other attributes.
In our example, if we have a table where the invoice number, the product number, and the price are given, we most likely have a transitive dependency. The price of the product does not depend on the invoice number, but rather on the product number, since a fixed price is defined for each product.
This dependency can be resolved by moving the products to a new table, thus removing the price attribute from the original table.
What are the limitations of Normalization?
Relational databases are converted into various normal forms to ensure data integrity and efficient data storage. However, normal forms not only offer considerable advantages but also have limitations that should be taken into account when working with databases. In this chapter, we look at the limitations of database normalization and what considerations should be made in advance:
- Performance impact: A normalized database can have a strong impact on query performance. As the form increases, more complex joins and more queries are required to retrieve data. This leads to significantly slower queries, especially with large amounts of data. This is further exacerbated by the fact that normalization requires more tables, introducing additional complexity.
- Data redundancy: The main aim of normalization is to eliminate data redundancy by splitting the data into different tables. In addition to the additional complexity, this also leads to significant performance losses when querying data. So-called denormalization techniques can therefore be used to allow a certain amount of data redundancy while maintaining performance.
- Increased complexity: The increased complexity of normalization leads above all to more elaborate and extensive query constructions. This means that users must have sufficient knowledge of SQL and database design to query the data correctly. In addition, administrators must also be familiar with the normalization principles to manage the database effectively.
- Maintenance challenges: The maintenance and administration of a normalized database should not be underestimated. This is because the modification or deletion of data can also require operations in various tables. If these do not take place, the risk of inconsistencies is high.
- Flexibility and adaptability: In addition to maintenance, expansion, and adaptation naturally also become significantly more complex. The addition of new attributes or changes in the data structure usually requires changes in different tables due to normalization.
- Balance between normalization and performance: A higher form of normalization is not always the optimal choice for a database system. A balance between sufficient normalization/data integrity and denormalization for optimal performance must be found on a case-by-case basis.
- Compromises in reporting and analysis: In addition to the data storage itself, subsequent processes, such as reporting, should also be taken into account when designing databases. Normalization can also hurt performance if it takes significantly longer to aggregate the data.
- Context-specific considerations: Normalization should be examined on a case-by-case basis for the application and an appropriate decision made. This includes, for example, checking the data types and whether they should be normalized. In the case of protocols, for example, higher normalization levels may not be advantageous.
While the normalization of database systems ensures data integrity, it also has a major impact on working with databases. Therefore, a careful evaluation of the trade-offs between normalization and performance is essential. Only then is effective data management possible.
What is the concept of Denormalization?
Denormalization is a method of optimizing database performance by introducing targeted redundancies into a normalized database schema. While normalization tries to eliminate these redundancies, denormalization uses them specifically to improve query performance and increase the efficiency of the system.
By deliberately duplicating tables or using a less compartmentalized structure, the need for complex joins when querying data is reduced, thus increasing query performance. Various techniques are used for denormalization, such as
- Flattening tables: This involves combining multiple tables into a single one to reduce the need for joins. This significantly simplifies queries and improves performance as fewer read operations are required.
- Adding redundant data: In this approach, data is duplicated from a table to reduce the need for joins. This also improves query performance. This method is particularly useful for frequently queried information.
- Introduce derived columns: Another means of denormalization is the introduction of calculating columns, which can contain derived or calculated values. This means that these do not have to be calculated live during the query, which in turn improves performance.
Denormalization is mainly used in applications where query performance is of great importance, such as data warehousing and business intelligence. However, it must of course be noted that these methods can lead to data inconsistencies. In addition, the storage requirements are also higher, as data is stored twice.
Just like normalization, the use of denormalization should also be well thought out and used depending on the use case. No general statement can be made as to whether normalization or denormalization should always be used. Rather, a healthy balance should be found between the two extremes that meet the requirements.
This is what you should take with you
- Normalization of a database means the systematic elimination of redundancies.
- The normalization saves storage space and improves the performance of queries.
- In practice, only the first three normal forms are often implemented, since these have the highest cost-benefit ratio.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Normalization
On Wikipedia, there is a detailed article about the normalization of databases.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.