The term Big Data is on everyone’s lips these days when trying to describe the phenomenon that companies and public organizations in particular have an ever-increasing amount of data at their disposal, which is pushing traditional databases to their limits.
Definition Big Data
The Gartner IT Dictionary defines Big Data as follows:
“Big Data is high-volume, high-speed, and/or high-variant information assets that require cost-effective, innovative forms of information processing that enable improved insights, decision-making, and process automation. “
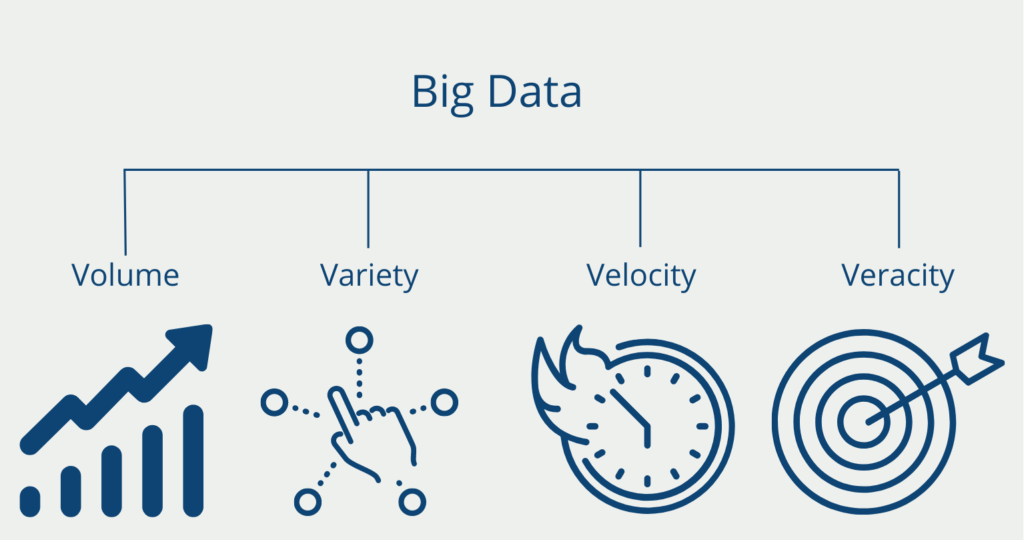
4 V’s of the data
Although it is difficult to capture exactly what makes a Big Data system “big”, a total of four concepts are used to identify such systems. Derived from their names, these are also referred to as the 4 V’s of Big Data:
- Volume: Big Data applications from companies such as Netflix, Amazon, or Facebook comprise enormous amounts of data, which are already measured in orders of tera- or even zettabytes. In some cases, thousands of machines are required to store and process such large amounts of data. In addition, for security reasons, the data is replicated so that it can be accessed in the event of a failure, which increases the amount of data even more.
- Variety: The data not only comes from a variety of data sources (e.g., image data, audio data, etc.) but also has a wide variety of data structures. The information must be converted into formats so that they can be used together. For example, a uniform schema must be agreed upon for the specification of data.
- Velocity: Velocity refers to the speed of data processing. Typical Big Data systems store and manage large amounts of data at ever-increasing speeds. The speed at which new data is generated, modified, and processed is a challenge. Users of social networks such as Twitter, Facebook, or YouTube are constantly producing new content. This includes not only millions of tweets posted every hour, but also tracking information, for example, the number of views or users’ GPS data.
- Veracity: Human-produced data can be unreliable. Posts on social networks or blogs can contain incorrect information, contradictions, or just plain typos. All of this makes it difficult for algorithms to extract value from the data. The challenge is to identify which data is trustworthy and which is not. Algorithms are used to measure data quality and perform data cleansing steps.
Depending on the literature, Big Data is defined with only three Vs, namely Volume, Velocity, and Variety. In other definitions, even more, Vs are mentioned. One example is “Value”, which means that Big Data should be used to extract meaningful values from data, e.g. by applying machine learning algorithms.
Which Applications use Big Data?
In many industries and use cases, the use of big data is already commonplace. The following examples are based on the analysis of big data:
- Further development of products: In many industries, customer reviews and preferences can be incorporated into new products on a large scale. Reviews from online stores, behavior on the website, or posts on social media can be used to find out which features of the product should still be improved.
- Personalization of marketing strategies: A large amount of data available for an individual customer is used, especially in e-commerce, to make marketing even more targeted and thereby persuade the customer to buy. The increasingly widespread use of specific loyalty cards in offline retailing also confirms this trend. This allows purchases to be specifically assigned to a person and evaluated. In most cases, however, the benefits that the customer receives in return are significantly lower than the profit that the company can make from the data.
- Predictive maintenance: Many production processes contain parts that wear out over time. If severe wear is detected too late, it can lead to very expensive consequential damage, which can also be easily avoided. To this end, many sensors are used to measure signs of wear and give an early warning when a part is nearing the end of its life cycle.
Where does the Data come from?
In traditional information systems (such as those used in banks or insurance companies), the data was mainly collected by the company’s employees. In Big Data applications, the data originates from more diverse sources. In today’s world, a wide variety of data is generated in almost all industrial sectors and company sizes. In addition to digitally active companies, the manufacturing sector also collects information from a wide variety of sources:
- “Classic” data: This is data that companies are required to collect by law anyway, or have been collecting for some time due to general interest. This includes, for example, all information about an order that is found on an invoice (order number, sales, customer, products purchased, etc.).
- Multimedia sources: Videos, music, voice recordings, and multimedia documents such as presentation slides are even more difficult to analyze than textual input. Proper preprocessing of these input formats is one of the most important steps required to store such data. Simple image preprocessing algorithms can be used to extract the size or main color of an image. More complex algorithms that use machine learning techniques can identify what is in an image or who the people in an image are.
- Sensor data and other data for monitoring: Servers, smartphones, and many other devices produce so-called log entries that arise during use. A web server logs every single request of a web page. Such a log entry contains a lot of information about the surfer: his IP address, country, city, browser, operating system, screen resolution, and much more. This makes it possible to analyze click behavior, the length of time spent on certain web pages, and whether a visitor is a returning or a new visitor. In smartphones, there are sensors to collect data such as GPS position or battery status. A proximity sensor and the gyroscope can be used in combination to detect whether the phone is in a pocket, whether the user is holding it, or whether it is on a desk.
What are the Benefits of using Big Data?
It is difficult to define when a company is really using Big Data and when it is merely analyzing data. Therefore, the concrete benefits can also vary from company to company. In general, Big Data software specializes in processing large amounts of data and thus enables faster and more efficient data queries than conventional relational databases.
At the same time, Big Data also makes it possible to process unstructured data such as images or videos. This was not possible in previous database systems, or only with great difficulty.

At the company level, Big Data can be used to achieve major competitive advantages, for example by being able to better investigate customer needs. A large amount of data can be used to gain additional information about the customer’s buying behavior and preferences.
Another of the many advantages of Big Data is the associated facilitation of the decision-making process. The targeted evaluation of data volumes results in the concrete potential for improvement, or an upcoming decision can be proven or disproven on a data-driven basis. As a result, strategic decisions can also be justified very rationally.
What Risks does Big Data pose?
While the new technical possibilities created by Big Data represent real progress, they are also associated with serious threats. To manage them, we need to know what potential threats Big Data poses.
Security Issues
With the technical processing of such large amounts of data, compliance with data security can quickly fade into the background. The more data a company stores, the greater the effort required to protect it adequately, as this also makes it a greater target for attacks. The precautionary measures that therefore have to be taken incur immense costs, but these do not initially mean any additional revenue for the company itself.
Before the age of Big Data, only the state was able and authorized to store extensive information about an individual person. The tax authorities, the registration office, the driver’s license office, etc. collected a lot of personal information that was exclusively available to the government and protected by data protection laws. On the other hand, today many larger companies are able to collect this personal information and may even have more personal information than the government.
Moral Concerns
In the insurance industry, it is already common practice for data about the policyholder’s behavior to affect the premium. If one causes a car accident, it is very likely that the insurance premium will increase. If, on the other hand, one drives accident-free for several years, this can lead to a reduction in the premium.
With Big Data and the amount of data available about a single person, it is not impossible that more and more information will be incorporated into such calculations, thus personalizing the premium. Admittedly, this approach by insurance companies is understandable. But it is only a fine line that such measures also have a discriminatory effect. What do we think, for example, of a person having to pay a higher insurance premium simply because people in his or her family or immediate environment statistically cause more accidents?
How can you use our Website to get into Big Data?
If this is the first time you’ve heard about Big Data or if you’re still unfamiliar with the topic, you’ll find many articles on our site to help you get started. Here you will find a list of topics and articles that will help you get started:
- Big Data Provenance: Introduction to web scraping with Python
- Traditional Data Handling: Database, SQL, Data Warehouse, Data Types, ACID properties
- New, Scalable Database Approaches for Big Data: NoSQL, MongoDB, Redis, Data Lake
- File Formats for Transferring Data: XML, JSON, Application Programming Interface
- Big Data Software: Apache MapReduce, Hadoop, HDFS, Kubernetes, Docker
After these basic articles in the area of Big Data, you should already have an overview of which topics are collected around the term Big Data and can decide into which aspect you want to dive deeper.
This is what you should take with you
- Big Data refers to high-volume, fast, and/or variant-rich information stocks. In order to process these, we need new forms of information processing.
- Big Data can be characterized by the so-called 4 V’s: Volume, Variety, Velocity, and Veracity.
- In many cases, the data originates either from classic data stocks, multimedia sources, or monitoring data (sensor data).

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Big Data
- You can find a detailed definition here.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.