A database schema describes the logical dependencies between database objects, such as relations, i.e. tables, or views. It defines how the relationships between attributes and tables are regulated. The relational query language SQL is used for this purpose.
What is a relational Database Schema?
With large amounts of data, storage in databases or the data warehouse quickly becomes confusing and queries are complicated and take a relatively long time. This is why you need intelligent ways to create tables so that memory can be saved and queries can be performed more quickly.
To exploit the full potential of databases, their structure is described and optimized in the database schema. It also serves to ensure that all users of the data can independently find out where the required information is located and which query can be used to access it. In addition to the relationships between the entities, such as tables or views, the database schema also stores the database processes.
What Types of Database Schemes are there?
In the application, there are two different types of database schemas. The main difference between these types lies in how practical they are:
The logical schema defines the relationship between tables and other entities. It also determines the so-called integrity conditions. Several integrity conditions lead to consistent data. One of these, for example, stipulates that no column in the table should contain null values.
The physical schema, on the other hand, is more concerned with the practical storage of the data and describes the indices with which the data should be physically stored on the storage medium.
What are the important Components of a Database Schema?
The database schema is a central component of a database and defines the structure and organization of the information. This includes, for example, describing how the data is organized or what the relationships between the database elements look like. A well-designed database schema consists of various components that play an important role in storing and retrieving data. In this section, we present the most important components and their tasks.
Tables (entities)
The tables, or entities, are the basic elements in a database schema in which the data is stored in the form of rows and columns. Each table should represent self-contained entities, such as products or customers in a company database. The rows contain individual data records, such as a specific product or a specific customer. Different attributes of these data records are stored in the columns, such as the customer name or the product price.
Columns (attributes)
The columns within a table store individual data record information and determine the structure of the table. Each attribute follows a specific data type, such as an integer, a text, or a date. This property is a central component of the database schema and determines the efficiency of the database and the accuracy of the data it contains. An incorrectly selected data type can have immense consequences later on.
Keys
Keys are not only used to define the relationships between tables, they are also an important component for the integrity, i.e. the truthfulness, of the data. Accordingly, there are two main types of keys:
- Primary keys are used within a table to ensure that each data record can be uniquely identified. Each table should have a unique attribute and a primary key to ensure that no inconsistent or duplicate data records are stored. For example, unique customer or product numbers can be used as primary keys. If a data record does not have a single unique attribute, composite attributes can also be used as primary keys.
- Relationships between tables can be established using foreign keys. A foreign key in a table refers to the primary key of another table and thus establishes the relationship between the two entities. For example, a table with orders could contain a reference to the customer table in which specific customer information, such as the address, is stored.
Relationships
The relationships in a database schema define how different tables are linked to each other. An intelligent linking of entities can result in the database running much more efficiently and taking up less storage space, as no duplicate information is stored and the individual tables do not have as many attributes.
In database theory, a distinction is made between three types of relationships:
- 1:1 relationship: Such a relationship exists when an entity is assigned exactly one other entity in another table. For example, each person can only have one valid identity card.
- 1-n relationship: If several entities in another table are assigned to an entity in one table, this is referred to as a 1-n relationship. For example, a customer only appears once in a customer table. However, this customer may have made multiple purchases in the table with the orders, meaning that the entity is represented more frequently in this table.
- n:m relationship: In an n:m relationship, an entity appears multiple times in both tables. In some cases, an n:m relationship is incorrect, as some data records are duplicates, but there are also cases in which this type of relationship is unavoidable. For example, an author may have written several books and a book may be written by several authors at the same time, resulting in an n:m relationship between the Books and Authors tables.
Indices
Indexes can be used to improve the performance of databases. This speeds up access to certain data records, especially in large tables, by creating a kind of directory of the data. For example, you can set an index in the “Customer name” column to find customers more quickly. The customers are then sorted alphabetically, allowing faster access. However, indexes should be set with care, as they also require storage space and hurt write speed. It is best to only set indexes for columns that are searched frequently.
What is the Difference between a Database Schema and a Database Instance?
The terms database instance and database schema are often used as synonyms but describe different properties. The database instance is a copy of a database at a specific point in time, which itself also contains data. This means that there can be different database instances at different times.
The database schema, on the other hand, tends to be static and is very difficult to change once it has been put into operation. Changing existing tables in which information has already been stored is very difficult to implement, as the corresponding pipelines that fill the database must also be changed.
What is Database Normalization?
Normalization is an essential part of database optimization that aims to store data efficiently and consistently, i.e. without inconsistencies. Various rules have been developed for this purpose, which redesign the data structure in such a way that the information is stored without redundancies and inconsistencies in content. In particular, the following three normal forms have been developed:
1st normal form (1NF)
The 1st normal form is achieved when all data records are atomic. This means that each data field may only contain one value. It should also be ensured that each column only contains values of the same data type (numeric, text, etc.). The following examples would have to be changed accordingly so that a database is available in the 1st normal form:
Address: “Hauptstraße 1, 12345 Berlin” –> Street: “Hauptstraße”, House number: “1”, Postcode: “12345”, City: “Berlin”
Invoice amount: “128,45 €” –> Amount: “128,45”, Currency: “€”
2nd normal form (2NF)
The 2nd normal form is fulfilled if the first normal form is fulfilled and, in addition, each column in a row is fully functionally dependent on the primary key. The primary key is an attribute that can be used to uniquely identify a database row. This includes, for example, the invoice number to identify an invoice or the ID number to identify a person.
In practical terms, this means that all attributes that are not exclusively dependent on the primary key must be outsourced. In practice, this often leads to a so-called star schema.
In our example, the customer name is not dependent on the primary key “order_id” of the original table. The customer name must therefore be outsourced to a new table. Only the foreign key “customer_id” then references the new table so that no information is lost.
3rd normal form (3NF)
The third normal form exists if the two previous normal forms are fulfilled and there are also no so-called transitive dependencies. A transitive dependency exists if an attribute that is not a primary key depends not only on this key but also on other attributes.
If, in our example, we have a table in which the invoice number, the product number, and the price are given, we most likely have a transitive dependency. The price of the product does not depend on the invoice number, but rather on the product number, as a fixed price is defined for each product.
This dependency can be resolved by moving the products to a new table and thus removing the price attribute from the original table.
Which Database Schemes are used in practice?
In practice, two relational database schemas have established themselves, which are used depending on the specific application.
Star schema
The first approach for a possible database schema is the star schema, which contains star-shaped table structures. A distinction is made between facts and dimensions:
The facts are key figures or measured values that are to be analyzed or illustrated. They form the focus of the analysis and are located in the central fact table. In addition to the key figures, this also consists of the keys that refer to the surrounding dimensions. In the corporate environment, facts are, for example, the sales volume, turnover, or incoming orders.
The dimensions, on the other hand, are the properties of the facts and can be used to visualize the key figures. The different levels of detail of the dimensions are then stored in these and memory space can therefore be saved as the details only need to be stored once in the dimension table. Dimensions in the corporate environment are, for example, customer information, the date of the order or product information.
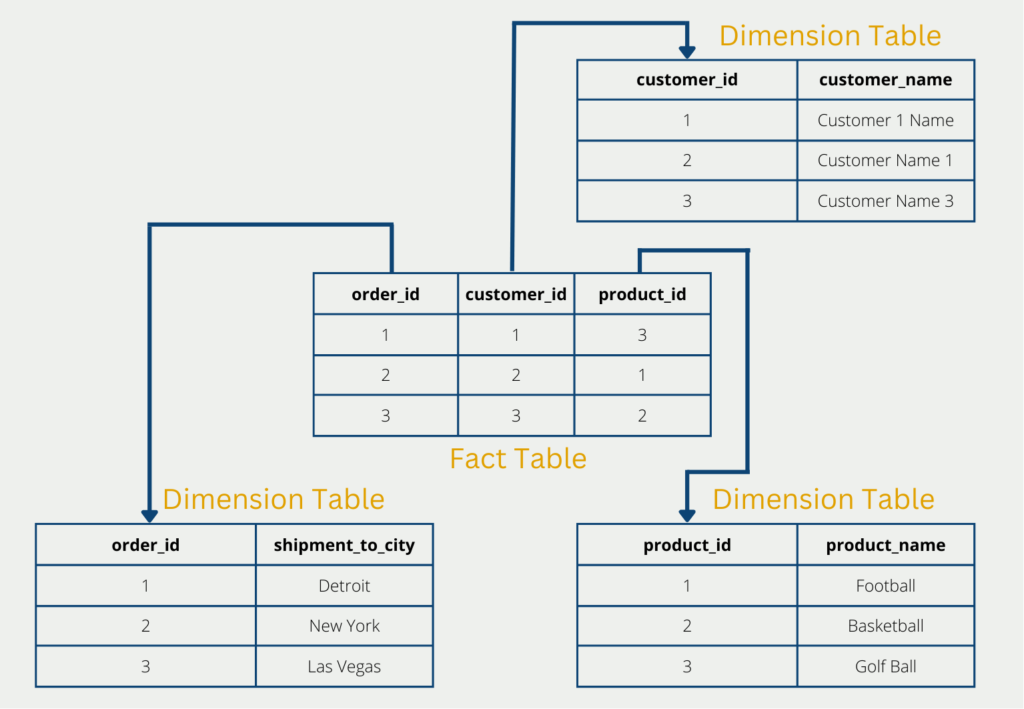
The star schema deliberately dispenses with normalization, which is normally an important concept in database theory. This is because the third normal form is violated by a star schema. On the other hand, the structure is particularly efficient and provides fast answers even for complex queries.
Snowflake Schema
The so-called snowflake schema is a further expansion stage of the star schema to completely normalize the tables and thus circumvent the disadvantages of the star schema to a certain extent. In short, the structure of a snowflake results from the fact that the dimension tables are broken down and classified even further. The fact table, on the other hand, remains unchanged.
In our example, this could result in the dimension table with the delivery addresses being further classified into country, state, and city. This normalizes the tables and the third normal form is also fulfilled. However, this is at the expense of further branches. These are particularly disadvantageous for a later query, as they have to be reassembled with complex joins.
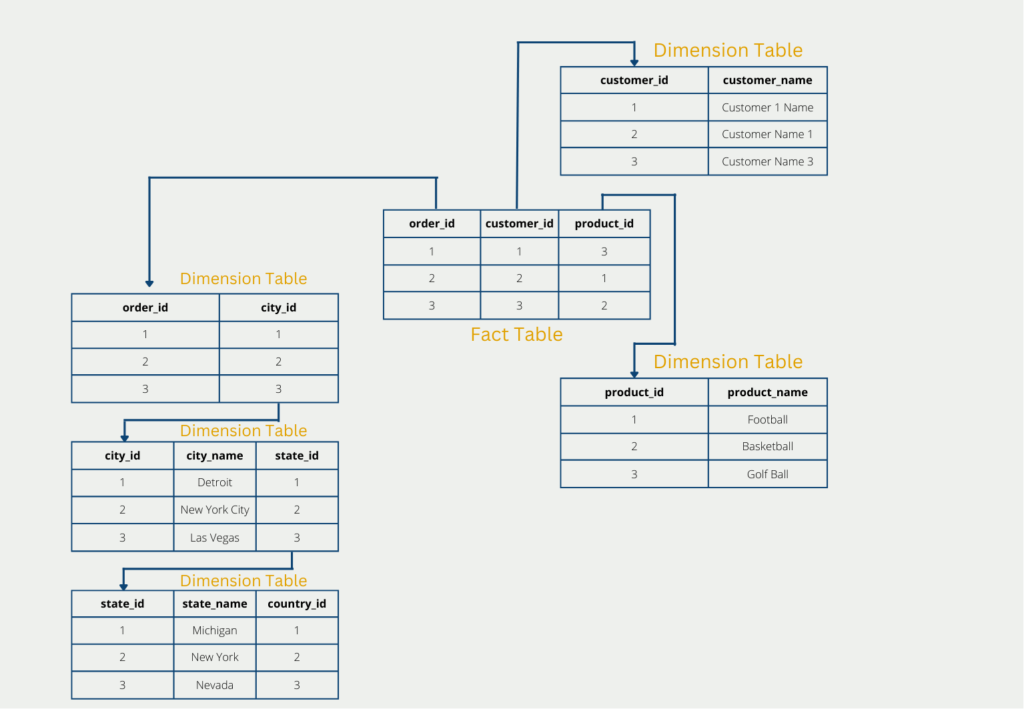
Branching therefore means that the data is stored less redundantly, which further reduces the amount of data compared to the star schema. However, this is at the expense of performance, as the dimension tables have to be merged again during the query, which is often very time-consuming.
Star Schema vs. Snowflake Schema
The star schema and the snowflake schema are relatively similar in structure and are therefore often compared with each other. The choice of a suitable database schema depends primarily on the specific application.
In short, the star schema aims to provide a good basis for frequent queries and still reduce the amount of data. This is achieved by splitting the data into fact and dimension tables. This allows many redundancies to be removed and the first two normal forms to be fulfilled. The number of tables remains relatively small, allowing queries with few joins and fast response times. However, the database cannot be completely normalized and some redundancies remain.
The snowflake schema, on the other hand, is a further development of the star schema to normalize the database. The fact table is retained and the dimension tables are further classified and divided into additional relations. Although this eliminates the remaining redundancies of the rigid schema, it makes queries slower and more time-consuming, as the dimension tables first have to be merged again.
What are Data Types and what influence do they have on a Database?
In a database, data types describe the form in which information can be stored in an attribute. Only one data type can be defined for each attribute, from which individual data records may not deviate. The most frequently used data types for databases are
- Integer: This can be used to store integers without decimal places. These include, for example, the customer ID, which uniquely identifies each customer in the table. An integer could also be used to store the number of products purchased.
- VARCHAR: This data type is used to store text data. You can also define a fixed length for it, which must not be exceeded. Depending on the length, the database reserves more or less storage space for this attribute.
- DateTime: DateTime can be used to store date and time information that is suitable for the time of purchase, for example.
- Boolean: Booleans are a binary data type that can only take one of two forms, such as “true” or “false”. They can be used to store truthful information, such as whether a customer already has a loyalty card or not.
The choice of data type has far-reaching consequences for the structure and use of a database. On the one hand, they determine the form in which certain attributes can be stored. If a data record does not fulfill this form, problems can arise when writing the data.
The selected data types also have a major influence on the required storage space. For example, if only numbers need to be saved, it is more efficient to use the INTEGER type instead of storing the number as text using VARCHAR. In addition, the DateTime data type is very memory-intensive, which is why you should decide whether it is sufficient to store only the date or the time.
How can a Database Schema contribute to Performance Optimization?
The database schema has a direct influence on the performance of the database when querying data or when writing, i.e. saving new data records. As already mentioned, adding indexes can significantly speed up frequent queries, but can also lead to poorer performance if used excessively.
For larger databases with many millions of rows, partitioning plays a major role by splitting large tables into smaller and more manageable tables so that the entire table does not have to be searched during a search process. Tables can be partitioned by year or region, for example.
In growing databases, scalability, i.e. the ability to handle increasing numbers of queries, also becomes more important. There are various options for meeting these requirements:
- Horizontal scaling: Here, a database is split across different physical devices, i.e. different computers or servers that can communicate with each other. This allows the load of queries to be distributed across different devices. However, this can have an impact on the consistency, i.e. the veracity of the data.
- Vertical scaling: With this method, the device on which the database is stored is equipped with better hardware to be able to withstand the load. This includes, for example, more storage space or a more powerful processor.
- Caching: With caching, frequently made queries and their results are stored temporarily so that they do not have to be calculated live when they are called up, but can simply be played out from the cache.
A well-thought-out combination of the right data types, the use of indices, the partitioning of data, and a scalability method can be used to set up individual and powerful databases.
This is what you should take with you
- A database schema is the logical description of the relationships between different database objects, such as tables or views.
- A distinction is made between the logical and the physical database schema.
- A database schema is made up of various components, such as tables, keys, or relationships.
- In practice, database schemas are mainly used in connection with relational databases. The Star schema or the Snowflake schema are the most commonly used.
- Data types determine the format in which the attributes are stored in a data record. These have a major influence on the required storage space and the performance of the database. The data types of the attributes are defined in a database schema.
- The performance of a database can be greatly optimized with the help of a well-thought-out database schema. For example, indexes or partitioning defined in a database schema can be used for this purpose.

What is the Univariate Analysis?
Master Univariate Analysis: Dive Deep into Data with Visualization, and Python - Learn from In-Depth Examples and Hands-On Code.

What is OpenAPI?
Explore OpenAPI: A Comprehensive Guide to Building and Consuming RESTful APIs. Learn How to Design, Document, and Test APIs.

What is Data Governance?
Ensure the quality, availability, and integrity of your organization's data through effective data governance. Learn more here.

What is Data Quality?
Ensuring Data Quality: Importance, Challenges, and Best Practices. Learn how to maintain high-quality data to drive better business decisions.

What is Data Imputation?
Impute missing values with data imputation techniques. Optimize data quality and learn more about the techniques and importance.

What is Outlier Detection?
Discover hidden anomalies in your data with advanced outlier detection techniques. Improve decision-making and uncover valuable insights.
Other Articles on the Topic of Database Schemas
A detailed article about the database schema can also be found at Lucidchart. This served as a basis and source for this article on database schema.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.