Ein Datenbankschema ist die Beschreibung der logischen Abhängigkeiten zwischen Datenbankobjekten, wie beispielsweise Relationen, also Tabellen, oder Views. Darin wird definiert, wie die Beziehungen zwischen Attributen und Tabellen geregelt sind. Dazu wird die relationale Abfragesprache SQL genutzt.
Was ist ein relationales Datenbankschema?
Bei großen Datenmengen wird die Speicherung in Datenbanken oder dem Data Warehouse schnell unübersichtlich und Abfragen sind nicht nur kompliziert, sondern dauern auch relativ lange. Deshalb benötigt man intelligente Wege, um Tabellen anzulegen, sodass Speicher gespart werden kann und somit Abfragen schneller stattfinden.
Um das volle Potenzial von Datenbanken ausschöpfen zu können, wird deshalb deren Aufbau im Datenbankschema beschrieben und optimiert. Außerdem dient es dazu, dass alle Nutzer der Daten sich eigenständig darüber informieren können, wo die benötigten Informationen liegen und mit welcher Abfrage man an sie gelangen kann. Darin sind nämlich neben den Beziehungen zwischen den Entitäten, wie Tabellen oder Views, auch die Abläufe der Datenbank gespeichert.
Welche Arten von Datenbankschemata gibt es?
In der Anwendung unterscheidet man grundsätzlich zwei verschiedene Arten von Datenbankschemata. Der Unterschied dieser Arten liegt vor allem darin, wie praktisch sie schon veranlagt sind:
Das logische Schema legt die Beziehung zwischen Tabellen und anderen Entitäten fest. Außerdem bestimmt es die sogenannten Integritätsbedingungen. Es gibt mehrere Integritätsbedingungen, die zu konsistenten Daten führen. Eine davon legt beispielsweise fest, dass keine Spalte in der Tabelle Null-Werte enthalten soll.
Das physische Schema hingegen beschäftigt sich vielmehr mit der praktischen Speicherung der Daten und beschreibt mit welchen Indizes die Daten physisch auf dem Speichermedium hinterlegt werden sollen.
Was sind wichtige Komponenten eines Datenbankschemas?
Das Datenbankschema ist ein zentraler Bestandteil einer Datenbank und legt fest, in welcher Struktur und Organisation die Informationen liegen. Dazu gehört beispielsweise, dass beschrieben wird, wie die Daten organisiert sind oder wie die Beziehungen zwischen den Datenbankelementen aussehen. Ein gut gestaltetes Datenbankschema besteht dabei aus unterschiedlichen Komponenten, welche eine wichtige Rolle bei der Speicherung und Abfrage der Daten spielen. In diesem Abschnitt stellen wir die wichtigsten Komponenten und deren Aufgaben vor.
Tabellen (Entitäten)
Die Tabellen, oder auch Entitäten, sind die grundlegenden Elemente in einem Datenbankschema in denen die Daten in Form von Zeilen und Spalten abgespeichert werden. In jeder Tabelle sollten abgeschlossene Entitäten repräsentiert werden, wie beispielsweise Produkte oder Kunden in einer Firmendatenbank. Die Zeilen enthalten dabei einzelne Datensätze, wie zum Beispiel ein spezifisches Produkt oder ein spezifischer Kunde. In den Spalten werden unterschiedliche Attribute dieser Datensätze hinterlegt, wie etwa der Kundenname oder der Produktpreis.
Spalten (Attribute)
Die Spalten innerhalb einer Tabelle speichern einzelne Informationen des Datensatzes ab und bestimmen darüber die Struktur der Tabelle. Jedes Attribut folgt dabei einem bestimmten Datentyp, wie beispielsweise eine Ganzzahl, ein Text oder ein Datum. Diese Eigenschaft ist ein zentraler Bestandteil des Datenbankschemas und bestimmt über die Effizienz der Datenbank und über die Genauigkeit der darin enthaltenen Daten. Ein falsch gewählter Datentyp kann später immense Folgen haben.
Schlüssel
Mithilfe von Schlüsseln werden nicht nur die Beziehungen zwischen Tabellen definiert, sondern sie sind auch ein wichtiger Bestandteil für die Integrität, also den Wahrheitsgehalt, der Daten. Dementsprechend unterscheidet man zwei zentrale Arten von Schlüsseln:
- Primärschlüssel dienen innerhalb einer Tabelle dazu, dass jeder Datensatz eindeutig identifiziert werden kann. Jede Tabelle sollte ein solches einzigartiges Attribut und einen Primärschlüssel besitzen, um sicherzustellen, dass keine inkonsistenten oder doppelten Datensätze abgespeichert werden. Es können beispielsweise eindeutige Kunden- oder Produktnummern als Primärschlüssel verwendet werden. Falls ein Datensatz kein einzelnes Attribut besitzt, welches eindeutig ist, können auch zusammengesetzte Attribute als Primärschlüssel dienen.
- Mithilfe von sogenannten Fremdschlüsseln können Beziehungen zwischen Tabellen aufgebaut werden. Ein Fremdschlüssel in einer Tabelle verweist dabei auf den Primärschlüssel einer anderen Tabelle und stellt dadurch die Beziehung zwischen beiden Entitäten her. Es könnte beispielsweise in einer Tabelle mit Bestellungen ein Verweis auf die Kundentabelle vorhanden sein in der dann spezifische Kundeninformationen, wie zum Beispiel die Adresse hinterlegt sind.
Beziehungen
Die Beziehungen in einem Datenbankschema definieren, wie verschiedene Tabellen miteinander verknüpft sind. Eine intelligente Verknüpfung von Entitäten kann dazu führen, dass die Datenbank deutlich effizienter laufen und weniger Speicherplatz belegen muss, da keine doppelten Informationen gespeichert sind und die einzelnen Tabellen nicht so viele Attribute besitzen.
In der Datenbanktheorie unterscheidet man insgesamt drei Arten von Beziehungen:
- 1:1 Beziehung: Eine solche Beziehung liegt vor, wenn einer Entität genau eine andere Entität in einer anderen Tabelle zugeordnet ist. Jede Person kann beispielsweise nur einen gültigen Personalausweis besitzen.
- 1-n Beziehung: Wenn einer Entität in einer Tabelle mehrere Entitäten in einer anderen Tabelle zugeordnet sind, spricht man von einer 1-n Beziehung. Ein Kunde kommt beispielsweise nur einmal in einer Kundentabelle vor. In der Tabelle mit den Bestellungen kann dieser Kunde jedoch mehrfach gekauft haben, sodass die Entität in dieser Tabelle häufiger vertreten ist.
- n:m Beziehung: In einer n:m Beziehung kommt eine Entität in beiden Tabellen mehrfach vor. In manchen Fällen ensteht eine n:m Beziehung fehlerhaft, da manche Datensätze Duplikate darstellen, jedoch gibt es auch Fälle, in denen dieser Beziehungstyp unumgänglich ist. Ein Autor kann beispielsweise mehrere Bücher geschrieben haben und gleichzeitig kann ein Buch von mehreren Autoren verfasst werden, wodurch eine n:m Beziehung zwischen den Tabellen Bücher und Autoren entsteht.
Indizes
Mithilfe von Indizes kann die Leistung von Datenbanken verbessert werden. Dadurch wird der Zugriff auf bestimmte Datensätze gerade bei großen Tabellen beschleunigt, indem eine Art Verzeichnis der Daten angelegt wird. In der Spalte „Kundenname“ kann man beispielsweise einen Index setzen, um Kunden schneller zu finden. Dabei werden dann die Kunden alphabetisch sortiert, wodurch ein schnellerer Zugriff möglich ist. Indizes sollten jedoch mit Bedacht gesetzt werden, da sie auch Speicherplatz benötigen und die Schreibgeschwindigkeit negativ beeinflussen. Am besten setzt man nur Indizes für Spalten, welche häufig durchsucht werden.
Was ist der Unterschied zwischen einem Datenbankschema und einer Datenbankinstanz?
Die Begriffe Datenbankinstanz und Datenbankschema werden häufig als Synonyme genutzt, beschreiben jedoch unterschiedliche Eigenschaften. Die Datenbankinstanz ist ein Abzug einer Datenbank zu einem bestimmten Zeitpunkt, der selbst also auch Daten enthält. Somit kann es zu verschiedenen Zeitpunkten auch unterschiedliche Datenbankinstanzen geben.
Das Datenbankschema hingegen ist eher statisch und lässt sich nach der Inbetriebnahme nur sehr schwer wieder verändern. Die Änderung von bestehenden Tabellen, in denen bereits Informationen abgespeichert wurden, ist nur sehr schwierig umzusetzen, da auch die entsprechenden Pipelines, die die Datenbank füllen, geändert werden müssen.
Was ist die Normalisierung von Datenbanken?
Die Normalisierung ist ein essenzieller Bestandteil bei der Optimierung von Datenbanken, der es zum Ziel hat, die Daten effizient und konsistent, also ohne Widersprüche, abzuspeichern. Dafür haben sich verschiedene Regeln entwickelt, welche die Datenstruktur so umgestalten, dass die Informationen ohne Redundanzen und inhaltliche Widersprüche abgespeichert werden. Dabei haben sich vor allem die folgenden drei Normalformen entwickelt:
1. Normalform (1NF)
Die 1. Normalform ist erreicht, wenn alle Datensätze atomar sind. Das bedeutet, dass jedes Datenfeld lediglich einen Wert enthalten darf. Außerdem sollte sichergestellt sein, dass jede Spalte nur Werte desselben Datentyps (Numerisch, Text, etc.) enthält. Folgende Beispiele müssten entsprechend verändert werden, damit eine Datenbank in der 1. Normalform vorhanden ist:
Adresse: “Hauptstraße 1, 12345 Berlin” –> Straße: “Hauptstraße”, Hausnummer: “1”, PLZ: “12345”, Ort: “Berlin”
Rechnungsbetrag: “128,45 €” –> Betrag: “128,45”, Währung: “€”
2. Normalform (2NF)
Die 2. Normalform ist erfüllt, wenn die erste Normalform erfüllt ist, und außerdem jede Spalte in einer Zeile voll funktional abhängig ist vom Primärschlüssel. Der Primärschlüssel bezeichnet ein Attribut, das zur eindeutigen Identifikation einer Datenbankzeile verwendet werden kann. Dazu zählen beispielsweise die Rechnungsnummer zur Identifikation einer Rechnung oder die Ausweisnummer zur Identifikation einer Person.
Konkret bedeutet dies in der Anwendung, dass alle Merkmale ausgelagert werden müssen, die nicht ausschließlich vom Primärschlüssel abhängig sind. In der Praxis führt dies dann oft zu einem sogenannten Sternschema.
In unserem Beispiel ist der Kundenname nicht vom Primärschlüssel “order_id” der ursprünglichen Tabelle abhängig. Deswegen muss der Kundenname in einer neuen Tabelle ausgelagert werden. Lediglich der Fremdschlüssel “customer_id” referenziert dann auf die neue Tabelle, sodass keine Information verloren geht.
3. Normalform (3NF)
Die dritte Normalform liegt vor, wenn die beiden vorhergehenden Normalformen erfüllt sind, und es zusätzlich keine sogenannten transitiven Abhängigkeiten gibt. Eine transitive Abhängigkeit liegt vor, wenn ein Attribut, welches kein Primärschlüssel ist, nicht nur von diesem abhängt, sondern auch von anderen Attributen.
Wenn wir in unserem Beispiel eine Tabelle haben, in der die Rechnungsnummer, die Produktnummer und der Preis gegeben ist, haben wir höchstwahrscheinlich eine transitive Abhängigkeit. Der Preis des Produktes hängt nämlich nicht wirklich von der Rechnungsnummer ab, sondern vielmehr von der Produktnummer, da für jedes Produkt ein fester Preis definiert ist.
Diese Abhängigkeit kann man auflösen, indem man die Produkte in eine neue Tabelle auslagert und somit das Attribut Preis aus der ursprünglichen Tabelle rausfällt.
Welche Datenbankschemata gibt es in der Praxis?
In der Praxis haben sich vor allem zwei relationale Datenbankschemata durchgesetzt, die abhängig vom konkreten Anwendungsfall genutzt werden.
Starschema
Ein erster Ansatz für ein mögliches Datenbankschema ist das Starschema, das sternenförmige Tabellenstrukturen beinhaltet. Dabei wird in Fakten und Dimensionen unterschieden:
Die Fakten sind Kennzahlen oder Messwerte, die analysiert oder veranschaulicht werden sollen. Sie bilden den Mittelpunkt der Analyse und stehen in der zentralen Faktentabelle. Diese besteht neben den Kennzahlen noch aus den Schlüsseln, die auf die umliegenden Dimensionen verweisen. Im Unternehmensumfeld sind Fakten beispielsweise die Umsatzmenge, der Umsatz oder der Auftragseingang.
Die Dimensionen hingegen sind die Eigenschaften der Fakten und können genutzt werden, um die Kennzahlen zu visualisieren. In diesen sind dann die verschiedenen Detailstufen der Dimensionen gespeichert und somit kann Speicherplatz gespart werden, da die Details nur ein einziges Mal in der Dimensionstabelle hinterlegt werden müssen. Dimensionen im Unternehmensumfeld sind beispielsweise die Kundeninformationen, das Datum des Auftrags oder Produktinformationen.

Das Starschema verzichtet dabei gezielt auf die Normalisierung, die normalerweise ein wichtiges Konzept in der Datenbanktheorie darstellt. Die dritte Normalform ist nämlich mit einem Sternenschema verletzt. Dafür ist der Aufbau besonders effizient und liefert schnelle Antworten auch bei komplexen Abfragen.
Snowflake-Schema
Das sogenannte Schneeflocken-Schema ist eine weitere Ausbaustufe des Starschemas mit dem Ziel, die Tabellen komplett zu normalisieren und dadurch die Nachteile des Starschemas gewissermaßen zu umgehen. Der Aufbau einer Schneeflocke ergibt sich kurzgesagt dadurch, dass die Dimensionstabellen noch weiter aufgeschlüsselt und klassifiziert werden. Die Faktentabelle hingegen bleibt unverändert.
In unserem Beispiel könnte das dazu führen, dass die Dimensionstabelle mit den Lieferadressen weiter klassifiziert wird in Land, Bundesland und Stadt. Dadurch werden die Tabellen normalisiert und es ist auch die dritte Normalform erfüllt. Jedoch geht dies zu Lasten von weiteren Verzweigungen. Diese sind vor allem bei einer späteren Abfrage nachteilig, da sie mit aufwändigen Joins wieder zusammengefügt werden müssen.
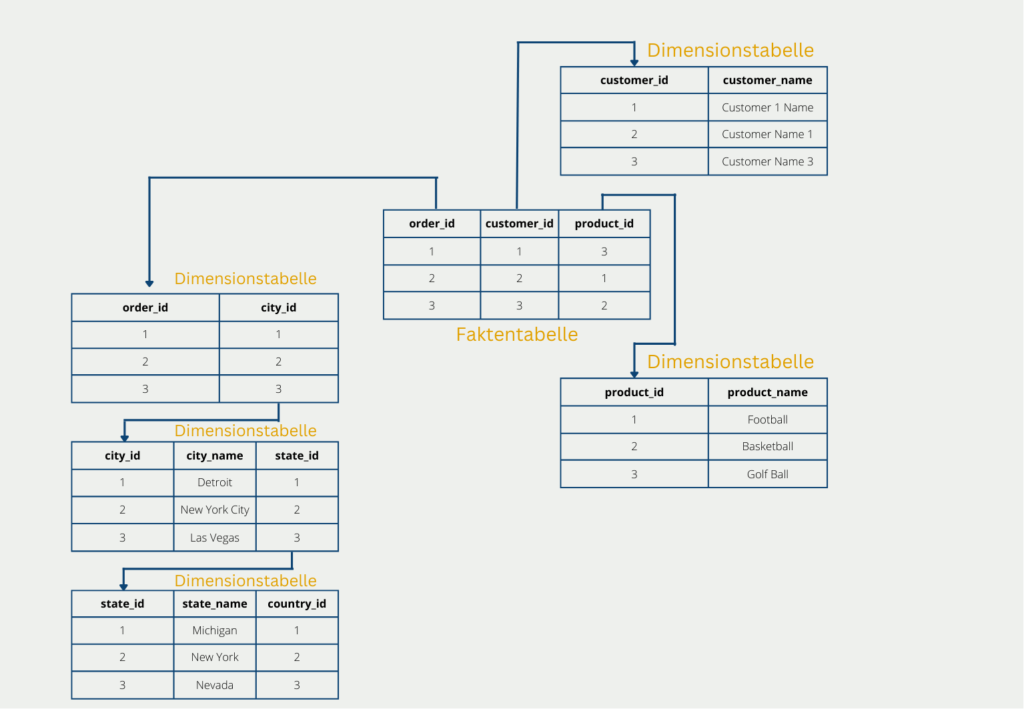
Die Weiterverzweigung führt also dazu, dass die Daten weniger redundant abgespeichert werden und dadurch die Datenmenge nochmal weiter reduziert wird im Vergleich zum Starschema. Dies geht jedoch zu Lasten der Performance, da bei der Abfrage die Dimensionstabellen wieder zusammengeführt werden müssen, was häufig sehr aufwändig ist.
Sternschema vs. Snowflake-Schema
Das Starschema und das Snowflake-Schema sind relativ ähnlich aufgebaut und werden auch deshalb oft miteinander verglichen. Tatsächlich hängt die Wahl eines passenden Datenbankschemas vor allem von der konkreten Anwendung ab.
Kurz gesagt ist das Ziel des Starschemas eine gute Grundlage für häufige Abfragen zu bieten und trotzdem die Datenmenge zu verringern. Das wird erzeugt, indem eine Aufspaltung in Fakten- und Dimensionstabellen vorgenommen wird. Dadurch lassen sich viele Redundanzen entfernen und die ersten zwei Normalformen erfüllen. Die Zahl der Tabellen bleibt verhältnismäßig klein und dadurch sind Abfragen mit wenigen Joins und schnellen Antwortzeiten möglich. Jedoch kann keine vollständige Normalisierung der Datenbank erfolgen und einige Redundanzen bleiben bestehen.
Das Schneeflocken-Schema hingegen ist eine Weiterentwicklung des Starschemas mit dem Ziel, eine Normalisierung der Datenbank herbeizuführen. Dabei wird die Faktentabelle beibehalten und die Dimensionstabellen werden noch weiter klassifiziert und in weitere Relationen aufgeteilt. Dadurch werden zwar die verbleibenden Redundanzen des Starschemas beseitigt, jedoch werden Abfragen dadurch langsamer und aufwändiger, da die Dimensionstabellen erst wieder zusammengeführt werden müssen.
Was sind Datentypen und welchen Einfluss haben sie auf eine Datenbank?
Die Datentypen beschreiben in einer Datenbank, in welcher Form die Informationen in einem Attribut abgelegt werden können. Dabei kann für jedes Attribut lediglich ein Datentyp definiert werden, von dem auch einzelne Datensätze nicht abweichen dürfen. Die am häufigsten verwendeten Datentypen für Datenbanken sind:
- Integer: Hiermit lassen sich Ganzzahlen ohne Nachkommastelle abspeichern. Dazu zählen beispielsweise die Kunden-ID, die jeden Kunden in der Tabelle eindeutig identifiziert. Außerdem könnte man mit einem Integer die Anzahl der gekauften Produkte speichern.
- VARCHAR: Dieser Datentyp wird zur Speicherung von Textdaten verwendet. Man kann dafür auch eine feste Länge hinterlegen, die nicht überschritten werden darf. Abhängig von der Länge reserviert die Datenbank für dieses Attribut mehr oder weniger Speicherplatz.
- DateTime: Mithilfe von DateTime können Datums- und Zeitangaben hinterlegt werden, die sich beispielsweise für den Kaufzeitpunkt eignen.
- Boolean: Booleans sind ein binärer Datentyp, welcher lediglich einen von zwei Formen annehmen kann, wie zum Beispiel „true“ oder „false“. Damit können Wahrheitsangaben abgespeichert werden, wie etwa, ob ein Kunde bereits eine Kundenkarte besitzt oder nicht.
Die Wahl des Datentyps haben weitreichende Folgen für den Aufbau und die Nutzung einer Datenbank. Zum einen legen sie fest, in welcher Form gewisse Attribute abgespeichert werden können. Wenn ein Datensatz diese Form nicht erfüllt, kann es zu Problemen beim Schreiben der Daten kommen.
Außerdem haben die gewählten Datentypen einen großen Einfluss auf den benötigten Speicherplatz. Wenn beispielsweise nur Zahlen gespeichert werden müssen, ist es effizienter den Typ INTEGER zu nutzen, anstatt die Zahl als Text mithilfe von VARCHAR zu hinterlegen. Zusätzlich ist der Datentyp DateTime sehr speicherintensiv, weshalb man sich entscheiden sollte, ob es nicht ausreichend ist, lediglich nur das Datum oder die Zeit abzuspeichern.
Wie kann ein Datenbankschema zur Leistungsoptimierung beitragen?
Das Datenbankschema hat einen direkten Einfluss auf die Leistungsfähigkeit der Datenbank bei der Abfrage von Daten oder beim Schreiben, also dem Abspeichern von neuen Datensätzen. Wie bereits erwähnt wurde kann das Hinzufügen von Indizes häufige Abfragen deutlich verschnellern, jedoch bei übermäßiger Nutzung auch zu einer schlechteren Performance führen.
Bei größeren Datenbanken mit vielen Millionen Zeilen spielen Partitionierungen eine große Rolle, indem große Tabellen in kleinere und besser handhabbare Tabellen aufgesplittet werden, damit bei einem Suchvorgang nicht die gesamte Tabelle durchsucht werden muss. Hierbei können Tabellen beispielsweise nach Jahren oder Regionen partitioniert werden.
In wachsenden Datenbanken wird auch die Skalierbarkeit wichtiger, also die Fähigkeit mit weiter wachsenden Zahlen von Abfragen umzugehen. Um diesen Anforderungen gerecht zu werden, gibt es verschiedene Möglichkeiten:
- Horizontales Skalieren: Hierbei wird eine Datenbank auf verschiedene physische Geräte aufgeteilt, also auf unterschiedliche Computer oder Server, welche miteinander kommunizieren können. Dadurch kann die Last der Abfragen auf verschiedene Geräte verteilt werden. Jedoch kann dies einen Einfluss auf die Konsistenz, also den Wahrheitsgehalt der Daten haben.
- Vertikales Skalieren: Bei dieser Methode wird das Gerät, auf dem die Datenbank hinterlegt ist, mit besserer Hardware ausgestattet, um den Belastungen standhalten zu können. Dazu zählen zum Beispiel mehr Speicherplatz oder ein leistungsfähiger Prozessor.
- Caching: Beim Caching werden häufig gestellte Abfragen und deren Ergebnisse zwischengespeichert, damit beim Abruf diese nicht erst live berechnet werden müssen, sondern einfach aus dem Cache ausgespielt werden können.
Durch eine durchdachte Kombination aus den richtigen Datentypen, dem Einsatz von Indizes, der Partitionierung von Daten und einer Skalierbarkeitsmethode können individuelle und leistungsfähige Datenbanken aufgesetzt werden.
Das solltest Du mitnehmen
- Ein Datenbankschema ist die logische Beschreibung der Beziehungen von verschiedenen Datenbankobjekten, wie beispielsweise Tabellen oder Views.
- Man unterscheidet dabei das logische und das physische Datenbankschema.
- Ein Datenbankschema setzt sich aus verschiedenen Komponenten zusammen, wie beispielsweise den Tabellen, Schlüsseln oder Beziehungen.
- In der Praxis werden Datenbankschemata vor allem im Zusammenhang mit relationalen Datenbanken verwendet. Dabei kommt vor allem das Starschema oder das Snowflakeschema zum Einsatz.
- Datentypen legen fest, in welchem Format die Attribute in einem Datensatz abgespeichert werden. Diese haben einen großen Einfluss auf den benötigten Speicherplatz und die Leistungsfähigkeit der Datenbank. In einem Datenbankschema sind die Datentypen der Attribute definiert.
- Mithilfe eines gut durchdachten Datenbankschemas kann die Leistung einer Datenbank stark optimiert werden. Hierfür können beispielsweise Indizes oder Partitionierungen zum Einsatz kommen.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Datenbankschema
- Ein ausführlicher Artikel zum Thema Datenbankschema findet sich auch bei Lucidchart. Dieser diente als Grundlage und Quelle für diesen Beitrag.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.