Random Forest is a supervised Machine Learning algorithm that is composed of individual decision trees. This type of model is called an ensemble model because an “ensemble” of independent models is used to compute a result.
What is a Decision Tree?
The basis for the Random Forest is formed by many individual decision trees, the so-called Decision Trees. A tree consists of different decision levels and branches, which are used to classify data.
The Decision Tree algorithm tries to divide the training data into different classes so that the objects within a class are as similar as possible and the objects of different classes are as different as possible. This results in multiple decision levels and response paths, as in the following example:
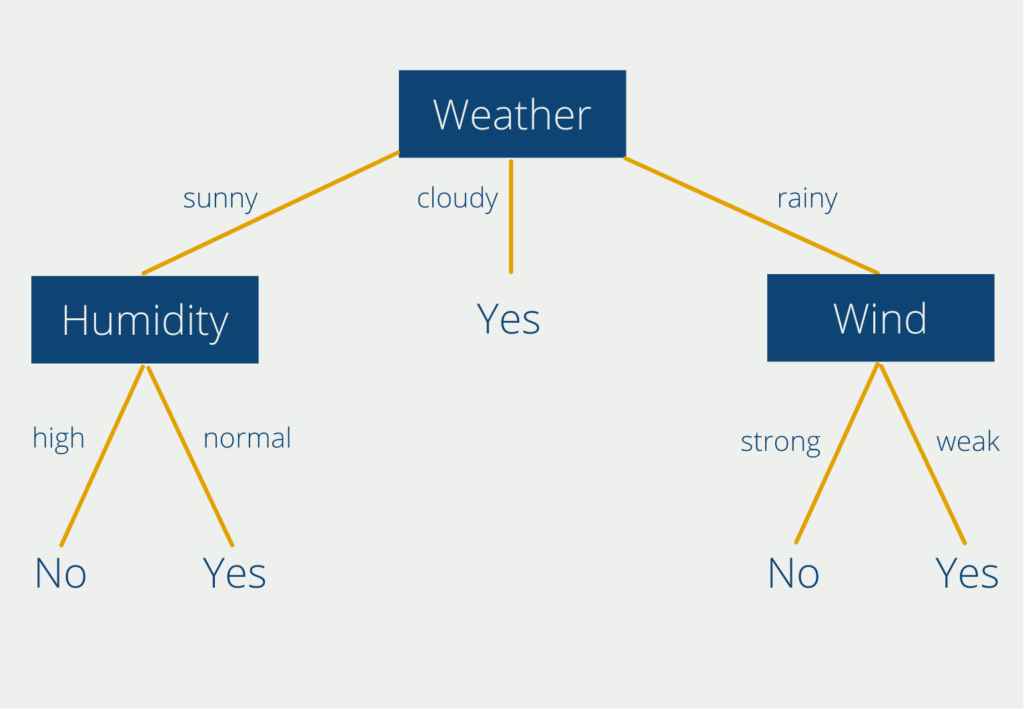
This tree helps to decide whether to do sports outside or not, depending on the weather variables “weather”, “humidity” and “wind force”. The decision tree visualizes the classification of the answers into “Yes” and “No” and clarifies very simply when you can do sports outside and when not. You can find the detailed explanation in our own post on Decision Trees.
Unfortunately, decision trees can tend to overfit very quickly. This means that the algorithm becomes too accustomed to the training data and learns it by heart. As a result, it performs very poorly on new, unseen data.
In machine learning, the goal is actually always to train an algorithm that learns certain capabilities from a training data set and can then apply them to new data. For this reason, decision trees are rarely used nowadays, and instead very similar random forests are resorted to. This is made possible by the so-called Ensemble Method, which will be explained in more detail in the next section.
What is the Random Forest Algorithm?
The Random Forest consists of a large number of these decision trees, which work together as a so-called ensemble. Each individual decision tree makes a prediction, such as a classification result, and the forest uses the result supported by most of the decision trees as the prediction of the entire ensemble. Why are multiple decision trees so much better than a single one?
The secret behind the Random Forest is the so-called principle of the wisdom of crowds. The basic idea is that the decision of many is always better than the decision of a single individual or a single decision tree. This concept was first recognized in the estimation of a continuous set.
In 1906, an ox was shown to a total of 800 people at a fair. They were asked to estimate how heavy this ox was before it was actually weighed. It turned out that the median of the 800 estimates was only about 1% away from the actual weight of the ox. No single estimate had come that close to being correct. So the crowd as a whole had estimated better than any other single person.
This can be applied in exactly the same way to the Random Forest. A large number of decision trees and their aggregated prediction will always outperform a single decision tree.

However, this is only true if the trees are not correlated with each other and thus the errors of a single tree are compensated by other Decision Trees. Let us return to our example with the ox weight at the fair.
The median of the estimates of all 800 people only has the chance to be better than each individual person, if the participants do not agree with each other, i.e. are uncorrelated. However, if the participants discuss together before the estimation and thus influence each other, the wisdom of the many no longer occurs.
What is Bagging?
In order for the random forest to produce good results, we must therefore ensure that the individual decision trees are not correlated with each other. We use what is called bagging. It is a method within Ensemble Algorithms that ensures that different models are trained on different subsets of the dataset.
Decision trees are very sensitive to their training data. A small change in the data can already lead to a significantly different tree structure. We take advantage of this property when bagging. Each tree within the forest is therefore trained on a sample of the training data set, which prevents the trees from being correlated with each other.
Each tree is still trained on a training dataset with the length of the original dataset, even though a sample was taken. This is done by replacing the missing values. Suppose our original data set is the list [1,2,3,4,5,6] with a length of six. A possible sample from this is [1,2,4,6], which we extend by the 2 and 6 so that we again get a list of length six: [1,2,2,4,6,6]. Bagging is the process of taking a sample of the data set and “augmenting” it with elements from the sample back to the original size.
Application Areas of the Random Forest algorithm
Random Forest models are used for classification tasks and regression analyses, similar to decision trees. These find application in many fields, such as medicine, e-commerce, and finance. Real random forest examples can be found in these areas:
- Predict stock prices
- Assess the creditworthiness of a bank customer
- Diagnose illness based on medical records
- Predict consumer preferences based on purchase history
What are the Advantages of Random Forests?
There are some good reasons why you should use random forests in classification tasks. Here are the most common ones:
- Better performance: As we have explained several times at this point, the performance of an ensemble algorithm is on average better than that of a single model.
- Lower risk of overfitting: Decision trees have a strong tendency to memorize the training dataset, i.e., to get into overfitting. The median of uncorrelated decision trees, on the other hand, is not as susceptible and therefore provides better results for new data.
- Reproducible decisions: While finding results in a random forest is more confusing than with a single decision tree, it is still comprehensible at its core. Comparable algorithms, such as neural networks, offer no way to understand how the result was reached.
- Lower computing power: A random forest can be trained relatively quickly on today’s computers since the hardware requirements are not as high as for other machine learning models.
- Low Demands on Data Quality: It has already been proven in various papers that random forests can handle outliers and unevenly distributed data very well. Thus, significantly less processing of data sets is required than is the case with other algorithms.
When should you not use Random Forests?
Although random forests are an alternative to consider in many use cases, there are also situations where they are not suitable.
Random forests should be used mainly for classification tasks where all classes with a few examples are present in the training data set. However, they are unsuitable for predicting new classes or values, as we know them from linear regressions or neural networks, for example.
Although training random forests is relatively fast, a single classification takes a relatively long time. So if you have a use case where real-time predictions need to be made, other algorithms may be more suitable.
If the training dataset is very unevenly populated, meaning that some classes have very few records. The samples in the bagging process suffer from this, which in turn has a negative impact on the model performance.
Random Forest vs. AdaBoost
The Random Forest also uses many decision trees, like AdaBoost, but with the difference that they all get the same training data and also the same weight in the final prediction. Furthermore, the trees can contain many decision paths and are not limited to only one level as in AdaBoost. In addition, AdaBoost changes the weights of individual data points if they were not properly classified by the previous model. Thus, the individual “decision stumps” are trained on slightly different data sets, unlike the Random Forest.
However, these small changes to the architecture sometimes have a big impact in practice:
- Training speed: Since the decision trees in the random forest are independent of each other, the training of the trees can be parallelized and distributed to different servers. This reduces the training time. The AdaBoost algorithm, on the other hand, cannot be parallelized due to the sequential arrangement, since the next decision stump cannot be trained until the previous one has been completed.
- Prediction Speed: However, when it comes to the actual application, i.e. when the models are trained out and have to classify new data, the whole thing turns around. That is, for Inference, AdaBoost is faster than Random Forest because the predictions in full-grown trees and that too in multitude take significantly more time than AdaBoost.
- Overfitting: The Decision Stump in AdaBoost that produces few errors has a high weighting for the final prediction, while another stump that produces many errors has little predictive power. In the Random Forest, on the other hand, the significance of all trees is identical, regardless of how good or bad their results were. Thus, the chance of overfitting is much lower with Random Forest than with an AdaBoost model.
This is what you should take with you
- The Random Forest is a supervised machine learning algorithm, which is composed of individual decision trees.
- It is based on the principle of the wisdom of crowds, which states that a joint decision of many uncorrelated components is better than the decision of a single component.
- Bagging is used to ensure that the decision trees are not correlated to each other.
- The Random Forest is used in medicine as well as in the financial and banking sectors.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!

What is the Singular Value Decomposition?
Unlocking insights and patterns: Learn the power of Singular Value Decomposition (SVD) in data analysis. Discover its applications.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.
Other Articles on the Topic of Random Forests
- Scikit-Learn provides a brief explanation of Random Forests and a description of how to implement them in Python.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.