Conditional Random Fields (CRFs) sind eine leistungsstarke Technik des maschinellen Lernens, die für Sequenzkennzeichnungsaufgaben verwendet wird. Sie werden unter anderem in der natürlichen Sprachverarbeitung, der Spracherkennung, der Computer Vision und der Bioinformatik eingesetzt. CRFs sind eine Art probabilistisches grafisches Modell, das die Vorhersage einer Sequenz von Kennzeichnungen auf der Grundlage einer Sequenz von Beobachtungen ermöglicht. Sie unterscheiden sich von anderen grafischen Modellen dadurch, dass sie sowohl lokale als auch globale Abhängigkeiten zwischen Beobachtungen berücksichtigen können, wodurch genauere Vorhersagen möglich sind.
In diesem Artikel geben wir einen detaillierten Überblick über CRFs, einschließlich ihrer Architektur, Trainings- und Inferenzmethoden, Anwendungen und Einschränkungen. Wir erörtern die Hauptmerkmale, die sie zu einem effektiven Werkzeug für die Sequenzkennzeichnung machen, sowie die mit ihrer Verwendung verbundenen Herausforderungen. Wir werden auch populäre Softwarepakete und Bibliotheken, die Implementierungen anbieten, zusammen mit Codebeispielen und Tutorials untersuchen.
Was sind Wahrscheinlichkeitsrechnung und grafische Modelle?
Die Wahrscheinlichkeitstheorie und grafische Modelle bilden die Grundlage für Conditional Random Fields. Um zu verstehen, wie CRFs funktionieren, ist es wichtig, ein grundlegendes Verständnis dieser Konzepte zu haben.
Die Wahrscheinlichkeitstheorie ist ein mathematischer Rahmen für die Modellierung von Unsicherheit. Sie ermöglicht es uns, die Wahrscheinlichkeit verschiedener Ergebnisse oder Ereignisse zu quantifizieren und über die Unsicherheit unserer Vorhersagen nachzudenken. Im Zusammenhang mit CRFs wird die Wahrscheinlichkeitstheorie zur Modellierung der Wahrscheinlichkeitsverteilung der Labelsequenz bei der beobachteten Eingabesequenz verwendet.
Grafische Modelle sind eine visuelle Darstellung von probabilistischen Beziehungen zwischen Variablen. In einem grafischen Modell stellen die Knoten die Variablen und die Kanten die probabilistischen Abhängigkeiten zwischen diesen Variablen dar. Es gibt zwei Haupttypen von grafischen Modellen: Bayes’sche Netze und Markov-Zufallsfelder.
Bayes’sche Netze sind gerichtete grafische Modelle, die die bedingten Abhängigkeiten zwischen Variablen darstellen. Sie werden häufig in der Entscheidungsfindung und Risikoanalyse eingesetzt.
Markov-Random-Fields hingegen sind ungerichtete grafische Modelle, die die gemeinsame Verteilung über einen Satz von Variablen darstellen. Sie werden häufig in der Bildanalyse, dem Computersehen und der Analyse sozialer Netzwerke verwendet.
CRFs sind eine Art von Markov-Random-Fields, die die Wahrscheinlichkeitsverteilung der Label-Sequenz in Abhängigkeit von der beobachteten Input-Sequenz modellieren. Jede Beobachtung ist mit einer Bezeichnung verknüpft, und das Ziel ist die Vorhersage der wahrscheinlichsten Bezeichnungssequenz angesichts der Beobachtungen. Die Kanten stellen die Abhängigkeiten zwischen benachbarten Labels dar, die mit Hilfe von Merkmalsfunktionen modelliert werden können, die die Beziehungen zwischen den Labels und den Beobachtungen erfassen.
Durch die Modellierung der Markierungssequenz als Markov-Random-Field können diese Modelle sowohl lokale als auch globale Abhängigkeiten zwischen den Markierungen erfassen, was sie zu einem leistungsstarken Werkzeug für Sequenzmarkierungsaufgaben wie Part-of-Speech-Tagging, Named-Entity-Erkennung und Spracherkennung macht.
Was sind Conditional Random Fields?
Bedingte Zufallsfelder (Conditional Random Fields) sind eine Art probabilistisches grafisches Modell, das für Sequenzetikettierungsaufgaben verwendet wird. Bei einem CRF besteht das Ziel darin, die wahrscheinlichste Kennzeichnungssequenz für eine gegebene Folge von Beobachtungen vorherzusagen.
Der Grundgedanke besteht darin, die Wahrscheinlichkeitsverteilung der Beschriftungssequenz in Abhängigkeit von den Beobachtungen zu modellieren. Dies geschieht durch die Konstruktion eines Markov-Random-Fields (MRF), in dem jeder Knoten ein Label und jede Kante eine Abhängigkeit zwischen benachbarten Labels darstellt. Das MRF wird durch einen Satz von Merkmalsfunktionen definiert, die die Beziehung zwischen den Beobachtungen und den Kennzeichnungen erfassen. Diese Merkmalsfunktionen werden in der Regel als eine Funktion des Labels und der Beobachtungen definiert und können entweder binär oder reellwertig sein.
Um eine Vorhersage treffen zu können, muss das CRF-Modell mit Hilfe eines Maximum-Likelihood-Ansatzes auf einem beschrifteten Datensatz trainiert werden. Dazu müssen die Gewichte gefunden werden, die die Wahrscheinlichkeit der beobachteten Markierungssequenzen angesichts der Eingabesequenzen maximieren. Dies geschieht in der Regel mithilfe eines Optimierungsalgorithmus wie dem stochastischen Gradientenabstieg.
Sobald das Modell trainiert ist, kann es verwendet werden, um Vorhersagen für neue Eingabesequenzen zu treffen, indem die Beschriftungssequenz gefunden wird, die die bedingte Wahrscheinlichkeit P(Y | X) maximiert. Dies kann mit einem Inferenzalgorithmus wie dem Viterbi-Algorithmus geschehen, der die wahrscheinlichste Label-Sequenz durch dynamische Programmierung effizient berechnet.
Insgesamt sind CRFs ein leistungsfähiges Werkzeug für Sequenzkennzeichnungsaufgaben, da sie sowohl lokale als auch globale Abhängigkeiten zwischen den Kennzeichnungen erfassen können, was sie genauer macht als einfachere Modelle wie Hidden-Markov-Modelle. Sie sind in der natürlichen Sprachverarbeitung, der Spracherkennung und anderen Bereichen, in denen eine Sequenzkennzeichnung erforderlich ist, weit verbreitet.
Wie ist die Architektur von Conditional Random Fields aufgebaut?
Die Conditional Random Field-Architektur, allgemein als Cry-Architektur bezeichnet, ist eine Deep-Learning-Architektur, die CRFs in ein neuronales Netzwerk einbezieht. Die Cry-Architektur wurde entwickelt, um die Leistung neuronaler Netze für Sequenzkennzeichnungsaufgaben wie Named Entity Recognition, Part-of-Speech Tagging und Spracherkennung zu verbessern.
Die Cry-Architektur besteht aus drei Hauptkomponenten: einem neuronalen Netzwerk, einer CRF-Schicht und einer Softmax-Schicht. Die Komponente des neuronalen Netzes ist für die Extraktion von Merkmalen aus der Eingabesequenz und die Erstellung einer Folge von versteckten Darstellungen verantwortlich. Die CRF-Schicht modelliert die Abhängigkeiten zwischen benachbarten Bezeichnungen und berechnet die bedingte Wahrscheinlichkeit der Bezeichnungssequenz in Abhängigkeit von der Eingabesequenz. Schließlich erzeugt die Softmax-Schicht eine Wahrscheinlichkeitsverteilung über die möglichen Etikettenfolgen.
Bei der neuronalen Netzwerkkomponente der Cry-Architektur kann es sich um jede Art von neuronalem Netzwerk handeln, z. B. um ein Faltungsnetzwerk (CNN), ein rekurrentes neuronales Netzwerk (RNN) oder eine Kombination aus beiden. Die neuronale Netzwerkkomponente wird in der Regel für eine überwachte Aufgabe wie Bildklassifizierung oder Sprachmodellierung vortrainiert und dann für die Aufgabe der Sequenzkennzeichnung feinabgestimmt.
Die CRF-Schicht der Cry-Architektur ist dem zuvor beschriebenen Modell ähnlich. Sie modelliert die Abhängigkeiten zwischen benachbarten Kennzeichnungen mithilfe einer Reihe von Merkmalsfunktionen, die die Beziehung zwischen den Beobachtungen und den Kennzeichnungen erfassen. Diese Merkmalsfunktionen werden auf der Grundlage der versteckten Repräsentationen berechnet, die von der neuronalen Netzwerkkomponente erzeugt werden.
Die Softmax-Schicht der Cry-Architektur erzeugt eine Wahrscheinlichkeitsverteilung über die möglichen Etikettenfolgen. Sie nimmt als Eingabe die von der CRF-Schicht berechnete bedingte Wahrscheinlichkeit der Etikettenfolge und normalisiert sie, um eine gültige Wahrscheinlichkeitsverteilung zu erzeugen. Die Softmax-Schicht wird mit Hilfe eines Maximum-Likelihood-Ansatzes trainiert, wobei das Ziel darin besteht, die logarithmische Wahrscheinlichkeit der korrekten Etikettensequenz angesichts der Eingabesequenz zu maximieren.
Insgesamt ist die Cry-Architektur ein leistungsstarkes Werkzeug für Sequenzetikettierungsaufgaben, da sie die Stärken von neuronalen Netzen und CRFs kombiniert. Die neuronale Netzwerkkomponente ist in der Lage, komplexe Merkmalsrepräsentationen der Eingabesequenz zu erlernen, während die CRF-Schicht die Abhängigkeiten zwischen benachbarten Bezeichnungen modelliert und die Struktur des Ausgaberaums erfasst. Es hat sich gezeigt, dass die Cry-Architektur bei einer Vielzahl von Sequenzetikettierungsaufgaben in der Verarbeitung natürlicher Sprache, der Spracherkennung und anderen Bereichen Spitzenleistungen erbringt.
Was sind die Anwendungen von CRF?
Bedingte Zufallsfelder finden in verschiedenen Bereichen breite Anwendung, was ihre Vielseitigkeit und Effektivität unter Beweis stellt. In der natürlichen Sprachverarbeitung (NLP) sind sie besonders gut für Aufgaben wie Part-of-Speech-Tagging, Named-Entity-Erkennung und Textsegmentierung geeignet, bei denen Sätze verarbeitet und verschiedenen Elementen Etiketten zugewiesen werden.
Bei der Spracherkennung glänzen CRFs durch die Kennzeichnung von Sprachsignalrahmen mit Phonemen oder Wörtern, wobei die Kontextinformationen zwischen benachbarten Rahmen für genaue Vorhersagen genutzt werden.
Die Computer Vision profitiert von diesen Modellen bei der Bildsegmentierung und Objekterkennung. Hier sind Bilder die Eingabe, und die Modelle ordnen bestimmten Regionen oder Objekten Etiketten zu und ermöglichen so eine fortgeschrittene Bildanalyse.
In der Genomik spielen CRFs eine entscheidende Rolle bei der Vorhersage von Genen und RNA-Strukturen. Sie arbeiten mit DNA- oder RNA-Sequenzen und ordnen Etiketten zu, um wichtige Regionen und Objekte zu identifizieren.
Auch in der Bioinformatik zeichnen sich diese Modelle bei der Vorhersage von Protein-Sekundärstrukturen und Protein-Protein-Interaktionen durch die Kennzeichnung von Proteinsequenzen aus, um relevante Sekundärstrukturen oder Interaktionen zu identifizieren.
Insgesamt haben sich CRFs als leistungsstarkes Werkzeug für Sequenzmarkierungsaufgaben in verschiedenen Bereichen erwiesen. Mit der zunehmenden Verfügbarkeit von markierten Daten und der Entwicklung neuer Deep-Learning-Architekturen, die CRFs einbeziehen, können wir davon ausgehen, dass diese Modelle auch in Zukunft eine beliebte Wahl für Sequenzmarkierungsaufgaben sein werden.
Wie implementiert man das Conditional Random Field in Python?
In diesem Abschnitt werden wir untersuchen, wie man ein Modell mit der sklearn-crfsuite-Bibliothek in Python erstellt. Wir werden den beliebten Datensatz CoNLL 2003 verwenden, der öffentlich zugänglich ist und häufig für Aufgaben der Named Entity Recognition (NER) verwendet wird.
- Installieren der benötigten Bibliotheken: Bevor Du beginnst, solltest Du die notwendigen Bibliotheken installieren. Verwende
pip, umsklearn-crfsuiteundnumpyzu installieren:

- Laden und Vorbereiten der Daten: Lade den CoNLL 2003-Datensatz herunter, der aus kommentierten englischen und deutschen Nachrichtenartikeln besteht. Lade den Datensatz in Deine Python-Umgebung und bereite ihn in das gewünschte Format vor. Teile die Daten in Sätze auf und extrahiere die Wörter und die entsprechenden Named Entity Labels.
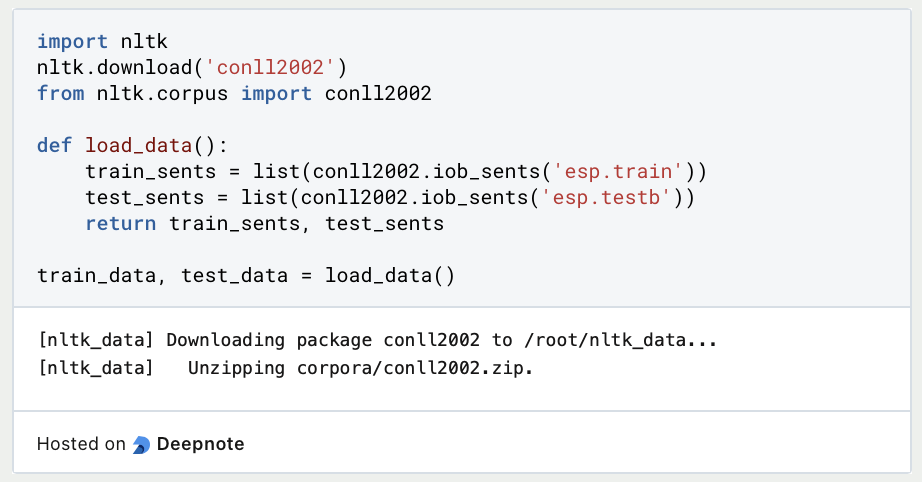
- Feature Extraction: Definiere die Merkmale, die Du in Deinem Modell verwenden möchtest. Zu den üblichen Merkmalen gehören Merkmale auf Wortebene, Part-of-Speech-Tags und Kontextinformationen. Extrahiere die Merkmale für jedes Token in Deinem Datensatz.
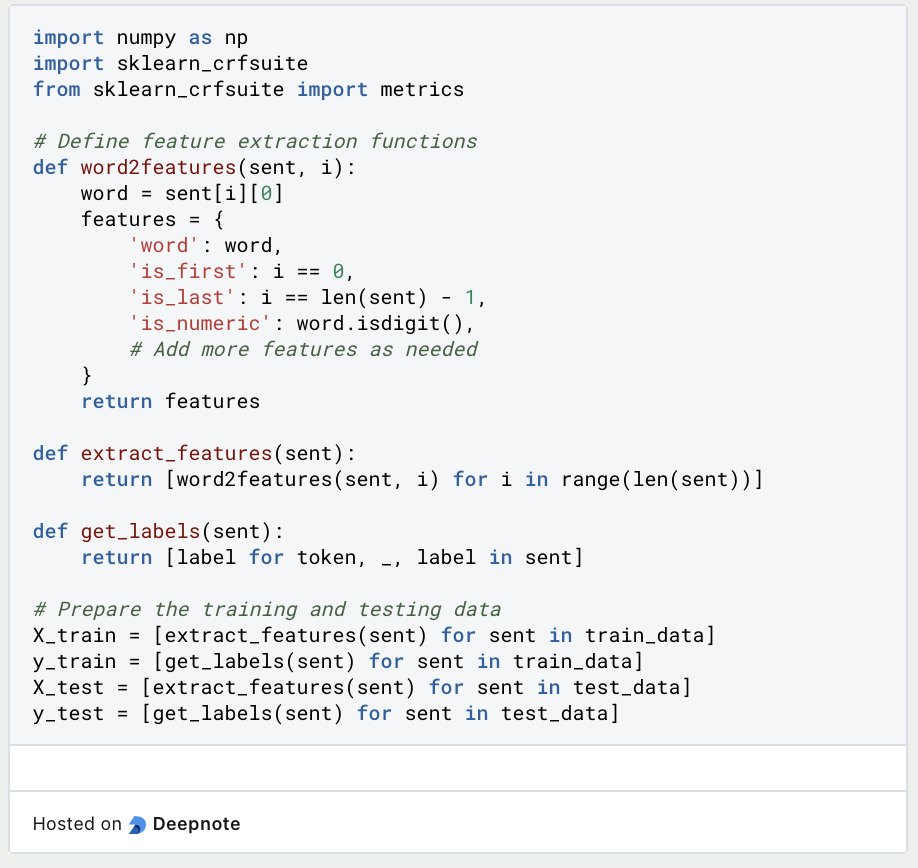
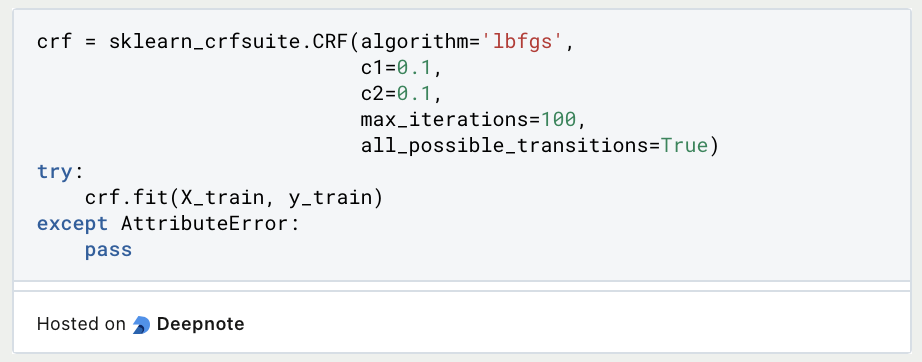
- Trainiere das Modell: Erstelle eine Instanz der CRF-Klasse aus
sklearn-crfsuite. Konfiguriere die Modellparameter, falls erforderlich, und trainiere das Modell mit den Trainingsdaten.
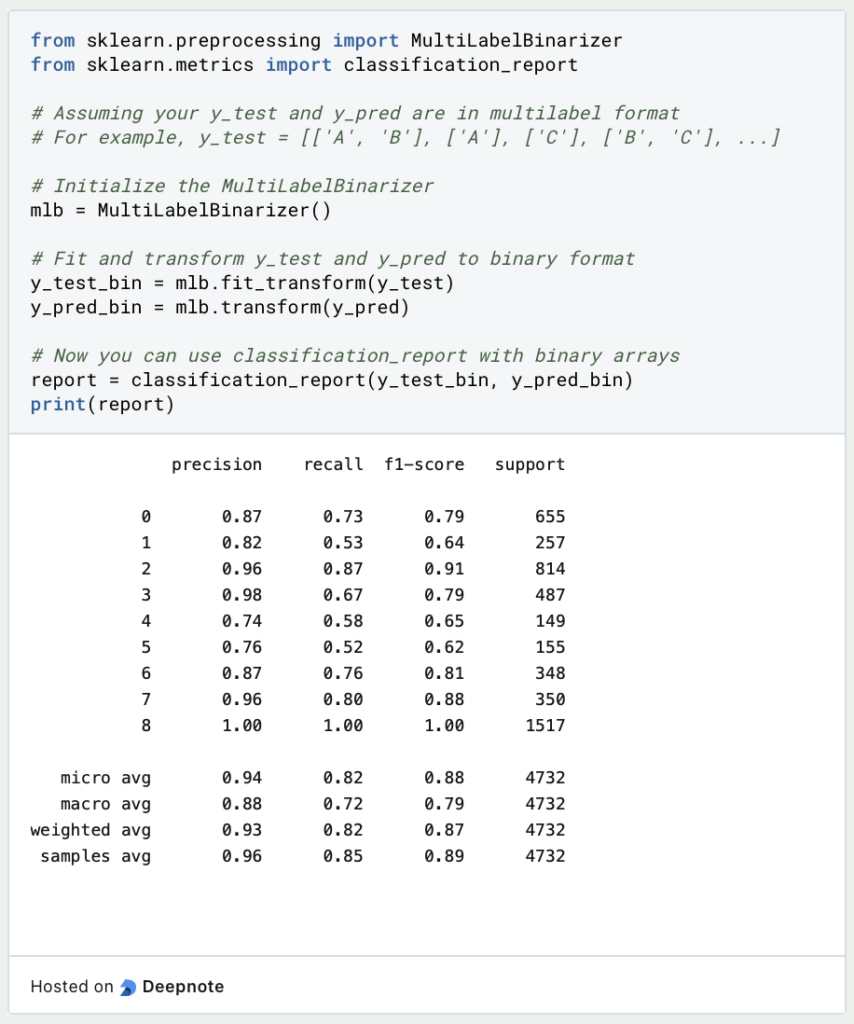
- Treffe Vorhersagen und bewerte das Modell: Sobald das Modell trainiert ist, kannst Du es verwenden, um Vorhersagen für neue, ungesehene Daten zu treffen. Übergebe die extrahierten Merkmale der neuen Daten an die Vorhersagemethode des trainierten Modells. Bewerte die Leistung des Modells anhand von Metriken wie Präzision, Recall und F1-Score.
- Fine-tuning des Modells: Experimentiere mit verschiedenen Merkmalen, Hyperparametern und Modellkonfigurationen, um die Leistung Deines CRF-Modells zu verbessern. Iteriere und verfeinere Deinen Ansatz auf der Grundlage der Bewertungsergebnisse.
Wenn Du diese Schritte befolgst und den CoNLL 2003-Datensatz verwendest, kannst Du mit der sklearn-crfsuite-Bibliothek ein Modell in Python erstellen. Passe die Funktionen zur Merkmalsextraktion an und untersuche zusätzliche Merkmale, um die Leistung des Modells zu verbessern. CRFs sind leistungsstarke Modelle für Sequenzetikettierungsaufgaben wie die Erkennung benannter Entitäten, und mit dem richtigen Datensatz und der richtigen Merkmalstechnik kannst Du genaue Ergebnisse erzielen.
Was sind die Vor- und Nachteile von Conditional Random Fields?
Wie jede Technik des maschinellen Lernens haben auch Conditional Random Fields eine Reihe von Vor- und Nachteilen. Hier sind einige von ihnen:
Vorteile:
- CRFs sind in der Lage, Abhängigkeiten zwischen benachbarten Kennzeichnungen zu erfassen, was sie zu einem leistungsstarken Werkzeug für Sequenzkennzeichnungsaufgaben macht.
- Diese Modelle sind flexibel und können verschiedene Arten von Merkmalen einbeziehen, z. B. manuell erstellte Merkmale, Merkmale aus neuronalen Netzen oder eine Kombination aus beidem.
- CRFs sind probabilistische Modelle, was bedeutet, dass sie Unsicherheitsschätzungen und Vertrauenswerte für ihre Vorhersagen liefern können.
- Diese Modelle sind relativ einfach zu interpretieren, da sie die Abhängigkeiten zwischen benachbarten Labels explizit modellieren.
Nachteile:
- CRFs können sehr rechenintensiv sein, insbesondere bei langen Sequenzen oder großen Ausgaberäumen.
- Die Leistung hängt stark von der Qualität der Eingabemerkmale ab. Schlecht konzipierte Merkmale können zu einer suboptimalen Leistung führen.
- CRFs können unter dem Label-Bias-Problem leiden, bei dem die vorhergesagten Labels in Richtung häufiger Labels in den Trainingsdaten verzerrt sind.
- Für das Training dieser Modelle werden beschriftete Daten benötigt, deren Beschaffung zeitaufwändig und teuer sein kann.
Insgesamt sind CRFs ein leistungsfähiges Werkzeug für Sequenzetikettierungsaufgaben, aber ihre Leistung hängt von der Qualität der Eingangsmerkmale und der Größe des Ausgaberaums ab. Forscher und Praktiker müssen die Vor- und Nachteile sorgfältig abwägen, wenn sie entscheiden, ob sie für eine bestimmte Aufgabe eingesetzt werden sollen.
Das solltest Du mitnehmen
- CRFs sind probabilistische grafische Modelle, die für Sequenzetikettierungsaufgaben verwendet werden.
- Sie sind in vielen Bereichen nützlich, z. B. bei der Verarbeitung natürlicher Sprache, der Spracherkennung, dem Computersehen, der Genomik und der Bioinformatik.
- CRFs können Abhängigkeiten zwischen benachbarten Markierungen erfassen, was sie zu einem leistungsstarken Werkzeug für Sequenzmarkierungsaufgaben macht.
- Sie sind flexibel und können verschiedene Arten von Merkmalen einbeziehen.
- CRFs können Unsicherheitsschätzungen und Vertrauenswerte für ihre Vorhersagen liefern.
- Sie sind relativ einfach zu interpretieren, da sie die Abhängigkeiten zwischen benachbarten Markierungen explizit modellieren.
- CRFs können jedoch rechenintensiv sein, und ihre Leistung hängt stark von der Qualität der Eingangsmerkmale ab.
- Sie können unter dem Problem der Verzerrung von Kennzeichnungen leiden und erfordern gekennzeichnete Daten für das Training, deren Beschaffung zeitaufwändig und teuer sein kann.
- Insgesamt sind CRFs ein nützliches Werkzeug für Sequenzkennzeichnungsaufgaben, und ihre Vor- und Nachteile müssen sorgfältig abgewogen werden, wenn entschieden wird, ob sie für eine bestimmte Aufgabe verwendet werden sollen.
Vielen Dank an Deepnote für das Sponsoring dieses Artikels! Deepnote bietet mir die Möglichkeit, Python-Code einfach und schnell auf dieser Website einzubetten und auch die zugehörigen Notebooks in der Cloud zu hosten.

Was ist die Lernrate?
Entfalten Sie die Kraft der Lernraten beim maschinellen Lernen: Tauchen Sie ein in Strategien, Optimierung und Feinabstimmung für Modelle.

Was ist die Random Search?
Optimieren Sie Modelle für maschinelles Lernen: Lernen Sie, wie die Random Search Hyperparameter effektiv abstimmt.

Was ist die Lasso Regression?
Entdecken Sie die Lasso Regression: ein leistungsstarkes Tool für die Vorhersagemodellierung und die Auswahl von Merkmalen.

Was ist der Omitted Variable Bias?
Verständnis des Omitted Variable Bias: Ursachen, Konsequenzen und Prävention. Erfahren Sie, wie Sie diese Falle vermeiden.

Was ist der Adam Optimizer?
Entdecken Sie den Adam Optimizer: Lernen Sie den Algorithmus kennen und erfahren Sie, wie Sie ihn in Python implementieren.

Was ist One-Shot Learning?
Beherrsche One-Shot Learning: Techniken zum schnellen Wissenserwerb und Anpassung. Steigere die KI-Leistung mit minimalen Trainingsdaten.
Andere Beiträge zum Thema Conditional Random Field
Dieser Link führt Dich zu meiner Deepnote-App, in der Du den gesamten Code findest, den ich in diesem Artikel verwendet habe, und ihn selbst ausführen kannst.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.