Conditional Random Fields (CRFs) are a powerful machine learning technique used for sequence labeling tasks. They have been widely used in natural language processing, speech recognition, computer vision, and bioinformatics, among other fields. CRFs are a type of probabilistic graphical model that allows for the prediction of a sequence of labels based on a sequence of observations. They differ from other graphical models in that they can take into account both local and global dependencies between observations, allowing for more accurate predictions.
In this article, we will provide an in-depth overview of CRFs, including their architecture, training and inference methods, applications, and limitations. We will discuss the key features of CRFs that make them an effective tool for sequence labeling, as well as the challenges associated with their use. We will also explore popular software packages and libraries that provide implementations, along with code examples and tutorials.
What are probability theory and graphical models?
Probability theory and graphical models form the foundation of Conditional Random Fields. In order to understand how CRFs work, it is important to have a basic understanding of these concepts.
Probability theory is a mathematical framework for modeling uncertainty. It allows us to quantify the likelihood of different outcomes or events, and to reason about the uncertainty in our predictions. In the context of CRFs, probability theory is used to model the probability distribution of the label sequence given the observed input sequence.
Graphical models are a visual representation of probabilistic relationships between variables. In a graphical model, nodes represent variables, and edges represent probabilistic dependencies between those variables. There are two main types of graphical models: Bayesian networks and Markov Random Fields.
Bayesian networks are directed graphical models that represent the conditional dependencies between variables. They are commonly used in decision-making and risk analysis.
Markov Random Fields, on the other hand, are undirected graphical models that represent the joint distribution over a set of variables. They are commonly used in image analysis, computer vision, and social network analysis.
CRFs are a type of Markov Random Field that models the probability distribution of the label sequence given the observed input sequence. Each observation is associated with a label, and the goal is to predict the most likely label sequence given the observations. The edges represent the dependencies between adjacent labels, which can be modeled using feature functions that capture the relationships between the labels and the observations.
By modeling the label sequence as a Markov Random Field, these models can capture both local and global dependencies between the labels, making them a powerful tool for sequence labeling tasks such as part-of-speech tagging, named entity recognition, and speech recognition.
What are Conditional Random Fields?
Conditional Random Fields are a type of probabilistic graphical model that is used for sequence labeling tasks. In a CRF, the goal is to predict the most likely label sequence for a given sequence of observations.
The key idea behind it is to model the probability distribution of the label sequence given the observations. This is done by constructing a Markov Random Field (MRF) in which each node represents a label and each edge represents a dependency between adjacent labels. The MRF is defined by a set of feature functions that capture the relationship between the observations and the labels. These feature functions are typically defined as a function of the label and the observations and can be either binary or real-valued.
In order to make a prediction, the CRF model must be trained on a labeled dataset using a maximum likelihood approach. This involves finding the weights that maximize the likelihood of the observed label sequences given the input sequences. This is typically done using an optimization algorithm such as stochastic gradient descent.
Once the model is trained, it can be used to make predictions on new input sequences by finding the label sequence that maximizes the conditional probability P(Y | X). This can be done using an inference algorithm such as the Viterbi algorithm, which efficiently computes the most likely label sequence by dynamic programming.
Overall, CRFs are a powerful tool for sequence labeling tasks because they can capture both local and global dependencies between the labels, making them more accurate than simpler models such as Hidden Markov Models. They have been widely used in natural language processing, speech recognition, and other fields where sequence labeling is required.
What does the Architecture of a Conditional Random Field look like?
The Conditional Random Field architecture, commonly referred to as the Cry architecture, is a deep learning architecture that incorporates CRFs into a neural network framework. The Cry architecture is designed to improve the performance of neural networks for sequence labeling tasks such as named entity recognition, part-of-speech tagging, and speech recognition.
The Cry architecture consists of three main components: a neural network, a CRF layer, and a softmax layer. The neural network component is responsible for extracting features from the input sequence and producing a sequence of hidden representations. The CRF layer models the dependencies between adjacent labels and computes the conditional probability of the label sequence given the input sequence. Finally, the softmax layer produces a probability distribution over the possible label sequences.
The neural network component of the Cry architecture can be any type of neural network, such as a convolutional neural network (CNN), a recurrent neural network (RNN), or a combination of the two. The neural network component is typically pre-trained on a supervised task such as image classification or language modeling and then fine-tuned on the sequence labeling task.
The CRF layer of the Cry architecture is similar to the model described earlier. It models the dependencies between adjacent labels using a set of feature functions that capture the relationship between the observations and the labels. These feature functions are computed based on the hidden representations produced by the neural network component.
The softmax layer of the Cry architecture produces a probability distribution over the possible label sequences. It takes as input the conditional probability of the label sequence computed by the CRF layer and normalizes it to produce a valid probability distribution. The softmax layer is trained using a maximum likelihood approach, where the goal is to maximize the log-likelihood of the correct label sequence given the input sequence.
Overall, the Cry architecture is a powerful tool for sequence labeling tasks because it combines the strengths of neural networks and CRFs. The neural network component is able to learn complex feature representations of the input sequence, while the CRF layer models the dependencies between adjacent labels and captures the structure of the output space. The Cry architecture has been shown to achieve state-of-the-art performance on a wide range of sequence labeling tasks in natural language processing, speech recognition, and other fields.
What are the applications of CRF?
Conditional Random Fields find widespread application across various domains, demonstrating their versatility and effectiveness. Notably, in Natural Language Processing (NLP), they excel in tasks like part-of-speech tagging, named entity recognition, and text segmentation, where sentences are processed, and labels are assigned to different elements.
For Speech Recognition, CRFs shine by labeling speech signal frames with phonemes or words, leveraging the contextual information between adjacent frames for accurate predictions.
Computer Vision benefits from these models in image segmentation and object recognition. Here, images are the input, and CRFs assign labels to distinct regions or objects, enabling advanced image analysis.
In Genomics, CRFs play a crucial role in gene prediction and RNA structure prediction. They operate on DNA or RNA sequences, assigning labels to identify essential regions and structures.
Similarly, in Bioinformatics, these models excel in protein secondary structure prediction and protein-protein interaction prediction, labeling protein sequences to identify relevant secondary structures or interactions.
Overall, CRFs have proven to be a powerful tool for sequence labeling tasks in various fields. With the increasing availability of labeled data and the development of new deep learning architectures that incorporate CRFs, we can expect the models to continue to be a popular choice for sequence labeling tasks in the future.
How to implement the Conditional Random Field in Python?
In this section, we will explore how to build a model using the sklearn-crfsuite library in Python. We’ll use the popular CoNLL 2003 dataset, which is publicly available and widely used for named entity recognition (NER) tasks.
- Installing the Required Libraries:
Before getting started, make sure to install the necessary libraries. Use pip to installsklearn-crfsuiteandnumpy:

- Loading and Preparing the Data:
Download the CoNLL 2003 dataset, which consists of annotated English and German news articles. Load the dataset into your Python environment and preprocess it into the required format. Split the data into sentences and extract the words and corresponding named entity labels.
- Feature Extraction:
Define the features you want to use in your model. Common features include word-level features, part-of-speech tags, and contextual information. Extract the features for each token in your dataset.
- Training the Model:
Create an instance of theCRFclass fromsklearn-crfsuite. Configure the model parameters if needed, and train the model using the training data.
- Making Predictions and Evaluating the Model:
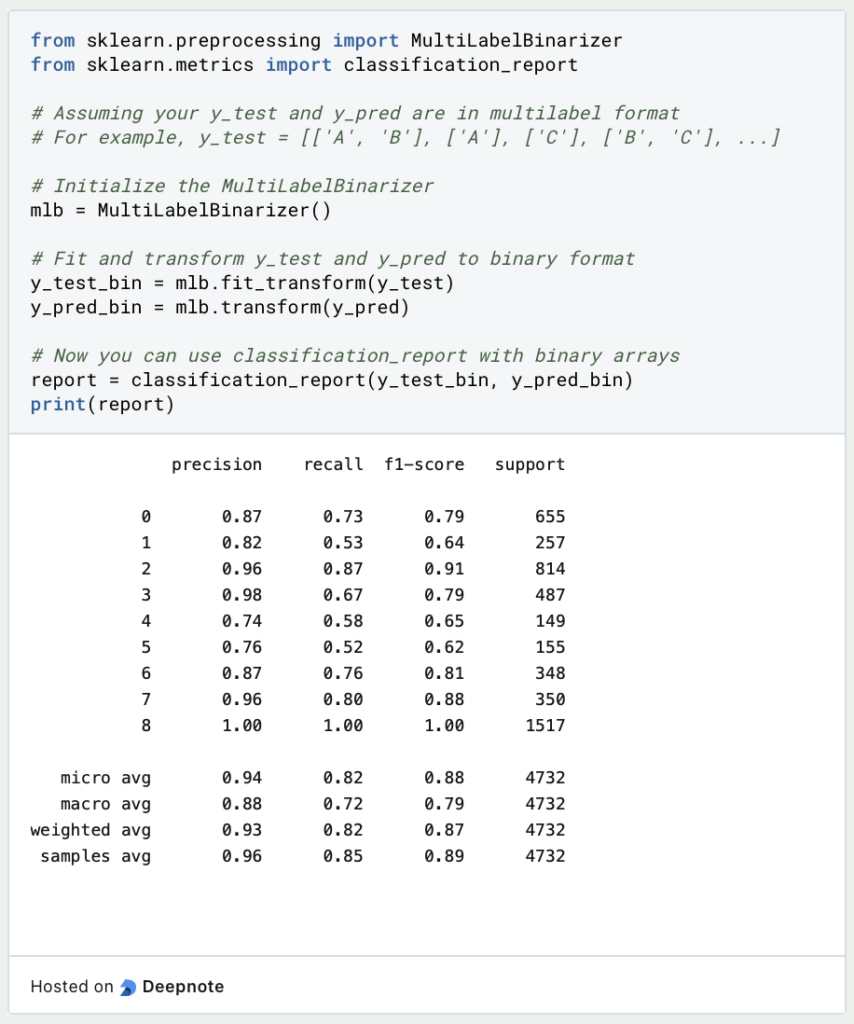
Once the model is trained, you can use it to make predictions on new, unseen data. Pass the extracted features of the new data to thepredictmethod of the trained model. Evaluate the performance of the model using metrics such as precision, recall, and F1-score.
- Fine-tuning the Model:
Experiment with different features, hyperparameters, and model configurations to improve the performance of your CRF model. Iterate and refine your approach based on the evaluation results.
By following these steps and using the CoNLL 2003 dataset, you can build a model in Python using the sklearn-crfsuite library. Customize the feature extraction functions and explore additional features to improve the model’s performance. CRFs are powerful models for sequence labeling tasks such as named entity recognition, and with the right dataset and feature engineering, you can achieve accurate results.
What are the advantages and disadvantages of Conditional Random Fields?
Like any Machine Learning technique, Conditional Random Fields have their own set of advantages and disadvantages. Here are some of them:
Advantages:
- CRFs are able to capture dependencies between adjacent labels, making them a powerful tool for sequence labeling tasks.
- These models are flexible and can incorporate various types of features, including hand-crafted features, neural network features, or a combination of both.
- CRFs are probabilistic models, which means that they can provide uncertainty estimates and confidence scores for their predictions.
- These models are relatively easy to interpret, since they model the dependencies between adjacent labels explicitly.
Disadvantages:
- CRFs can be computationally expensive, especially for long sequences or large output spaces.
- The performance depends heavily on the quality of the input features. Poorly designed features can result in suboptimal performance.
- CRFs can suffer from the label bias problem, where the predicted labels are biased towards frequent labels in the training data.
- These models require labeled data for training, which can be time-consuming and expensive to obtain.
Overall, CRFs are a powerful tool for sequence labeling tasks, but their performance depends on the quality of the input features and the size of the output space. Researchers and practitioners must carefully consider the advantages and disadvantages when deciding whether to use them for a particular task.
This is what you should take with you
- CRFs are probabilistic graphical models used for sequence labeling tasks.
- They are useful in many fields, including natural language processing, speech recognition, computer vision, genomics, and bioinformatics.
- CRFs can capture dependencies between adjacent labels, making them a powerful tool for sequence labeling tasks.
- They are flexible and can incorporate various types of features.
- CRFs can provide uncertainty estimates and confidence scores for their predictions.
- They are relatively easy to interpret since they model the dependencies between adjacent labels explicitly.
- However, CRFs can be computationally expensive, and their performance depends heavily on the quality of the input features.
- They can suffer from label bias problems and require labeled data for training, which can be time-consuming and expensive to obtain.
- Overall, CRFs are a useful tool for sequence labeling tasks, and their advantages and disadvantages must be carefully considered when deciding whether to use them for a particular task.
Thanks to Deepnote for sponsoring this article! Deepnote offers me the possibility to embed Python code easily and quickly on this website and also to host the related notebooks in the cloud.

What is the Adam Optimizer?
Unlock the Potential of Adam Optimizer: Get to know the basucs, the algorithm and how to implement it in Python.

What is One-Shot Learning?
Mastering one shot learning: Techniques for rapid knowledge acquisition and adaptation. Boost AI performance with minimal training data.

What is the Bellman Equation?
Mastering the Bellman Equation: Optimal Decision-Making in AI. Learn its applications & limitations. Dive into dynamic programming!

What is the Singular Value Decomposition?
Unlocking insights and patterns: Learn the power of Singular Value Decomposition (SVD) in data analysis. Discover its applications.

What is the Poisson Regression?
Learn about Poisson regression, a statistical model for count data analysis. Implement Poisson regression in Python for accurate predictions.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.
Other Articles on the Topic of Conditional Random Field
This link will get you to my Deepnote App where you can find all the code that I used in this article and can run it yourself.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.