Few-Shot Learning ist ein Teilbereich des maschinellen Lernens, der sich mit dem Problem des Lernens aus wenigen Beispielen befasst. Herkömmliche Algorithmen des maschinellen Lernens benötigen in der Regel eine große Menge an markierten Daten, um daraus zu lernen, aber in vielen realen Szenarien ist die Beschaffung solcher Daten unpraktisch oder sogar unmöglich.
Das Few-Shot-Lernen zielt darauf ab, diese Einschränkung zu überwinden, indem es nur aus einer kleinen Anzahl von Beispielen lernt, oft nur aus einem oder einigen wenigen. Dies ermöglicht die Anwendung des maschinellen Lernens auf Aufgaben wie die Klassifizierung von Bildern, die Verarbeitung natürlicher Sprache und die Robotik, bei denen beschriftete Daten knapp oder teuer sind. In diesem Artikel werden wir das Konzept des Few-Shot Learnings, seine Anwendungen und die zu seiner Umsetzung verwendeten Techniken untersuchen.
Welche Techniken werden beim Few-Shot Learning eingesetzt?
Few-Shot-Learning ist ein faszinierendes Gebiet, das die Grenzen des maschinellen Lernens erweitert, indem es Modelle in die Lage versetzt, aus nur wenigen markierten Beispielen zu lernen. Um diese bemerkenswerte Leistung zu erreichen, wurden verschiedene Techniken und Ansätze entwickelt, die jeweils ihre eigenen Vorteile haben. Lassen Sie uns diese Techniken im Detail erkunden:
Meta-Learning ist ein Ansatz, der sich auf das Lernen des Lernens konzentriert. Dabei werden Modelle trainiert, um einen allgemeinen Lernalgorithmus zu entwickeln, der sich schnell an neue Aufgaben oder Klassen anpassen kann. Beim Model-Agnostic Meta-Learning (MAML) beispielsweise werden Modelle so trainiert, dass sie eine Reihe anpassungsfähiger Anfangsparameter lernen, die mit einigen wenigen markierten Beispielen aus neuen Klassen feinabgestimmt werden können. Diese Meta-Learning-Fähigkeit ermöglicht es den Modellen, aus begrenzten Daten schnell zu verallgemeinern, was sie zu einer leistungsstarken Technik für das Lernen in wenigen Schritten macht.
Metrik-basierte Methoden verfolgen einen anderen Ansatz, indem sie die Ähnlichkeit zwischen den Beispielen betonen. Diese Methoden zielen darauf ab, eine Abstandsmetrik oder einen Einbettungsraum zu erlernen, in dem Stichproben aus derselben Klasse näher beieinander liegen, während Stichproben aus verschiedenen Klassen weiter voneinander entfernt sind. Siamesische Netze beispielsweise verwenden Zwillingsnetze, um Einbettungen für Probenpaare zu lernen und einen Ähnlichkeitswert auf der Grundlage des Abstands zwischen den Einbettungen zu berechnen. Relation Networks konzentrieren sich auf das Lernen von Beziehungsmodulen, um paarweise Beziehungen zwischen Proben zu erfassen.
Matching Networks verwenden Aufmerksamkeitsmechanismen, um eine gewichtete Summe von Einbettungen zu berechnen, die Vergleiche zwischen Unterstützungs- und Abfrageproben ermöglichen. Diese auf Metriken basierenden Methoden zeichnen sich durch die Messung von Ähnlichkeit und Unterscheidung aus und ermöglichen es den Modellen, mit begrenzten beschrifteten Daten genaue Vorhersagen zu treffen.
Generative Modelle verfolgen einen kreativen Ansatz, indem sie synthetische Beispiele erzeugen, die den markierten Beispielen ähneln. Diese Erweiterung der Trainingsdaten hilft dabei, das Problem der Datenknappheit zu entschärfen. Generative Adversarial Networks (GANs) werden üblicherweise für diesen Zweck verwendet, wobei ein Generator-Netzwerk lernt, realistische Beispiele zu erzeugen, die ein Diskriminator-Netzwerk täuschen. Variationale Autoencoder (VAEs) hingegen lernen, Daten zu kodieren und zu dekodieren und ermöglichen so die Erzeugung neuer Stichproben aus dem erlernten latenten Raum. Durch die Erweiterung der verfügbaren Daten mit Hilfe von generativen Modellen können Modelle, die mit wenigen Schritten lernen, die zugrundeliegenden Muster und Variationen besser erfassen und ihre Verallgemeinerungsfähigkeiten verbessern.
Techniken zur Datenerweiterung und -transformation bieten eine weitere Möglichkeit zur Verbesserung des few-shot learning. Durch die Anwendung verschiedener Transformationen auf vorhandene markierte Beispiele, wie z. B. Drehungen, Übersetzungen oder Verzerrungen, wird der Datensatz erweitert, wodurch die Vielfalt der verfügbaren Beispiele effektiv erhöht wird. Diese erweiterten Daten ermöglichen es den Modellen, aus einem breiteren Spektrum von Variationen zu lernen, was ihre Fähigkeit zur Generalisierung auf unbekannte Klassen und Szenarien verbessert.
Hybride Ansätze kombinieren mehrere Techniken, um ihre jeweiligen Stärken zu nutzen und Einschränkungen zu überwinden. Forscher erforschen häufig Kombinationen aus Meta-Learning, metrikbasierten Methoden und generativen Modellen, um eine überlegene Leistung beim Lernen in wenigen Schritten zu erzielen. Diese hybriden Ansätze zielen darauf ab, die Vorteile jeder Technik zu nutzen, z. B. die Fähigkeit, sich schnell anzupassen, Ähnlichkeit genau zu messen, zusätzliche Stichproben zu generieren und die verfügbaren Daten zu erweitern.
Indem wir in diese komplexen Techniken und Ansätze eintauchen, enthüllen wir das faszinierende Reich des few-shot learning. Forscher und Praktiker arbeiten kontinuierlich an der Innovation und Verfeinerung dieser Methoden, um die Grenzen dessen, was Maschinen mit begrenzten Daten erreichen können, zu erweitern. In dem Maße, in dem wir das wahre Potenzial des few-shot learning erschließen, öffnen wir die Türen für Anwendungen in Bereichen wie Computer Vision, natürliche Sprachverarbeitung und personalisierte Empfehlungssysteme, in denen eine schnelle Anpassung an neue Klassen entscheidend ist.
Was sind die Einschränkungen des Few-Shot Learnings?
Das Few-Shot-Lernen hat vielversprechende Ergebnisse bei der Bewältigung der Herausforderung des Lernens aus begrenzten markierten Daten gezeigt. Es ist jedoch wichtig, die mit diesem Ansatz verbundenen Einschränkungen zu berücksichtigen.
- Variabilität der Daten: Few-Shot Learning beruht auf der Annahme, dass die wenigen markierten Beispiele, die während des Trainings zur Verfügung gestellt werden, repräsentativ für die gesamte Klasse oder Kategorie sind. Wenn die verfügbaren Beispiele jedoch nicht vielfältig genug sind oder nicht das gesamte Spektrum der Variationen innerhalb der Klasse abdecken, kann das Modell nur schwer auf ungesehene Instanzen verallgemeinert werden.
- Begrenzte kontextuelle Informationen: Bei dieser Lernmethode fehlen oft die umfangreichen Kontextinformationen, die aus einem größeren Datensatz gewonnen werden können. Dies kann sich auf die Fähigkeit des Modells auswirken, komplexe Muster oder Abhängigkeiten innerhalb der Daten zu verstehen, was zu einer geringeren Leistung bei schwierigeren Aufgaben führt.
- Ungleichgewicht der Klassen: In Lernszenarien mit wenigen Daten ist die Anzahl der markierten Beispiele pro Klasse in der Regel gering, was zu einem Ungleichgewicht der Klassen führt. Dieses Ungleichgewicht kann das effektive Lernen des Modells erschweren, da es möglicherweise die dominanten Klassen überbetont und Schwierigkeiten bei der Generalisierung auf die Minderheitsklassen hat.
- Übertragbarkeit: Während sich Modelle, die mit wenigen Versuchen lernen, bei der Anpassung an neue Klassen innerhalb eines bekannten Bereichs auszeichnen, können sie Schwierigkeiten haben, wenn sie mit völlig neuen Bereichen oder Aufgaben konfrontiert werden, die sich erheblich von der Verteilung der Trainingsdaten unterscheiden. Die Fähigkeit, Wissen zu übertragen und effektiv zu verallgemeinern, bleibt in solchen Fällen eine Herausforderung.
- Empfindlichkeit gegenüber Rauschen: Bei einer begrenzten Anzahl von Trainingsbeispielen können die Modelle empfindlich auf Noise oder fehlerhafte Bezeichnungen reagieren. Rauschen in den wenigen verfügbaren beschrifteten Beispielen kann sich erheblich auf die Leistung des Modells auswirken und möglicherweise zu falschen Vorhersagen oder einer verminderten Generalisierungsfähigkeit führen.
- Notwendigkeit eines aufgabenspezifischen Designs: Few-shot-Lernansätze erfordern oft eine sorgfältige Entwicklung und Konstruktion von Modellarchitekturen, Algorithmen und Trainingsprotokollen. Es kann notwendig sein, diese Techniken auf bestimmte Aufgaben oder Bereiche zuzuschneiden, was ihre Anwendung in verschiedenen Szenarien erschwert.
Obwohl das few-shot learning bei der Bewältigung des Problems der Datenknappheit erhebliche Fortschritte gemacht hat, ist es wichtig, seine Grenzen anzuerkennen. Die Überwindung dieser Grenzen und die Entwicklung robusterer und skalierbarerer Methoden des “few-shot learning” bleibt ein aktives Forschungsgebiet.
Was sind die Unterschiede zwischen Few-Shot Learning und anderen Lernmethoden?
Few-shot learning ist eine einzigartige Lerntechnik, die sich in mehrfacher Hinsicht von den traditionellen Ansätzen des maschinellen Lernens unterscheidet. In diesem Abschnitt wird few-shot learning mit anderen Lerntechniken verglichen:
- Überwachtes Lernen: Beim Supervised Learning wird ein Modell auf einem großen markierten Datensatz trainiert, um Vorhersagen für ungesehene Daten zu treffen. Dazu ist eine beträchtliche Menge an markierten Daten für jede Klasse oder Kategorie erforderlich. Im Gegensatz dazu zielt das few-shot learning darauf ab, mit nur wenigen markierten Beispielen pro Klasse gute Ergebnisse zu erzielen, wodurch es sich besser für Szenarien mit begrenzten markierten Daten eignet.
- Transfer-Lernen: Beim Transfer Learning wird ein Modell zunächst auf einem großen Datensatz trainiert und dann mit einem kleineren markierten Datensatz für eine bestimmte Aufgabe feinabgestimmt. Während das Transferlernen effektiv ist, wenn die Zielaufgabe eine ähnliche Verteilung wie die Vortrainingsdaten aufweist, geht das few-shot learning einen Schritt weiter, indem es sich an neue Klassen oder Kategorien anpasst, die in den Vortrainingsdaten nicht vorhanden waren.
- Unüberwachtes Lernen: Unsupervised Learning wie Clustering oder Dimensionalitätsreduktion konzentrieren sich auf die Suche nach Mustern oder Strukturen in unbeschrifteten Daten. Das Few-Shot Learning hingegen erfordert gekennzeichnete Beispiele, kann aber mit wenigen gekennzeichneten Daten auf neue Klassen verallgemeinern.
- Reinforcement Learning: Beim Reinforcement Learning wird ein Agent darauf trainiert, aus den Interaktionen mit der Umgebung zu lernen, um die Belohnungen zu maximieren. Few-Shot-Learning kann mit Reinforcement Learning kombiniert werden, um Agenten eine schnelle Anpassung an neue Aufgaben oder Umgebungen mit begrenzten Belohnungsinformationen zu ermöglichen.
- Meta-Lernen: Meta-Lernen, auch bekannt als Lernen für das Lernen, konzentriert sich auf das Erlernen effizienter Lernalgorithmen oder -strategien. Few-Shot Learning kann als eine Form des Meta-Learnings angesehen werden, bei dem das Modell lernt, sich anhand einiger weniger Beispiele schnell an neue Aufgaben oder Kategorien anzupassen.
Im Vergleich dazu geht das few-shot learning auf die Herausforderung ein, mit begrenzten markierten Daten auf neue Klassen oder Aufgaben zu verallgemeinern, was es besonders nützlich in Szenarien macht, in denen die Beschaffung umfangreicher markierter Daten unpraktisch oder teuer ist. Durch die Nutzung des inhärenten Wissens aus wenigen Beispielen ermöglicht das Few-Shot-Lernen den Modellen, genaue Vorhersagen zu treffen und sich effizient an neue Situationen anzupassen.
Wie erstellt man ein Few-Shot Learning Modell in Python?
Beginnen wir mit der Installation der notwendigen Bibliotheken. Wir werden TensorFlow und TensorFlow Addons für dieses Beispiel verwenden. Du kannst diese mit Hilfe von pip installieren:

Nun importieren wir die erforderlichen Bibliotheken und laden den MNIST-Datensatz:

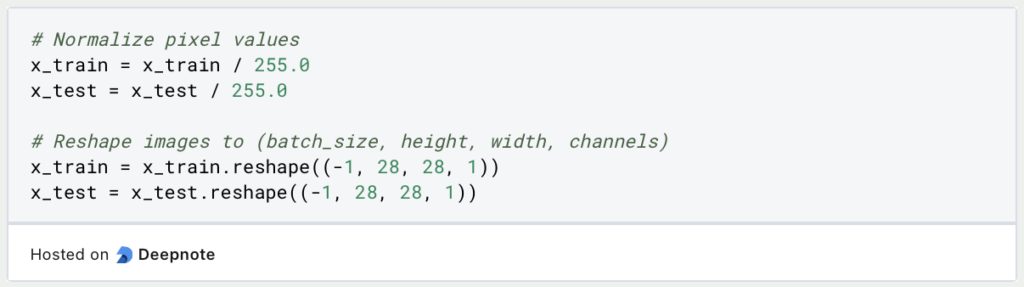
Als Nächstes werden wir den Datensatz vorverarbeiten, indem wir die Pixelwerte normalisieren und die Bilder umgestalten:
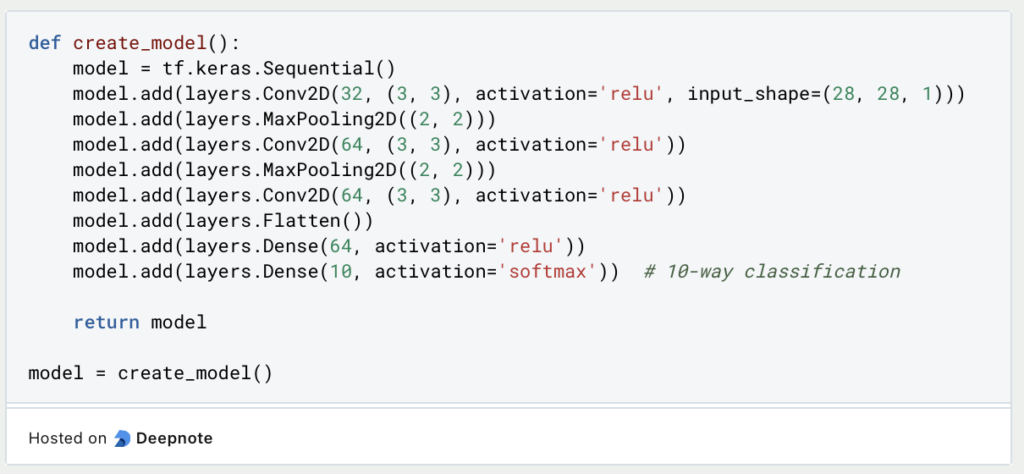
Beim Few-Shot Learning geht es darum, ein Modell so zu trainieren, dass es sich schnell an neue Klassen anpassen und verallgemeinern kann, wobei nur eine begrenzte Anzahl von Trainingsmustern pro Klasse benötigt wird. Die gewählte CNN-Architektur (Convolutional Neural Network) ist aufgrund ihrer Fähigkeit, hierarchische Merkmale aus Bildern zu lernen, für diese Aufgabe gut geeignet.
CNNs zeichnen sich durch die Erfassung lokaler Muster und räumlicher Beziehungen in Bildern aus, wodurch sie selbst bei einer begrenzten Anzahl von Trainingsmustern effektiv relevante Merkmale extrahieren können. Durch den Einsatz mehrerer Faltungsschichten und Pooling-Schichten kann das Modell schrittweise Merkmale auf verschiedenen Granularitätsebenen lernen und abstrahieren. Dank dieser hierarchischen Merkmalsextraktion kann das Modell selbst bei minimalen Trainingsbeispielen gut auf neue Klassen verallgemeinert werden.
Als Nächstes werden wir die Trainingskonfiguration definieren und das Modell kompilieren:

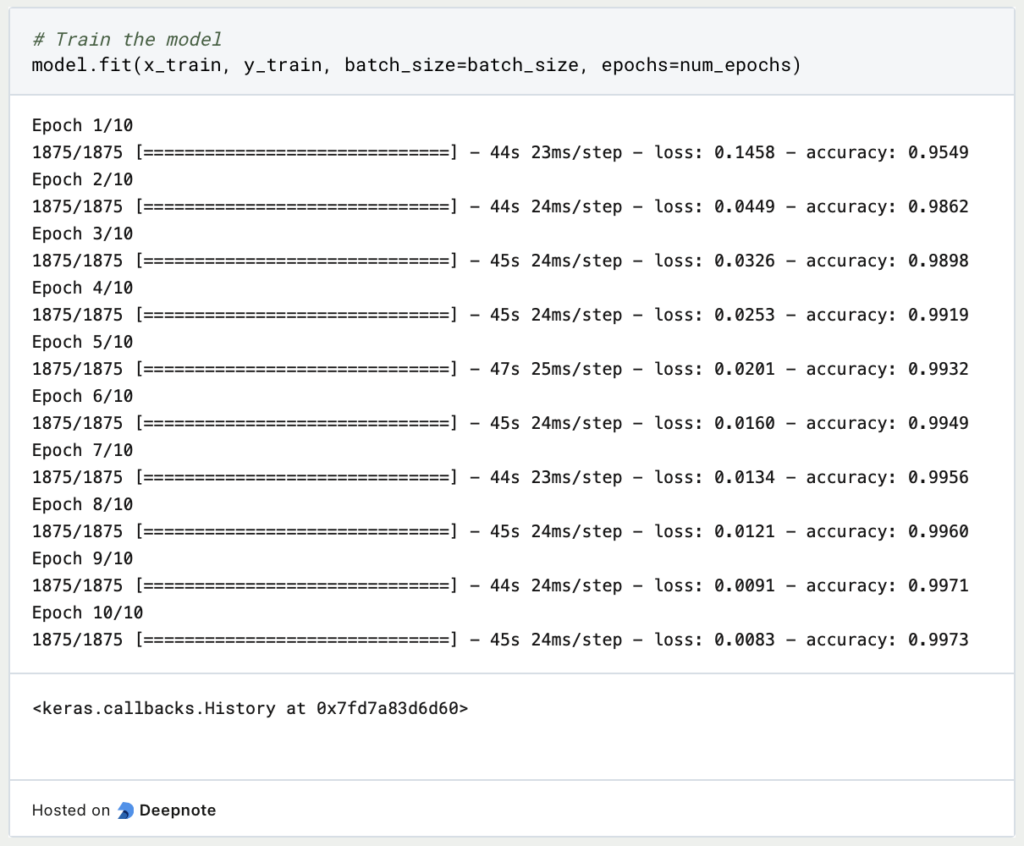
Nun trainieren wir das Modell für diese few-shot learning Aufgabe:
Nach dem Training können wir das Modell anhand der Testmenge bewerten:

Das war’s! Du hast nun mit Python und dem MNIST-Datensatz ein Lernmodell mit wenigen Daten erstellt. Du kannst die Architektur und die Hyperparameter ändern, um mit verschiedenen Modellen und Einstellungen zu experimentieren, oder es anpassen, um es für Deinen spezifischen Datensatz zu verwenden.
Was sind die Anwendungen von Few-Shot Learning?
Few-Shot Learning Modelle finden in den verschiedensten Bereichen Anwendung, was ihre Vielseitigkeit unterstreicht. In den meisten Fällen gibt es nur wenige Beispiele, was die Anwendung von Few-Shot Learning unumgänglich macht.
- Bildklassifizierung: Mit einer begrenzten Anzahl von markierten Beispielen pro Klasse eignet sich das Few-Shot-Learning hervorragend für die genaue Kategorisierung von Bildern, insbesondere in Szenarien mit wenigen Daten.
- Objekterkennung: Diese Lernmethode nutzt eine Handvoll beschrifteter Beispiele und ermöglicht es Modellen, Objekte in Bildern zu identifizieren und zu lokalisieren, selbst bei begrenzten Trainingsdaten.
- Verarbeitung natürlicher Sprache: Aufgaben wie die Klassifizierung von Texten, die Analyse von Gefühlen und die Erkennung benannter Entitäten profitieren vom Lernen mit wenigen Beispielen. Die Modelle passen sich mit nur wenigen Beispielen schnell an neue Kategorien oder Klassen an.
- Medizinische Diagnostik: Few-Shot Learning hilft bei der Diagnose seltener Krankheiten oder spezifischer Patientenzustände, für die es nur wenige markierte Daten gibt. Modelle verallgemeinern aus einer kleinen Menge von Beispielen und ermöglichen so genaue Vorhersagen.
- Empfehlungssysteme: Mit dieser Lernmethode werden personalisierte Empfehlungen möglich, selbst bei begrenzten Daten zur Benutzerinteraktion. Sie ermöglicht effektive Artikel- oder Inhaltsempfehlungen auf der Grundlage von Benutzerpräferenzen.
- Robotik und autonome Systeme: Roboter und autonome Systeme können sich mit Hilfe von few-shot learning schnell an neue Aufgaben oder Umgebungen anpassen. Sie erlernen neue Fähigkeiten und Verhaltensweisen mit minimalen Trainingsdaten.
- Betrugsaufdeckung: Few-Shot-Learning hilft bei der Betrugserkennung, indem es anomale Muster oder Verhaltensweisen bei Finanztransaktionen identifiziert, selbst wenn nur eine begrenzte Anzahl von Betrugsfällen zum Training vorliegt.
Diese Beispiele veranschaulichen die breite Anwendbarkeit des few-shot learning, das sich auf verschiedene Bereiche und Aufgaben erstreckt, in denen begrenzte markierte Daten eine Herausforderung darstellen.
Das solltest Du mitnehmen
- Few-Shot-Learning ist ein leistungsfähiger Ansatz, der die Herausforderung des Lernens aus begrenzten markierten Daten angeht.
- Er ermöglicht es Modellen, zu verallgemeinern und Vorhersagen für unbekannte Klassen oder Aufgaben mit nur wenigen Beispielen zu treffen.
- Few-Shot-Learning findet in verschiedenen Bereichen Anwendung, z. B. in der Computer Vision, der natürlichen Sprachverarbeitung und in Empfehlungssystemen.
- Es bietet eine effizientere und praktikablere Lösung als herkömmliche Lerntechniken, die große Mengen an markierten Daten erfordern.
- Allerdings stößt few-shot learning immer noch an Grenzen, wie z. B. Datenvariabilität, begrenzte Kontextinformationen, Klassenungleichgewicht, Probleme bei der Übertragbarkeit, Empfindlichkeit gegenüber Rauschen und die Notwendigkeit eines aufgabenspezifischen Designs.
- Forscher arbeiten aktiv daran, diese Einschränkungen zu beseitigen, um die Leistung und Anwendbarkeit von few-shot-Lernmethoden zu verbessern.
- Insgesamt birgt das “few-shot learning” großes Potenzial und treibt die Innovation im Bereich des maschinellen Lernens weiter voran, da es Modellen ermöglicht, mit einem Minimum an gelabelten Beispielen zu lernen und sich an neue Aufgaben und Klassen anzupassen.

Was ist eine Boltzmann Maschine?
Die Leistungsfähigkeit von Boltzmann Maschinen freisetzen: Von der Theorie zu Anwendungen im Deep Learning und deren Rolle in der KI.

Was ist die Gini-Unreinheit?
Erforschen Sie die Gini-Unreinheit: Eine wichtige Metrik für die Gestaltung von Entscheidungsbäumen beim maschinellen Lernen.

Was ist die Hesse Matrix?
Erforschen Sie die Hesse Matrix: Ihre Mathematik, Anwendungen in der Optimierung und maschinellen Lernen.

Was ist Early Stopping?
Beherrschen Sie die Kunst des Early Stoppings: Verhindern Sie Overfitting, sparen Sie Ressourcen und optimieren Sie Ihre ML-Modelle.

Was sind Gepulste Neuronale Netze?
Tauchen Sie ein in die Zukunft der KI mit Gepulste Neuronale Netze, die Präzision, Energieeffizienz und bioinspiriertes Lernen neu denken.

Was ist RMSprop?
Meistern Sie die RMSprop-Optimierung für neuronale Netze. Erforschen Sie RMSprop, Mathematik, Anwendungen und Hyperparameter.
Andere Beiträge zum Thema Few-Shot Learning
Ein konkretes Beispiel für das Few-Shot Learning findest Du in diesem Huggingface-Artikel.

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.