Few-shot learning is a subfield of Machine Learning that deals with the problem of learning from a few examples. Traditional Machine Learning algorithms usually require a large amount of labeled data to learn from, but in many real-world scenarios, obtaining such data is impractical or even impossible. Few-shot learning aims to overcome this limitation by learning from only a small number of examples, often as few as one or a few. This makes it possible to apply Machine Learning to tasks such as image classification, natural language processing, and robotics, where labeled data may be scarce or expensive to obtain. In this article, we will explore the concept of few-shot learning, its applications, and the techniques used to implement it.
Which techniques are used in Few-Shot Learning?
Few-shot learning is a captivating field that pushes the boundaries of Machine Learning by enabling models to learn from only a few labeled examples. To achieve this remarkable feat, various techniques and approaches have emerged, each with its own unique advantages. Let’s explore these techniques in more detail:
Meta-Learning stands out as a fascinating approach that focuses on learning to learn. It involves training models to acquire a general learning algorithm that can quickly adapt to new tasks or classes. For example, Model-Agnostic Meta-Learning (MAML) trains models to learn a set of adaptable initial parameters that can be fine-tuned with a few labeled examples from new classes. This meta-learning capability empowers models to rapidly generalize from limited data, making it a powerful technique for few-shot learning.
Metric-Based Methods take a different approach by emphasizing the similarity between samples. These methods aim to learn a distance metric or embedding space where samples from the same class are closer together, while samples from different classes are farther apart. Siamese networks, for instance, use twin networks to learn embeddings for pairs of samples and compute a similarity score based on the distance between the embeddings. Relation Networks focus on learning relation modules to capture pairwise relationships between samples. Matching Networks employ attention mechanisms to compute a weighted sum of embeddings, enabling comparisons between support and query samples. These metric-based methods excel at measuring similarity and discrimination, allowing models to make accurate predictions with limited labeled data.
Generative Models take a creative approach by generating synthetic examples that resemble the labeled ones. This augmentation of the training data helps in mitigating the data scarcity challenge. Generative Adversarial Networks (GANs) are commonly used for this purpose, where a generator network learns to produce realistic samples that fool a discriminator network. Variational Autoencoders (VAEs), on the other hand, learn to encode and decode data, enabling the generation of new samples from the learned latent space. By expanding the available data through generative models, few-shot learning models can better capture the underlying patterns and variations, enhancing their generalization capabilities.
Data Augmentation and Transformation techniques provide another means to enhance few-shot learning. By applying various transformations to existing labeled examples, such as rotations, translations, or distortions, the dataset is augmented, effectively increasing the diversity of available samples. This augmented data enables models to learn from a wider range of variations, enhancing their ability to generalize to unseen classes and scenarios.
Hybrid Approaches combine multiple techniques to leverage their respective strengths and overcome limitations. Researchers often explore combinations of meta-learning, metric-based methods, and generative models to achieve superior few-shot learning performance. These hybrid approaches aim to harness the benefits of each technique, such as the ability to adapt quickly, measure similarity accurately, generate additional samples, and augment the available data.
By diving into these intricate techniques and approaches, we unravel the fascinating realm of few-shot learning. Researchers and practitioners continuously strive to innovate and refine these methods, pushing the boundaries of what machines can achieve with limited labeled data. As we unlock the true potential of few-shot learning, we open doors to applications in areas such as computer vision, natural language processing, and personalized recommendation systems, where adapting quickly to new classes is crucial.
What are the limitations of Few-Shot Learning?
Few-shot learning has shown promising results in addressing the challenge of learning from limited labeled data. However, it is important to consider the limitations associated with this approach.
- Data Variability: Few-shot learning relies on the assumption that the few labeled examples provided during training are representative of the entire class or category. However, if the available examples are not diverse enough or do not capture the full range of variations within the class, the model may struggle to generalize well to unseen instances.
- Limited Contextual Information: This learning method often lacks the rich contextual information that can be obtained from a larger dataset. This can impact the model’s ability to understand complex patterns or dependencies within the data, leading to reduced performance on more challenging tasks.
- Class Imbalance: In few-shot learning scenarios, the number of labeled examples per class is typically small, resulting in class imbalance. This imbalance can make it challenging for the model to learn effectively, as it may overemphasize the dominant classes and struggle to generalize well to the minority classes.
- Transferability: While few-shot learning models excel at adapting to new classes within a known domain, they may struggle when confronted with entirely new domains or tasks that differ significantly from the training data distribution. The ability to transfer knowledge and generalize effectively in such cases remains a challenge.
- Sensitivity to Noise: With limited training examples, the models can be sensitive to noisy or erroneous labels. Noise in the few available labeled examples can have a significant impact on model performance, potentially leading to incorrect predictions or reduced generalization ability.
- Need for Task-Specific Design: Few-shot learning approaches often require careful design and engineering of model architectures, algorithms, and training protocols. Tailoring these techniques to specific tasks or domains may be necessary, making them less straightforward to apply out-of-the-box in diverse scenarios.
While few-shot learning has made significant progress in tackling the data scarcity challenge, it is important to acknowledge its limitations. Addressing these limitations and developing more robust and scalable few-shot learning methods remains an active area of research in Machine Learning and AI.
How does Few-Shot Learning compare to other learning techniques?
Few-shot learning is a unique learning technique that differs from traditional machine learning approaches in several ways. Here is a section comparing few-shot learning to other learning techniques:
- Supervised Learning: In supervised learning, a model is trained on a large labeled dataset to make predictions on unseen data. It requires a substantial amount of labeled data for each class or category. In contrast, few-shot learning aims to perform well with only a few labeled examples per class, making it more suitable for scenarios with limited labeled data.
- Transfer Learning: Transfer learning involves pre-training a model on a large dataset and then fine-tuning it for a specific task with a smaller labeled dataset. While transfer learning is effective when the target task has a similar distribution as the pre-training data, few-shot learning goes a step further by adapting to new classes or categories that were not present in the pre-training data.
- Unsupervised Learning: Unsupervised learning techniques such as clustering or dimensionality reduction focus on finding patterns or structures in unlabeled data. Few-shot learning, on the other hand, requires labeled examples but can generalize to new classes with limited labeled data.
- Reinforcement Learning: Reinforcement learning involves training an agent to learn from interactions with an environment to maximize rewards. Few-shot learning can be combined with reinforcement learning to enable agents to quickly adapt to new tasks or environments with limited reward information.
- Meta-Learning: Meta-learning, also known as learning to learn, focuses on learning efficient learning algorithms or strategies. Few-shot learning can be seen as a form of meta-learning, where the model learns to adapt to new tasks or categories quickly based on a few examples.
Comparatively, few-shot learning addresses the challenge of generalizing to new classes or tasks with limited labeled data, making it particularly useful in scenarios where acquiring abundant labeled data is impractical or expensive. By leveraging the inherent knowledge from a few examples, few-shot learning enables models to make accurate predictions and adapt to new situations efficiently.
How do you build a Few-Shot Learning model in Python?
Let’s start by installing the necessary libraries. We’ll be using TensorFlow and TensorFlow Addons for this example. You can install them using pip:

Now, let’s import the required libraries and load the MNIST dataset:

Next, we’ll preprocess the dataset by normalizing the pixel values and reshaping the images:
Few-shot learning involves training a model to quickly adapt and generalize to new classes with only a limited number of training samples per class. The chosen Convolutional Neural Network (CNN) architecture is well-suited for this task due to its ability to learn hierarchical features from images.
CNNs excel at capturing local patterns and spatial relationships in images, making them effective at extracting relevant features even with limited training samples. By using multiple convolutional and pooling layers, the model can progressively learn and abstract features at different levels of granularity. This hierarchical feature extraction enables the model to generalize well to new classes, even with minimal training examples.
Next, we’ll define the training configuration and compile the model:

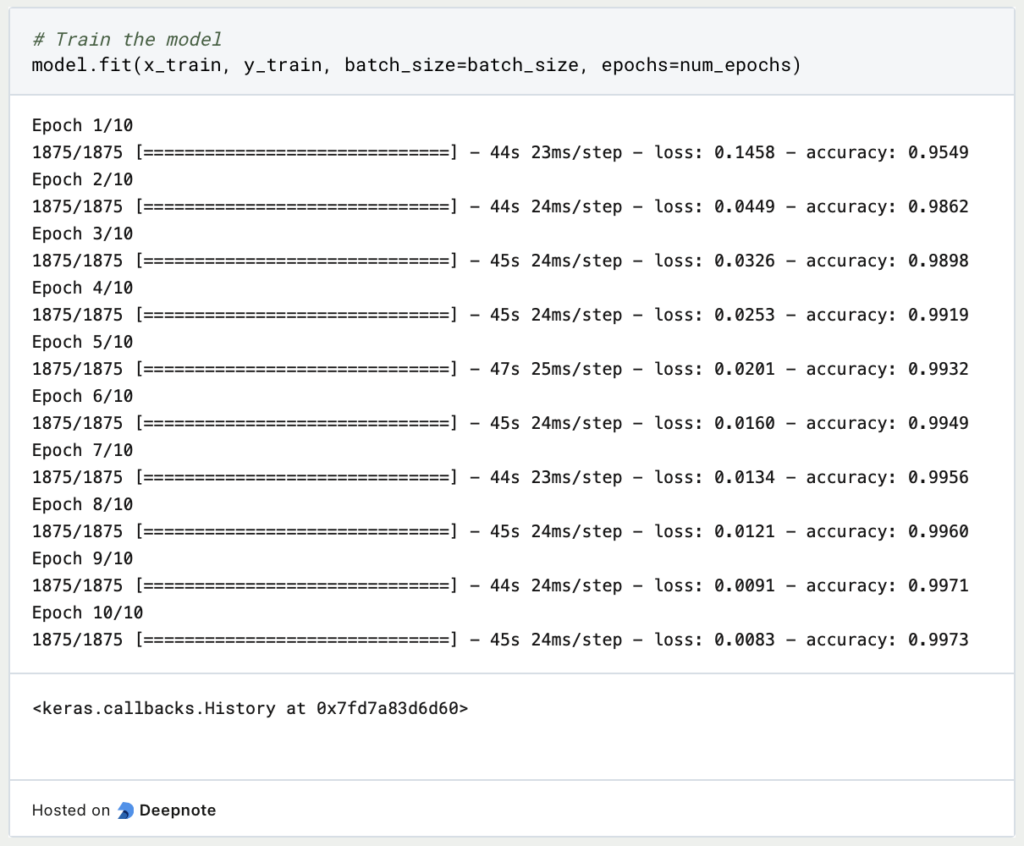
Now, let’s train the model on the few-shot learning task:
After training, we can evaluate the model on the test set:

That’s it! You have now built a few-shot learning model using Python and the MNIST dataset. You can modify the architecture and hyperparameters to experiment with different models and settings or can adapt it to use it on your specific dataset.
What are the applications of Few-Shot Learning?
Few-shot learning models find applications across diverse domains, showcasing their versatility. In most cases, there are only a few examples which makes the application of Few-Shot Learning inevitable.
- Image Classification: With a limited number of labeled examples per class, few-shot learning excels in accurately categorizing images, especially in data-scarce scenarios.
- Object Detection: Leveraging a handful of labeled examples, this learning method enables models to identify and localize objects in images, even with limited training data.
- Natural Language Processing: Tasks like text classification, sentiment analysis, and named entity recognition benefit from few-shot learning. Models adapt quickly to new categories or classes with just a few examples.
- Medical Diagnosis: Few-shot learning aids in diagnosing rare diseases or specific patient conditions where labeled data is scarce. Models generalize from a small set of examples, enabling accurate predictions.
- Recommendation Systems: Personalized recommendations become feasible with this learning method, even with limited user interaction data. It powers effective item or content recommendations based on user preferences.
- Robotics and Autonomous Systems: Robots and autonomous systems can swiftly adapt to new tasks or environments using few-shot learning. They acquire new skills and behaviors with minimal training data.
- Fraud Detection: Few-shot learning aids in fraud detection by identifying anomalous patterns or behaviors in financial transactions, even with a limited number of fraudulent cases for training.
These examples illustrate the broad applicability of few-shot learning, which extends to various domains and tasks where limited labeled data poses a challenge.
This is what you should take with you
- Few-shot learning is a powerful approach that addresses the challenge of learning from limited labeled data.
- It enables models to generalize and make predictions on unseen classes or tasks with only a few examples.
- Few-shot learning has applications in various domains, including computer vision, natural language processing, and recommendation systems.
- It offers a more efficient and practical solution compared to traditional learning techniques that require large amounts of labeled data.
- However, few-shot learning still faces limitations such as data variability, limited contextual information, class imbalance, transferability challenges, sensitivity to noise, and the need for task-specific design.
- Researchers are actively working on addressing these limitations to improve the performance and applicability of few-shot learning methods.
- Overall, few-shot learning holds great potential and continues to drive innovation in the field of machine learning, enabling models to learn and adapt to new tasks and classes with minimal labeled examples.

What is blockchain-based AI?
Discover the potential of Blockchain-Based AI in this insightful article on Artificial Intelligence and Distributed Ledger Technology.

What is Boosting?
Boosting: An ensemble technique to improve model performance. Learn boosting algorithms like AdaBoost, XGBoost & more in our article.

What is Feature Engineering?
Master the Art of Feature Engineering: Boost Model Performance and Accuracy with Data Transformations - Expert Tips and Techniques.

What are N-grams?
Unlocking NLP's Power: Explore n-grams in text analysis, language modeling, and more. Understand the significance of n-grams in NLP.

What is the No-Free-Lunch Theorem?
Unlocking No-Free-Lunch Theorem: Implications & Applications in ML & Optimization

What is Automated Data Labeling?
Unlock efficiency in machine learning with automated data labeling. Explore benefits, techniques, and tools for streamlined data preparation.
Other Articles on the Topic of Few-Shot Learning
You can find a concrete example of few-shot learning in this Huggingface article.

Niklas Lang
I have been working as a machine learning engineer and software developer since 2020 and am passionate about the world of data, algorithms and software development. In addition to my work in the field, I teach at several German universities, including the IU International University of Applied Sciences and the Baden-Württemberg Cooperative State University, in the fields of data science, mathematics and business analytics.
My goal is to present complex topics such as statistics and machine learning in a way that makes them not only understandable, but also exciting and tangible. I combine practical experience from industry with sound theoretical foundations to prepare my students in the best possible way for the challenges of the data world.