Apache Kafka ist eine Open-Source Event-Streaming-Plattform, die es Unternehmen ermöglicht Echtzeitdatenströme aufzubauen und Daten zu speichern. Es wurde im Jahr 2011 bei LinkedIn entwickelt und anschließend als Open-Source bereitgestellt. Seitdem hat sich die Nutzung von Kafka als Event-Streaming-Lösung stark verbreitet.
Wie ist Kafka aufgebaut?
Apache Kafka ist als ein Computercluster aufgebaut, welches aus Servern und Clients besteht.
Die Server, oder sogenannten Broker, schreiben Daten mit Timestamps in die Topics, wodurch die Datenströme entstehen. In einem Cluster kann es verschiedene Topics geben, die sich durch den Themenbezug trennen lassen. In einem Unternehmen könnte es beispielsweise ein Topic mit Daten aus der Produktion und wiederum ein Topic für die Daten aus dem Vertrieb. Der sogenannte Broker speichert diese Nachrichten und kann sie auch im Cluster verteilen, um die Last gleichmäßiger zu aufzuteilen.
Das schreibende System im Kafka Umfeld nennt sich Producer. Als Gegenstück dazu gibt es die sogenannten Consumer, die die Datenströme auslesen und die Daten verarbeiten, indem sie beispielsweise gespeichert werden. Beim Lesen gibt es eine Besonderheit, die Kafka auszeichnet: Der Consumer muss nämlich nicht die ganze Zeit die Nachrichten mitlesen, sondern kann auch nur zu bestimmten Zeitpunkten gerufen werden. Die Intervalle sind abhängig von der Datenaktualität, die die Anwendung benötigt.
Damit der Consumer auch wirklich alle Nachrichten liest, sind die Messages “durchnummeriert” mit dem sogenannten Offset, also einer Ganzzahl die bei der ersten Nachricht startet und bei der aktuellsten aufhört. Wenn wir einen Consumer aufsetzen, “abonniert” er das Topic und merkt sich den frühesten, verfügbaren Offset. Nachdem er eine Nachricht verarbeitet hat, speichert er sich ab, welche Nachrichtenoffsets er schon gelasen hat und kann beim nächsten Starten genau dort weitermachen, wo er das letzte Mal aufgehört hat.
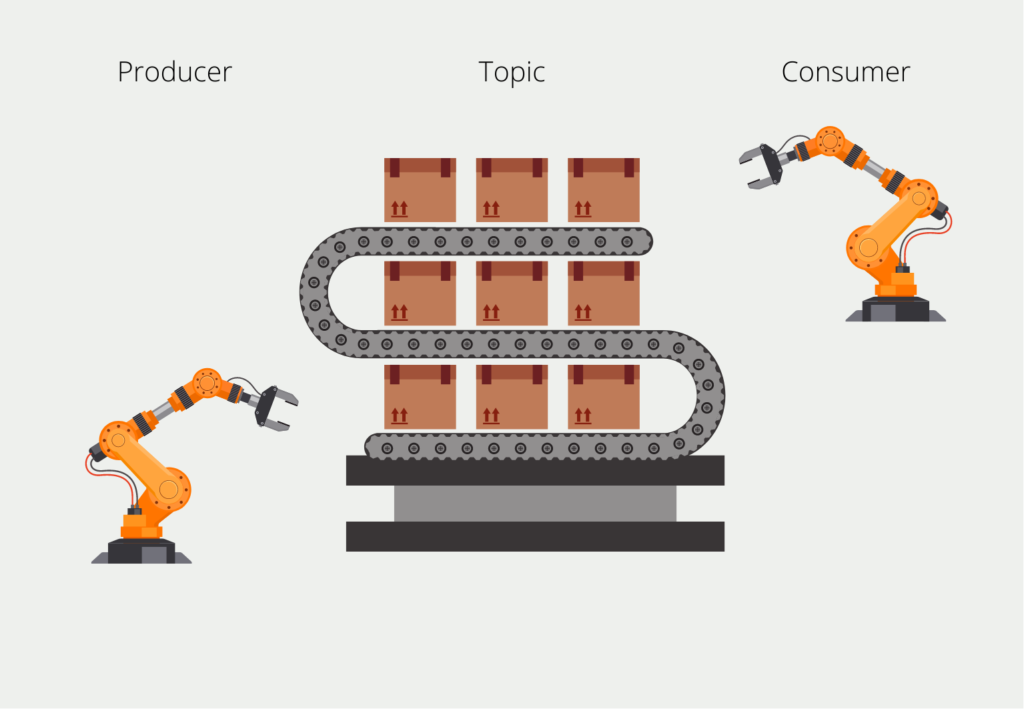
Das ermöglicht beispielsweise eine Funktionalität in der wir den Consumer jede volle Stunde für zehn Minuten laufen lassen. Dann registriert er, dass zehn Nachrichten noch nicht verarbeitet wurden und er liest diese zehn Nachrichten aus und setzt seinen eigenen Offset gleich mit dem der letzten Nachricht. In der darauffolgenden Stunde kann der Consumer dann wieder feststellen, wie viele neue Messages dazugekommen sind und diese nacheinander verarbeiten.
Ein Topic kann zusätzlich noch in sogenannte Partitionen unterteilt werden, wodurch die Verarbeitung parallelisiert werden kann, da die Partitionen auf verschiedenen Rechnern abgelegt werden. Dadurch können auch mehrere Personen gleichzeitig auf ein Topic zugreifen und der Gesamtspeicherplatz für ein Topic lässt sich einfacher skalieren.
Welche APIs werden genutzt?
Apache Kafka bietet mehrere APIs, die es Entwicklern ermöglichen, mit dem Kafka-Nachrichtensystem zu interagieren. Mit diesen APIs können Benutzer Nachrichten von Kafka-Themen erzeugen und konsumieren, Verbrauchergruppen verwalten und Kafka-Cluster überwachen.
Hier sind die wichtigsten Kafka-APIs:
- Producer-API: Diese API ermöglicht es Entwicklern, Nachrichten in Kafka-Themen zu veröffentlichen. Mit dieser API können Benutzer Nachrichten an Kafka-Broker senden und das Thema und die Partition angeben, an die die Nachricht gesendet werden soll.
- Consumer-API: Diese Schnittstelle ermöglicht es Entwicklern, Nachrichten aus Kafka-Topics zu lesen. Mit dieser API können Benutzer Kafka-Themen abonnieren und Nachrichten von Kafka-Brokern empfangen.
- Streams-API: Diese API ermöglicht es Benutzern, Daten in Echtzeit zu verarbeiten und zu analysieren, indem Kafka-Themen in Streams umgewandelt werden. Diese API ist nützlich für den Aufbau von Echtzeit-Datenpipelines und Stream-Verarbeitungsanwendungen.
- Connect-API: Diese API wird für die Integration von Kafka mit externen Systemen wie Datenbanken, Nachrichtenwarteschlangen und Dateisystemen verwendet. Sie bietet Konnektoren, die zum Importieren oder Exportieren von Daten aus Kafka-Themen verwendet werden können.
- Admin-API: Diese API wird für die Verwaltung von Kafka-Clustern und -Themen verwendet. Mit dieser API können Benutzer Kafka-Themen erstellen, löschen und ändern und auch Kafka-Broker, Verbrauchergruppen und ACLs verwalten.
Insgesamt bieten die Kafka-APIs eine flexible und leistungsstarke Möglichkeit, mit dem Kafka-Messaging-System zu interagieren und robuste, skalierbare und Echtzeit-Datenverarbeitungsanwendungen zu erstellen.
Welche Möglichkeiten bietet Apache Kafka?
Apache Kafka bietet zwei verschiedene Arten von Topics, nämlich “Normal” und “Compacted ” Topics. Normale Topics haben eine maximale Speichergröße und manchmal auch zusätzlich einen gewissen Zeitraum in dem Daten gespeichert werden. Wenn die Speichermenge erreicht ist, werden die ältesten Events, also die mit dem geringsten Offset, gelöscht um Platz für neue Events zu schaffen.
Bei den Compacted Topics ist das anders. Diese haben nämlich weder eine zeitliche noch eine Speicherplatz-Beschränkung. Somit sind sie ähnlich zu sehen wie eine Datenbank, da die Daten vorgehalten werden. Aufgrund dieser Compact Topics nutzen bereits einige Unternehmen, wie beispielsweise Uber, Kafka als Data Lake. Über die zusätzliche Funktionalität KSQL lässt sich dabei auch der komplette Datenstrom mithilfe von SQL abfragen.
Mit welchen Tools kann man Kafka kombinieren?
Apache Kafka ist eine leistungsstarke verteilte Streaming-Plattform, mit der sich große Datenmengen in Echtzeit verarbeiten lassen. Sie kann auch mit verschiedenen anderen Technologien und Tools integriert werden, um eine End-to-End-Lösung für die Datenverarbeitung und -analyse zu bieten. Hier sind einige der beliebtesten Tools und Technologien, die mit Kafka verwendet werden können:
- Apache Spark: Apache Kafka kann mit Apache Spark integriert werden, um eine leistungsstarke Streaming-Analyseplattform zu schaffen. Spark kann Daten aus dem Stream lesen, Datentransformationen durchführen und die Ergebnisse zur weiteren Verarbeitung oder Speicherung zurück nach Kafka schreiben.
- Hadoop: Es kann mit Hadoop integriert werden, um eine skalierbare Datenverarbeitungspipeline zu erstellen. Kafka kann als Datenquelle für Hadoop-Aufträge dienen, und Hadoop kann die Ergebnisse zur weiteren Verarbeitung oder Speicherung zurück nach Kafka schreiben.
- Cassandra: Kafka kann mit Apache Cassandra integriert werden, um eine skalierbare Echtzeit-Datenverarbeitungsplattform zu schaffen. Kafka kann als Datenquelle für Cassandra dienen, und Cassandra kann die Ergebnisse zur weiteren Analyse speichern.
- Elasticsearch: Das Streaming Tool kann mit Elasticsearch integriert werden, um eine skalierbare Suchplattform in Echtzeit zu schaffen. Kafka kann als Datenquelle für Elasticsearch dienen, und Elasticsearch kann die Daten für eine schnelle Suche und Abfrage indizieren.
- Flume: Kafka kann in Apache Flume integriert werden, um eine skalierbare Datenerfassungs- und -eingabepipeline zu erstellen. Flume kann Daten aus verschiedenen Quellen lesen und sie zur weiteren Verarbeitung oder Speicherung in Kafka schreiben.
- Sturm: Kafka kann mit Apache Storm integriert werden, um eine verteilte Echtzeit-Datenverarbeitungsplattform zu schaffen. Storm kann Daten aus Kafka lesen, Datenumwandlungen durchführen und die Ergebnisse zur weiteren Verarbeitung oder Speicherung zurück nach Kafka schreiben.
- Flink: Kafka kann mit Apache Flink integriert werden, um eine skalierbare, fehlertolerante Datenverarbeitungsplattform zu schaffen. Flink kann Daten aus Kafka lesen, Datenumwandlungen durchführen und die Ergebnisse zur weiteren Verarbeitung oder Speicherung zurück nach Kafka schreiben.
Insgesamt macht die Fähigkeit zur Integration mit verschiedenen Tools und Technologien Kafka zu einer vielseitigen und leistungsstarken Plattform für die Verarbeitung großer Datenströme in Echtzeit.
Welche Anwendungen lassen sich mit Kafka umsetzen?
Kafka wird eingesetzt, um Echtzeitdatenströme aufzubauen und zu analysieren. Somit können damit Anwendungen umgesetzt werden, bei denen die Datenaktualität eine immense Rolle spielt. Dazu zählen unter anderem:
- Überwachung von Produktionslinien
- Analyse von Website Tracking Daten in Echtzeit
- Zusammenführen von Daten aus verschiedenen Quellen
- Change Data Capturing aus Datenbanken, um Änderungen zu erkennen
Zusätzlich rückt auch Machine Learning immer mehr in den Fokus von Apache Kafka Anwendungen. Auf einer E-Commerce Website laufen viele ML-Modelle, deren Ergebnisse in Echtzeit zur Verfügung stehen müssen. Diese Websites verfügen beispielsweise über eine Recommendation, bei der dem Kunden passende Produkte vorgeschlagen werden sollen, abhängig von seiner bisherigen Journey.
Somit benötigt das Modell in Echtzeit die bisherigen Events, um eine Berechnung starten zu können. Die Website wiederum benötigt das Ergebnis des Modells so schnell wie möglich, um dem Kunden die gefundenen Produkte anzeigen zu können. Für diese beiden Datenströme bietet sich die Nutzung von Apache Kafka an.
Welche Vorteile bietet die Nutzung von Apache Kafka?
Die weite Verbreitung von Kafka ist unter anderem auf diese Vorteile zurückzuführen:
- Skalierbarkeit: Durch die Architektur mit Topics und Partitionen ist Kafka in vielen Punkten wie Speicherplatz oder Performance horizontal skalierbar.
- Möglichkeit der Datenspeicherung: Die Nutzung von Compacted Streams bieten die Möglichkeit auch dauerhaft Daten zu speichern.
- Einfache Nutzung: Das Konzept von Producern und Consumern ist einfach zu verstehen und umzusetzen.
- Schnelle Verarbeitung: In Echtzeit Anwendungen sind nicht nur der schnelle Transport von Daten von großer Bedeutung, sondern auch die schnelle Verarbeitung. Apache Kafka bietet mit der sogenannten Streaming API eine einfache Möglichkeit zur Verarbeitung von Echtzeitdaten.
Das solltest Du mitnehmen
- Apache Kafka ist eine Open-Source Event-Streaming-Plattform, die es Unternehmen ermöglicht Echtzeitdatenströme aufzubauen und die Daten zu speichern.
- Kurz gesagt schreiben Producer ihre Daten in sogenannte Topics, die von den Consumern ausgelesen werden können.
- In den Topics werden die ältesten Daten gelöscht, sobald eine gewisse Speichermenge erreicht wurde. Bei Compacted Topics werden die Informationen nie gelöscht. Sie eignen sich deshalb zur langfristigen Datenspeicherung.
- Apache Kafka ist vor allem aufgrund der einfachen Nutzung und der Skalierbarkeit bei Anwendern sehr beliebt.

Was ist die Univariate Analyse?
Univariate Analyse beherrschen: Mit Visualisierung und Python tief in Daten eintauchen - Lernen Sie anhand von praktischem Code.

Was ist OpenAPI?
Erkunden Sie OpenAPI: Ein Leitfaden zum Aufbau und zur Nutzung von RESTful APIs. Lernen Sie, wie man APIs entwirft und dokumentiert.

Was ist Data Governance?
Sichern Sie die Qualität, Verfügbarkeit und Integrität der Daten Ihres Unternehmens durch effektives Data Governance. Erfahren Sie mehr.

Was ist Datenqualität?
Sicherstellung der Datenqualität: Bedeutung, Herausforderungen und bewährte Praktiken. Erfahren Sie, wie Sie hochwertige Daten erhalten.

Was ist die Datenimputation?
Imputieren Sie fehlende Werte mit Datenimputationstechniken. Optimieren Sie die Datenqualität und erfahren Sie mehr über die Techniken.

Was ist Ausreißererkennung?
Entdecken Sie Anomalien in Daten mit Verfahren zur Ausreißererkennung. Verbessern Sie ihre Entscheidungsfindung!
Andere Beiträge zum Thema Apache Kafka

Niklas Lang
Seit 2020 bin ich als Machine Learning Engineer und Softwareentwickler tätig und beschäftige mich leidenschaftlich mit der Welt der Daten, Algorithmen und Softwareentwicklung. Neben meiner Arbeit in der Praxis unterrichte ich an mehreren deutschen Hochschulen, darunter die IU International University of Applied Sciences und die Duale Hochschule Baden-Württemberg, in den Bereichen Data Science, Mathematik und Business Analytics.
Mein Ziel ist es, komplexe Themen wie Statistik und maschinelles Lernen so aufzubereiten, dass sie nicht nur verständlich, sondern auch spannend und greifbar werden. Dabei kombiniere ich praktische Erfahrungen aus der Industrie mit fundierten theoretischen Grundlagen, um meine Studierenden bestmöglich auf die Herausforderungen der Datenwelt vorzubereiten.